Итак, вы решили сделать новый проект. И проект этот — веб-приложение. Сколько времени уйдёт на создание базового прототипа? Насколько это сложно? Что должен уже со старта уметь современный веб-сайт?
В этой статье мы попробуем набросать boilerplate простейшего веб-приложения со следующей архитектурой:

Что мы покроем:
- настройка dev-окружения в docker-compose.
- создание бэкенда на Flask.
- создание фронтенда на Express.
- сборка JS с помощью Webpack.
- React, Redux и server side rendering.
- очереди задач с RQ.
Введение
Перед разработкой, конечно, сперва нужно определиться, что мы разрабатываем! В качестве модельного приложения для этой статьи я решил сделать примитивный wiki-движок. У нас будут карточки, оформленные в Markdown; их можно будет смотреть и (когда-нибудь в будущем) предлагать правки. Всё это мы оформим в виде одностраничного приложения с server-side rendering (что совершенно необходимо для индексации наших будущих терабайт контента).
Давайте чуть подробнее пройдёмся по компонентам, которые нам для этого понадобятся:
- Клиент. Сделаем одностраничное приложение (т.е. с переходами между страницами посредством AJAX) на весьма распространённой в мире фронтенда связке React+Redux.
- Фронтенд. Сделаем простенький сервер на Express, который будет рендерить наше React-приложение (запрашивая все необходимые данные в бэкенде асинхронно) и выдавать пользователю.
- Бэкенд. Повелитель бизнес-логики, наш бэкенд будет небольшим Flask-приложением. Данные (наши карточки) будем хранить в популярном документном хранилище MongoDB, а для очереди задач и, возможно, в будущем — кэширования будем использовать Redis.
- Воркер. Отдельный контейнер для тяжёлых задач у нас будет запускаться библиотечкой RQ.
Инфраструктура: git
Наверное, про это можно было и не говорить, но, конечно, мы будем вести разработку в git-репозитории.
git init
git remote add origin git@github.com:Saluev/habr-app-demo.git
git commit --allow-empty -m "Initial commit"
git push
(Здесь же стоит сразу наполнить .gitignore.)
Итоговый проект можно посмотреть на Github. Каждой секции статьи соответствует один коммит (я немало ребейзил, чтобы добиться этого!).
Инфраструктура: docker-compose
Начнём с настройки окружения. При том изобилии компонент, которое у нас имеется, весьма логичным решением для разработки будет использование docker-compose.
Добавим в репозиторий файл docker-compose.yml следующего содержания:
version: '3'
services:
mongo:
image: "mongo:latest"
redis:
image: "redis:alpine"
backend:
build:
context: .
dockerfile: ./docker/backend/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
ports:
- "40001:40001"
volumes:
- .:/code
frontend:
build:
context: .
dockerfile: ./docker/frontend/Dockerfile
environment:
- APP_ENV=dev
- APP_BACKEND_URL=backend:40001
- APP_FRONTEND_PORT=40002
depends_on:
- backend
ports:
- "40002:40002"
volumes:
- ./frontend:/app/src
worker:
build:
context: .
dockerfile: ./docker/worker/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
volumes:
- .:/code
Давайте разберём вкратце, что тут происходит.
- Создаётся контейнер MongoDB и контейнер Redis.
- Создаётся контейнер нашего бэкенда (который мы опишем чуть ниже). В него передаётся переменная окружения APP_ENV=dev (мы будем смотреть на неё, чтобы понять, какие настройки Flask загружать), и открывается наружу его порт 40001 (через него в API будет ходить наш браузерный клиент).
- Создаётся контейнер нашего фронтенда. В него тоже прокидываются разнообразные переменные окружения, которые нам потом пригодятся, и открывается порт 40002. Это основной порт нашего веб-приложения: в браузере мы будем заходить на http://localhost:40002.
- Создаётся контейнер нашего воркера. Ему внешние порты не нужны, а нужен только доступ в MongoDB и Redis.
Теперь давайте создадим докерфайлы. Прямо сейчас на Хабре выходит серия переводов прекрасных статей про Docker — за всеми подробностями можно смело обращаться туда.
Начнём с бэкенда.
# docker/backend/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD gunicorn -w 1 -b 0.0.0.0:40001 --worker-class gevent backend.server:app
Подразумевается, что мы запускаем через gunicorn Flask-приложение, скрывающееся под именем app в модуле backend.server.
Не менее важный docker/backend/.dockerignore:
.git
.idea
.logs
.pytest_cache
frontend
tests
venv
*.pyc
*.pyo
Воркер в целом аналогичен бэкенду, только вместо gunicorn у нас обычный запуск питонячьего модуля:
# docker/worker/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD python -m worker
Мы сделаем всю работу в worker/__main__.py.
.dockerignore воркера полностью аналогичен .dockerignore бэкенда.
Наконец, фронтенд. Про него на Хабре есть целая отдельная статья, но, судя по развернутой дискуссии на StackOverflow и комментариям в духе «Ребят, уже 2018, нормального решения всё ещё нет?» там всё не так просто. Я остановился на таком варианте докерфайла.
# docker/frontend/Dockerfile
FROM node:carbon
WORKDIR /app
# Копируем package.json и package-lock.json и делаем npm install, чтобы зависимости закешировались.
COPY frontend/package*.json ./
RUN npm install
# Наши исходники мы примонтируем в другую папку,
# так что надо задать PATH.
ENV PATH /app/node_modules/.bin:$PATH
# Финальный слой содержит билд нашего приложения.
ADD frontend /app/src
WORKDIR /app/src
RUN npm run build
CMD npm run start
Плюсы:
- всё кешируется как ожидается (на нижнем слое — зависимости, на верхнем — билд нашего приложения);
docker-compose exec frontend npm install --save newDependencyотрабатывает как надо и модифицируетpackage.jsonв нашем репозитории (что было бы не так, если бы мы использовали COPY, как многие предлагают). Запускать простоnpm install --save newDependencyвне контейнера в любом случае было бы нежелательно, потому что некоторые зависимости нового пакета могут уже присутствовать и при этом быть собраны под другую платформу (под ту, которая внутри докера, а не под наш рабочий макбук, например), а ещё мы вообще не хотим требовать присутствия Node на разработческой машине. Один Docker, чтобы править ими всеми!
Ну и, конечно, docker/frontend/.dockerignore:
.git
.idea
.logs
.pytest_cache
backend
worker
tools
node_modules
npm-debug
tests
venv
Итак, наш каркас из контейнеров готов и можно наполнять его содержимым!
Бэкенд: каркас на Flask
Добавим flask, flask-cors, gevent и gunicorn в requirements.txt и создадим в backend/server.py простенький Flask application.
# backend/server.py
import os.path
import flask
import flask_cors
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# CORS позволит нашему фронтенду делать запросы к нашему
# бэкенду несмотря на то, что они на разных хостах
# (добавит заголовок Access-Control-Origin в респонсы).
# Подтюним его когда-нибудь потом.
flask_cors.CORS(self)
app = HabrAppDemo("habr-app-demo")
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
app.config.from_object(f"backend.{env}_settings")
Мы указали Flask подтягивать настройки из файла backend.{env}_settings, а значит, нам также потребуется создать (хотя бы пустой) файл backend/dev_settings.py, чтобы всё взлетело.
Теперь наш бэкенд мы можем официально ПОДНЯТЬ!
habr-app-demo$ docker-compose up backend
...
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Starting gunicorn 19.9.0
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Listening at: http://0.0.0.0:40001 (6)
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Using worker: gevent
backend_1 | [2019-02-23 10:09:03 +0000] [9] [INFO] Booting worker with pid: 9
Двигаемся дальше.
Фронтенд: каркас на Express
Начнём с создания пакета. Создав папку frontend и запустив в ней npm init, после нескольких бесхитростных вопросов мы получим готовый package.json в духе
{
"name": "habr-app-demo",
"version": "0.0.1",
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/Saluev/habr-app-demo.git"
},
"author": "Tigran Saluev <tigran@saluev.com>",
"license": "MIT",
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
"homepage": "https://github.com/Saluev/habr-app-demo#readme"
}
В дальнейшем нам вообще не потребуется Node.js на машине разработчика (хотя мы могли и сейчас извернуться и запустить npm init через Docker, ну да ладно).
В Dockerfile мы упомянули npm run build и npm run start — нужно добавить в package.json соответствующие команды:
--- a/frontend/package.json
+++ b/frontend/package.json
@@ -4,6 +4,8 @@
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
+ "build": "echo 'build'",
+ "start": "node index.js",
"test": "echo "Error: no test specified" && exit 1"
},
"repository": {
Команда build пока ничего не делает, но она нам ещё пригодится.
Добавим в зависимости Express и создадим в index.js простое приложение:
--- a/frontend/package.json
+++ b/frontend/package.json
@@ -17,5 +17,8 @@
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
- "homepage": "https://github.com/Saluev/habr-app-demo#readme"
+ "homepage": "https://github.com/Saluev/habr-app-demo#readme",
+ "dependencies": {
+ "express": "^4.16.3"
+ }
}
// frontend/index.js
const express = require("express");
app = express();
app.listen(process.env.APP_FRONTEND_PORT);
app.get("*", (req, res) => {
res.send("Hello, world!")
});
Теперь docker-compose up frontend поднимает наш фронтенд! Более того, на http://localhost:40002 уже должно красоваться классическое “Hello, world”.
Фронтенд: сборка с webpack и React-приложение
Пришло время изобразить в нашем приложении нечто больше, чем plain text. В этой секции мы добавим простейший React-компонент App и настроим сборку.
При программировании на React очень удобно использовать JSX — диалект JavaScript, расширенный синтаксическими конструкциями вида
render() {
return <MyButton color="blue">{this.props.caption}</MyButton>;
}
Однако, JavaScript-движки не понимают его, поэтому обычно во фронтенд добавляется этап сборки. Специальные компиляторы JavaScript (ага-ага) превращают синтаксический сахар в
уродливый
классический JavaScript, обрабатывают импорты, минифицируют и так далее.
2014 год. apt-cache search java
Итак, простейший React-компонент выглядит очень просто.
// frontend/src/components/app.js
import React, {Component} from 'react'
class App extends Component {
render() {
return <h1>Hello, world!</h1>
}
}
export default App
Он просто выведет на экран наше приветствие более убедительным кеглем.
Добавим файл frontend/src/template.js, содержащий минимальный HTML-каркас нашего будущего приложения:
// frontend/src/template.js
export default function template(title) {
let page = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>${title}</title>
</head>
<body>
<div id="app"></div>
<script src="/dist/client.js"></script>
</body>
</html>
`;
return page;
}
Добавим и клиентскую точку входа:
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import App from './components/app'
render(
<App/>,
document.querySelector('#app')
);
Для сборки всей этой красоты нам потребуются:
webpack — модный молодёжный сборщик для JS (хотя я уже три часа не читал статей по фронтенду, так что насчёт моды не уверен);
babel — компилятор для всевозможных примочек вроде JSX, а заодно поставщик полифиллов на все случаи IE.
Если предыдущая итерация фронтенда у вас всё ещё запущена, вам достаточно сделать
docker-compose exec frontend npm install --save
react
react-dom
docker-compose exec frontend npm install --save-dev
webpack
webpack-cli
babel-loader
@babel/core
@babel/polyfill
@babel/preset-env
@babel/preset-react
для установки новых зависимостей. Теперь настроим webpack:
// frontend/webpack.config.js
const path = require("path");
// Конфиг клиента.
clientConfig = {
mode: "development",
entry: {
client: ["./src/client.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, "../dist"),
filename: "[name].js"
},
module: {
rules: [
{ test: /.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
// Конфиг сервера. Обратите внимание на две вещи:
// 1. target: "node" - без этого упадёт уже на import path.
// 2. складываем в .., а не в ../dist -- нечего пользователям
// видеть код нашего сервера, пусть и скомпилированный!
serverConfig = {
mode: "development",
target: "node",
entry: {
server: ["./index.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, ".."),
filename: "[name].js"
},
module: {
rules: [
{ test: /.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
module.exports = [clientConfig, serverConfig];
Чтобы заработал babel, нужно сконфигурировать frontend/.babelrc:
{
"presets": ["@babel/env", "@babel/react"]
}
Наконец, сделаем осмысленной нашу команду npm run build:
// frontend/package.json
...
"scripts": {
"build": "webpack",
"start": "node /app/server.js",
"test": "echo "Error: no test specified" && exit 1"
},
...
Теперь наш клиент вкупе с пачкой полифиллов и всеми своими зависимостями прогоняется через babel, компилируется и складывается в монолитный минифицированный файлик ../dist/client.js. Добавим возможность загрузить его как статический файл в наше Express-приложение, а в дефолтном роуте начнём возвращать наш HTML:
// frontend/index.js
// Теперь, когда мы настроили сборку,
// можно по-человечески импортировать.
import express from 'express'
import template from './src/template'
let app = express();
app.use('/dist', express.static('../dist'));
app.get("*", (req, res) => {
res.send(template("Habr demo app"));
});
app.listen(process.env.APP_FRONTEND_PORT);
Успех! Теперь, если мы запустим docker-compose up --build frontend, мы увидим “Hello, world!” в новой, блестящей обёртке, а если у вас установлено расширение React Developer Tools (Chrome, Firefox) — то ещё и дерево React-компонент в инструментах разработчика:

Бэкенд: данные в MongoDB
Прежде, чем двигаться дальше и вдыхать в наше приложение жизнь, надо сперва её вдохнуть в бэкенд. Кажется, мы собирались хранить размеченные в Markdown карточки — пора это сделать.
В то время, как существуют ORM для MongoDB на питоне, я считаю использование ORM практикой порочной и оставляю изучение соответствующих решений на ваше усмотрение. Вместо этого сделаем простенький класс для карточки и сопутствующий DAO:
# backend/storage/card.py
import abc
from typing import Iterable
class Card(object):
def __init__(self, id: str = None, slug: str = None, name: str = None, markdown: str = None, html: str = None):
self.id = id
self.slug = slug # человекочитаемый идентификатор карточки
self.name = name
self.markdown = markdown
self.html = html
class CardDAO(object, metaclass=abc.ABCMeta):
@abc.abstractmethod
def create(self, card: Card) -> Card:
pass
@abc.abstractmethod
def update(self, card: Card) -> Card:
pass
@abc.abstractmethod
def get_all(self) -> Iterable[Card]:
pass
@abc.abstractmethod
def get_by_id(self, card_id: str) -> Card:
pass
@abc.abstractmethod
def get_by_slug(self, slug: str) -> Card:
pass
class CardNotFound(Exception):
pass
(Если вы до сих пор не используете аннотации типов в Python, обязательно гляньте эти статьи!)
Теперь создадим реализацию интерфейса CardDAO, принимающую на вход объект Database из pymongo (да-да, время добавить pymongo в requirements.txt):
# backend/storage/card_impl.py
from typing import Iterable
import bson
import bson.errors
from pymongo.collection import Collection
from pymongo.database import Database
from backend.storage.card import Card, CardDAO, CardNotFound
class MongoCardDAO(CardDAO):
def __init__(self, mongo_database: Database):
self.mongo_database = mongo_database
# Очевидно, slug должны быть уникальны.
self.collection.create_index("slug", unique=True)
@property
def collection(self) -> Collection:
return self.mongo_database["cards"]
@classmethod
def to_bson(cls, card: Card):
# MongoDB хранит документы в формате BSON. Здесь
# мы должны сконвертировать нашу карточку в BSON-
# сериализуемый объект, что бы в ней ни хранилось.
result = {
k: v
for k, v in card.__dict__.items()
if v is not None
}
if "id" in result:
result["_id"] = bson.ObjectId(result.pop("id"))
return result
@classmethod
def from_bson(cls, document) -> Card:
# С другой стороны, мы хотим абстрагировать весь
# остальной код от того факта, что мы храним карточки
# в монге. Но при этом id будет неизбежно везде
# использоваться, так что сконвертируем-ка его в строку.
document["id"] = str(document.pop("_id"))
return Card(**document)
def create(self, card: Card) -> Card:
card.id = str(self.collection.insert_one(self.to_bson(card)).inserted_id)
return card
def update(self, card: Card) -> Card:
card_id = bson.ObjectId(card.id)
self.collection.update_one({"_id": card_id}, {"$set": self.to_bson(card)})
return card
def get_all(self) -> Iterable[Card]:
for document in self.collection.find():
yield self.from_bson(document)
def get_by_id(self, card_id: str) -> Card:
return self._get_by_query({"_id": bson.ObjectId(card_id)})
def get_by_slug(self, slug: str) -> Card:
return self._get_by_query({"slug": slug})
def _get_by_query(self, query) -> Card:
document = self.collection.find_one(query)
if document is None:
raise CardNotFound()
return self.from_bson(document)
Время прописать конфигурацию монги в настройки бэкенда. Мы незамысловато назвали наш контейнер с монгой mongo, так что MONGO_HOST = "mongo":
--- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -0,0 +1,3 @@
+MONGO_HOST = "mongo"
+MONGO_PORT = 27017
+MONGO_DATABASE = "core"
Теперь надо создать MongoCardDAO и дать Flask-приложению к нему доступ. Хотя сейчас у нас очень простая иерархия объектов (настройки → клиент pymongo → база данных pymongo → MongoCardDAO), давайте сразу создадим централизованный царь-компонент, делающий dependency injection (он пригодится нам снова, когда мы будем делать воркер и tools).
# backend/wiring.py
import os
from pymongo import MongoClient
from pymongo.database import Database
import backend.dev_settings
from backend.storage.card import CardDAO
from backend.storage.card_impl import MongoCardDAO
class Wiring(object):
def __init__(self, env=None):
if env is None:
env = os.environ.get("APP_ENV", "dev")
self.settings = {
"dev": backend.dev_settings,
# (добавьте сюда настройки других
# окружений, когда они появятся!)
}[env]
# С ростом числа компонент этот код будет усложняться.
# В будущем вы можете сделать тут такой DI, какой захотите.
self.mongo_client: MongoClient = MongoClient(
host=self.settings.MONGO_HOST,
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
Время добавить новый роут в Flask-приложение и наслаждаться видом!
# backend/server.py
import os.path
import flask
import flask_cors
from backend.storage.card import CardNotFound
from backend.wiring import Wiring
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
flask_cors.CORS(self)
self.wiring = Wiring(env)
self.route("/api/v1/card/<card_id_or_slug>")(self.card)
def card(self, card_id_or_slug):
try:
card = self.wiring.card_dao.get_by_slug(card_id_or_slug)
except CardNotFound:
try:
card = self.wiring.card_dao.get_by_id(card_id_or_slug)
except (CardNotFound, ValueError):
return flask.abort(404)
return flask.jsonify({
k: v
for k, v in card.__dict__.items()
if v is not None
})
app = HabrAppDemo("habr-app-demo")
app.config.from_object(f"backend.{env}_settings")
Перезапускаем командой docker-compose up --build backend:

Упс… ох, точно. Нам же нужно добавить контент! Заведём папку tools и сложим в неё скриптик, добавляющий одну тестовую карточку:
# tools/add_test_content.py
from backend.storage.card import Card
from backend.wiring import Wiring
wiring = Wiring()
wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
Команда docker-compose exec backend python -m tools.add_test_content наполнит нашу монгу контентом изнутри контейнера с бэкендом.

Успех! Теперь время поддержать это на фронтенде.
Фронтенд: Redux
Теперь мы хотим сделать роут /card/:id_or_slug, по которому будет открываться наше React-приложение, подгружать данные карточки из API и как-нибудь её нам показывать. И здесь начинается, пожалуй, самое сложное, ведь мы хотим, чтобы сервер сразу отдавал нам HTML с содержимым карточки, пригодным для индексации, но при этом чтобы приложение при навигации между карточками получало все данные в виде JSON из API, а страничка не перегружалась. И чтобы всё это — без копипасты!
Начнём с добавления Redux. Redux — JavaScript-библиотека для хранения состояния. Идея в том, чтобы вместо тысячи неявных состояний, изменяемых вашими компонентами при пользовательских действиях и других интересных событиях, иметь одно централизованное состояние, а любое изменение его производить через централизованный механизм действий. Так, если раньше для навигации мы сперва включали гифку загрузки, потом делали запрос через AJAX и, наконец, в success-коллбеке прописывали обновление нужных частей страницы, то в Redux-парадигме нам предлагается отправить действие “изменить контент на гифку с анимацией”, которое изменит глобальное состояние так, что одна из ваших компонент выкинет прежний контент и поставит анимацию, потом сделать запрос, а в его success-коллбеке отправить ещё одно действие, “изменить контент на подгруженный”. В общем, сейчас мы это сами увидим.
Начнём с установки новых зависимостей в наш контейнер.
docker-compose exec frontend npm install --save
redux
react-redux
redux-thunk
redux-devtools-extension
Первое — собственно, Redux, второе — специальная библиотека для скрещивания React и Redux (written by mating experts), третье — очень нужная штука, необходимость который неплохо обоснована в её же README, и, наконец, четвёртое — библиотечка, необходимая для работы Redux DevTools Extension.
Начнём с бойлерплейтного Redux-кода: создания редьюсера, который ничего не делает, и инициализации состояния.
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
return state;
}
// frontend/src/redux/configureStore.js
import {createStore, applyMiddleware} from "redux";
import thunkMiddleware from "redux-thunk";
import {composeWithDevTools} from "redux-devtools-extension";
import rootReducer from "./reducers";
export default function configureStore(initialState) {
return createStore(
rootReducer,
initialState,
composeWithDevTools(applyMiddleware(thunkMiddleware)),
);
}
Наш клиент немного видоизменяется, морально готовясь к работе с Redux:
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
// Нужно создать то самое централизованное хранилище...
const store = configureStore();
render(
// ... и завернуть приложение в специальный компонент,
// умеющий с ним работать
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Теперь мы можем запустить docker-compose up —build frontend, чтобы убедиться, что ничего не сломалось, а в Redux DevTools появилось наше примитивное состояние:

Фронтенд: страница карточки
Прежде, чем сделать страницы с SSR, надо сделать страницы без SSR! Давайте наконец воспользуемся нашим гениальным API для доступа к карточкам и сверстаем страницу карточки на фронтенде.
Время воспользоваться интеллектом и задизайнить структуру нашего состояния. Материалов на эту тему довольно много, так что предлагаю интеллектом не злоупотреблять и остановится на простом. Например, таком:
{
"page": {
"type": "card", // что за страница открыта
// следующие свойства должны быть только при type=card:
"cardSlug": "...", // что за карточка открыта
"isFetching": false, // происходит ли сейчас запрос к API
"cardData": {...}, // данные карточки (если уже получены)
// ...
},
// ...
}
Заведём компонент «карточка», принимающий в качестве props содержимое cardData (оно же — фактически содержимое нашей карточки в mongo):
// frontend/src/components/card.js
import React, {Component} from 'react';
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
render() {
const {name, html} = this.props;
return (
<div>
<h1>{name}</h1>
<!--Да-да, добавить HTML в React не так-то просто!-->
<div dangerouslySetInnerHTML={{__html: html}}/>
</div>
);
}
}
export default Card;
Теперь заведём компонент для всей страницы с карточкой. Он будет ответственен за то, чтобы достать нужные данные из API и передать их в Card. А фетчинг данных мы сделаем React-Redux way.
Для начала создадим файлик frontend/src/redux/actions.js и создадим действие, которые достаёт из API содержимое карточки, если ещё не:
export function fetchCardIfNeeded() {
return (dispatch, getState) => {
let state = getState().page;
if (state.cardData === undefined || state.cardData.slug !== state.cardSlug) {
return dispatch(fetchCard());
}
};
}
Действие fetchCard, которое, собственно, делает фетч, чуть-чуть посложнее:
function fetchCard() {
return (dispatch, getState) => {
// Сперва даём состоянию понять, что мы ждём карточку.
// Наши компоненты после этого могут, например,
// включить характерную анимацию загрузки.
dispatch(startFetchingCard());
// Формируем запрос к API.
let url = apiPath() + "/card/" + getState().page.cardSlug;
// Фетчим, обрабатываем, даём состоянию понять, что
// данные карточки уже доступны. Здесь, конечно, хорошо
// бы добавить обработку ошибок.
return fetch(url)
.then(response => response.json())
.then(json => dispatch(finishFetchingCard(json)));
};
// Кстати, именно redux-thunk позволяет нам
// использовать в качестве действий лямбды.
}
function startFetchingCard() {
return {
type: START_FETCHING_CARD
};
}
function finishFetchingCard(json) {
return {
type: FINISH_FETCHING_CARD,
cardData: json
};
}
function apiPath() {
// Эта функция здесь неспроста. Когда мы сделаем server-side
// rendering, путь к API будет зависеть от окружения - из
// контейнера с фронтендом надо будет стучать не в localhost,
// а в backend.
return "http://localhost:40001/api/v1";
}
Ох, у нас появилось действие, которое ЧТО-ТО ДЕЛАЕТ! Это надо поддержать в редьюсере:
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD
} from "./actions";
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
}
}
return state;
}
(Обратите внимание на сверхмодный синтаксис для клонирования объекта с изменением отдельных полей.)
Теперь, когда вся логика унесена в Redux actions, сама компонента CardPage будет выглядеть сравнительно просто:
// frontend/src/components/cardPage.js
import React, {Component} from 'react';
import {connect} from 'react-redux'
import {fetchCardIfNeeded} from '../redux/actions'
import Card from './card'
class CardPage extends Component {
componentWillMount() {
// Это событие вызывается, когда React собирается
// отрендерить наш компонент. К моменту рендеринга нам уже
// уже желательно знать, показывать ли заглушку "данные
// загружаются" или рисовать карточку, поэтому мы вызываем
// наше царь-действие здесь. Ещё одна причина - этот метод
// вызывается также при рендеринге компонент в HTML функцией
// renderToString, которую мы будем использовать для SSR.
this.props.dispatch(fetchCardIfNeeded())
}
render() {
const {isFetching, cardData} = this.props;
return (
<div>
{isFetching && <h2>Loading...</h2>}
{cardData && <Card {...cardData}/>}
</div>
);
}
}
// Поскольку этой компоненте нужен доступ к состоянию, ей нужно
// его обеспечить. Именно для этого мы подключили в зависимости
// пакет react-redux. Помимо содержимого page ей будет передана
// функция dispatch, позволяющая выполнять действия.
function mapStateToProps(state) {
const {page} = state;
return page;
}
export default connect(mapStateToProps)(CardPage);
Добавим простенькую обработку page.type в наш корневой компонент App:
// frontend/src/components/app.js
import React, {Component} from 'react'
import {connect} from "react-redux";
import CardPage from "./cardPage"
class App extends Component {
render() {
const {pageType} = this.props;
return (
<div>
{pageType === "card" && <CardPage/>}
</div>
);
}
}
function mapStateToProps(state) {
const {page} = state;
const {type} = page;
return {
pageType: type
};
}
export default connect(mapStateToProps)(App);
И теперь остался последний момент — надо как-то инициализировать page.type и page.cardSlug в зависимости от URL страницы.
Но в этой статье ещё много разделов, мы же не можем сделать качественное решение прямо сейчас. Давайте пока что сделаем это как-нибудь глупо. Вот прям совсем глупо. Например, регуляркой при инициализации приложения!
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
let initialState = {
page: {
type: "home"
}
};
const m = /^/card/([^/]+)$/.exec(location.pathname);
if (m !== null) {
initialState = {
page: {
type: "card",
cardSlug: m[1]
},
}
}
const store = configureStore(initialState);
render(
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Теперь мы можем пересобрать фронтенд с помощью docker-compose up --build frontend, чтобы насладиться нашей карточкой helloworld…

Так, секундочку… а где же наш контент? Ох, да мы ведь забыли распарсить Markdown!
Воркер: RQ
Парсинг Markdown и генерация HTML для карточки потенциально неограниченного размера — типичная «тяжёлая» задача, которую вместо того, чтобы решать прямо на бэкенде при сохранении изменений, обычно ставят в очередь и исполняют на отдельных машинах — воркерах.
Есть много опенсорсных реализаций очередей задач; мы возьмём Redis и простенькую библиотечку RQ (Redis Queue), которая передаёт параметры задач в формате pickle и сама организует нам спаунинг процессов для их обработки.
Время добавить редис в зависимости, настройки и вайринг!
--- a/requirements.txt
+++ b/requirements.txt
@@ -3,3 +3,5 @@ flask-cors
gevent
gunicorn
pymongo
+redis
+rq
--- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -1,3 +1,7 @@
MONGO_HOST = "mongo"
MONGO_PORT = 27017
MONGO_DATABASE = "core"
+REDIS_HOST = "redis"
+REDIS_PORT = 6379
+REDIS_DB = 0
+TASK_QUEUE_NAME = "tasks"
--- a/backend/wiring.py
+++ b/backend/wiring.py
@@ -2,6 +2,8 @@ import os
from pymongo import MongoClient
from pymongo.database import Database
+import redis
+import rq
import backend.dev_settings
from backend.storage.card import CardDAO
@@ -21,3 +23,11 @@ class Wiring(object):
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
+
+ self.redis: redis.Redis = redis.StrictRedis(
+ host=self.settings.REDIS_HOST,
+ port=self.settings.REDIS_PORT,
+ db=self.settings.REDIS_DB)
+ self.task_queue: rq.Queue = rq.Queue(
+ name=self.settings.TASK_QUEUE_NAME,
+ connection=self.redis)
Немного бойлерплейтного кода для воркера.
# worker/__main__.py
import argparse
import uuid
import rq
import backend.wiring
parser = argparse.ArgumentParser(description="Run worker.")
# Удобно иметь флаг, заставляющий воркер обработать все задачи
# и выключиться. Вдвойне удобно, что такой режим уже есть в rq.
parser.add_argument(
"--burst",
action="store_const",
const=True,
default=False,
help="enable burst mode")
args = parser.parse_args()
# Нам нужны настройки и подключение к Redis.
wiring = backend.wiring.Wiring()
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
# Если мы захотим запускать несколько воркеров в разных
# контейнерах, им потребуются уникальные имена.
name=uuid.uuid4().hex)
w.work(burst=args.burst)
Для самого парсинга подключим библиотечку mistune и напишем простенькую функцию:
# backend/tasks/parse.py
import mistune
from backend.storage.card import CardDAO
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
Логично: нам нужен CardDAO, чтобы получить исходники карточки и чтобы сохранить результат. Но объект, содержащий подключение к внешнему хранилищу, нельзя сериализовать через pickle — а значит, эту таску нельзя сразу взять и поставить в очередь RQ. По-хорошему нам нужно создать Wiring на стороне воркера и прокидывать его во все таски… Давайте сделаем это:
--- a/worker/__main__.py
+++ b/worker/__main__.py
@@ -2,6 +2,7 @@ import argparse
import uuid
import rq
+from rq.job import Job
import backend.wiring
@@ -16,8 +17,23 @@ args = parser.parse_args()
wiring = backend.wiring.Wiring()
+
+class JobWithWiring(Job):
+
+ @property
+ def kwargs(self):
+ result = dict(super().kwargs)
+ result["wiring"] = backend.wiring.Wiring()
+ return result
+
+ @kwargs.setter
+ def kwargs(self, value):
+ super().kwargs = value
+
+
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
- name=uuid.uuid4().hex)
+ name=uuid.uuid4().hex,
+ job_class=JobWithWiring)
w.work(burst=args.burst)
Мы объявили свой класс джобы, прокидывающий вайринг в качестве дополнительного kwargs-аргумента во все таски. (Обратите внимание, что он создаёт каждый раз НОВЫЙ вайринг, потому что некоторые клиенты нельзя создавать перед форком, который происходит внутри RQ перед началом обработки задачи.) Чтобы все наши таски не стали зависеть от вайринга — то есть от ВСЕХ наших объектов, — давайте сделаем декоратор, который будет доставать из вайринга только нужное:
# backend/tasks/task.py
import functools
from typing import Callable
from backend.wiring import Wiring
def task(func: Callable):
# Достаём имена аргументов функции:
varnames = func.__code__.co_varnames
@functools.wraps(func)
def result(*args, **kwargs):
# Достаём вайринг. Используем .pop(), потому что мы не
# хотим, чтобы у тасок был доступ ко всему вайрингу.
wiring: Wiring = kwargs.pop("wiring")
wired_objects_by_name = wiring.__dict__
for arg_name in varnames:
if arg_name in wired_objects_by_name:
kwargs[arg_name] = wired_objects_by_name[arg_name]
# Здесь могло бы быть получение объекта из вайринга по
# аннотации типа аргумента, но как-нибудь в другой раз.
return func(*args, **kwargs)
return result
Добавляем декоратор к нашей таске и радуемся жизни:
import mistune
from backend.storage.card import CardDAO
from backend.tasks.task import task
@task
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
Радуемся жизни? Тьфу, я хотел сказать, запускаем воркер:
$ docker-compose up worker
...
Creating habr-app-demo_worker_1 ... done
Attaching to habr-app-demo_worker_1
worker_1 | 17:21:03 RQ worker 'rq:worker:49a25686acc34cdfa322feb88a780f00' started, version 0.13.0
worker_1 | 17:21:03 *** Listening on tasks...
worker_1 | 17:21:03 Cleaning registries for queue: tasks
Ииии… он ничего не делает! Конечно, ведь мы не ставили ни одной таски!
Давайте перепишем нашу тулзу, которая создаёт тестовую карточку, чтобы она: а) не падала, если карточка уже создана (как в нашем случае); б) ставила таску на парсинг маркдауна.
# tools/add_test_content.py
from backend.storage.card import Card, CardNotFound
from backend.tasks.parse import parse_card_markup
from backend.wiring import Wiring
wiring = Wiring()
try:
card = wiring.card_dao.get_by_slug("helloworld")
except CardNotFound:
card = wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
# Да, тут нужен card_dao.get_or_create, но
# эта статья и так слишком длинная!
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
Тулзу теперь можно запускать не только на backend, но и на worker. В принципе, сейчас нам нет разницы. Запускаем docker-compose exec worker python -m tools.add_test_content и в соседней вкладке терминала видим чудо — воркер ЧТО-ТО СДЕЛАЛ!
worker_1 | 17:34:26 tasks: backend.tasks.parse.parse_card_markup(card_id='5c715dd1e201ce000c6a89fa') (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 tasks: Job OK (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 Result is kept for 500 seconds
Пересобрав контейнер с бэкендом, мы наконец можем увидеть контент нашей карточки в браузере:

Фронтенд: навигация
Прежде, чем мы перейдём к SSR, нам нужно сделать всю нашу возню с React хоть сколько-то осмысленной и сделать наше single page application действительно single page. Давайте обновим нашу тулзу, чтобы создавалось две (НЕ ОДНА, А ДВЕ! МАМА, Я ТЕПЕРЬ БИГ ДАТА ДЕВЕЛОПЕР!) карточки, ссылающиеся друг на друга, и потом займёмся навигацией между ними.
Скрытый текст
# tools/add_test_content.py
def create_or_update(card):
try:
card.id = wiring.card_dao.get_by_slug(card.slug).id
card = wiring.card_dao.update(card)
except CardNotFound:
card = wiring.card_dao.create(card)
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
create_or_update(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page. It can't really compete with the [demo page](demo).
"""))
create_or_update(Card(
slug="demo",
name="Demo Card!",
markdown="""
Hi there, habrovchanin. You've probably got here from the awkward ["Hello, world" card](helloworld).
Well, **good news**! Finally you are looking at a **really cool card**!
"""
))
Теперь мы можем ходить по ссылкам и созерцать, как каждый раз наше чудесное приложение перезагружается. Хватит это терпеть!
Сперва навесим свой обработчик на клики по ссылкам. Поскольку HTML со ссылками у нас приходит с бэкенда, а приложение у нас на React, потребуется небольшой React-специфический фокус.
// frontend/src/components/card.js
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
navigate(event) {
// Это обработчик клика по всему нашему контенту. Поэтому
// на каждый клик надо сперва проверить, по ссылке ли он.
if (event.target.tagName === 'A'
&& event.target.hostname === window.location.hostname) {
// Отменяем стандартное поведение браузера
event.preventDefault();
// Запускаем своё действие для навигации
this.props.dispatch(navigate(event.target));
}
}
render() {
const {name, html} = this.props;
return (
<div>
<h1>{name}</h1>
<div
dangerouslySetInnerHTML={{__html: html}}
onClick={event => this.navigate(event)}
/>
</div>
);
}
}
Поскольку вся логика с подгрузкой карточки у нас в компоненте CardPage, в самом действии (изумительно!) не нужно предпринимать никаких действий:
export function navigate(link) {
return {
type: NAVIGATE,
path: link.pathname
}
}
Добавляем глупенький редьюсер под это дело:
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD,
NAVIGATE
} from "./actions";
function navigate(state, path) {
// Здесь мог бы быть react-router, но он больно сложный!
// (И ещё его очень трудно скрестить с SSR.)
let m = /^/card/([^/]+)$/.exec(path);
if (m !== null) {
return {
...state,
page: {
type: "card",
cardSlug: m[1],
isFetching: true
}
};
}
return state
}
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
};
case NAVIGATE:
return navigate(state, action.path)
}
return state;
}
Поскольку теперь состояние нашего приложения может изменяться, в CardPage нужно добавить метод componentDidUpdate, идентичный уже добавленному нами componentWillMount. Теперь после обновления свойств CardPage (например, свойства cardSlug при навигации) тоже будет запрашиваться контент карточки с бэкенда (componentWillMount делал это только при инициализации компоненты).
Вжух, docker-compose up --build frontend и у нас рабочая навигация!

Внимательный читатель обратит внимание, что URL страницы не будет изменяться при навигации между карточками — даже на скриншоте мы видим Hello, world-карточку по адресу demo-карточки. Соответственно, навигация вперёд-назад тоже отвалилась. Давайте сразу добавим немного чёрной магии с history, чтобы починить это!
Самое простое, что можно сделать — добавить в действие navigate вызов history.pushState.
export function navigate(link) {
history.pushState(null, "", link.href);
return {
type: NAVIGATE,
path: link.pathname
}
}
Теперь при переходах по ссылкам URL в адресной строке браузера будет реально меняться. Однако, кнопка «Назад» сломается!
Чтобы всё заработало, нам надо слушать событие popstate объекта window. Причём, если мы захотим при этом событии делать навигацию назад так же, как и вперёд (то есть через dispatch(navigate(...))), то придётся в функцию navigate добавить специальный флаг «не делай pushState» (иначе всё разломается ещё сильнее!). Кроме того, чтобы различать «наши» состояния, нам стоит воспользоваться способностью pushState сохранять метаданные. Тут много магии и дебага, поэтому перейдём сразу к коду! Вот как станет выглядеть App:
// frontend/src/components/app.js
class App extends Component {
componentDidMount() {
// Наше приложение только загрузилось -- надо сразу
// пометить текущее состояние истории как "наше".
history.replaceState({
pathname: location.pathname,
href: location.href
}, "");
// Добавляем обработчик того самого события.
window.addEventListener("popstate", event => this.navigate(event));
}
navigate(event) {
// Триггеримся только на "наше" состояние, иначе пользователь
// не сможет вернуться по истории на тот сайт, с которого к
// нам пришёл (or is it a good thing?..)
if (event.state && event.state.pathname) {
event.preventDefault();
event.stopPropagation();
// Диспатчим наше действие в режиме "не делай pushState".
this.props.dispatch(navigate(event.state, true));
}
}
render() {
// ...
}
}
А вот как — действие navigate:
// frontend/src/redux/actions.js
export function navigate(link, dontPushState) {
if (!dontPushState) {
history.pushState({
pathname: link.pathname,
href: link.href
}, "", link.href);
}
return {
type: NAVIGATE,
path: link.pathname
}
}
Вот теперь история заработает.
Ну и последний штрих: раз уж у нас теперь есть действие navigate, почему бы нам не отказаться от лишнего кода в клиенте, вычисляющего начальное состояние? Мы ведь можем просто вызвать navigate в текущий location:
--- a/frontend/src/client.js
+++ b/frontend/src/client.js
@@ -3,23 +3,16 @@ import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
+import {navigate} from "./redux/actions";
let initialState = {
page: {
type: "home"
}
};
-const m = /^/card/([^/]+)$/.exec(location.pathname);
-if (m !== null) {
- initialState = {
- page: {
- type: "card",
- cardSlug: m[1]
- },
- }
-}
const store = configureStore(initialState);
+store.dispatch(navigate(location));
Копипаста уничтожена!
Фронтенд: server-side rendering
Пришло время для нашей главной (на мой взгляд) фишечки — SEO-дружелюбия. Чтобы поисковики могли индексировать наш контент, полностью создаваемый динамически в React-компонентах, нам нужно уметь выдавать им результат рендеринга React, и ещё и научиться потом делать этот результат снова интерактивным.
Общая схема простая. Первое: в наш HTML-шаблон нам надо воткнуть HTML, сгенерированный нашим React-компонентом App. Этот HTML будут видеть поисковые движки (и браузеры с выключенным JS, хе-хе). Второе: в шаблон надо добавить тег <script>, сохраняющий куда-нибудь (например, в объект window) дамп состояния, из которого отрендерился этот HTML. Тогда мы сможем сразу инициализировать наше приложение на стороне клиента этим состоянием и показывать что надо (мы даже можем применить hydrate к сгенерированному HTML, чтобы не создавать DOM tree приложения заново).
Начнём с написания функции, возвращающей отрендеренный HTML и итоговое состояние.
// frontend/src/server.js
import "@babel/polyfill"
import React from 'react'
import {renderToString} from 'react-dom/server'
import {Provider} from 'react-redux'
import App from './components/app'
import {navigate} from "./redux/actions";
import configureStore from "./redux/configureStore";
export default function render(initialState, url) {
// Создаём store, как и на клиенте.
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
<Provider store={store}>
<App/>
</Provider>
);
// Оказывается, в реакте уже есть функция рендеринга в строку!
// Автор, ну и зачем ты десять разделов пудрил мне мозги?
let content = renderToString(app);
let preloadedState = store.getState();
return {content, preloadedState};
};
Добавим в наш шаблон новые аргументы и логику, о которой мы говорили выше:
// frontend/src/template.js
function template(title, initialState, content) {
let page = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>${title}</title>
</head>
<body>
<div id="app">${content}</div>
<script>
window.__STATE__ = ${JSON.stringify(initialState)}
</script>
<script src="/dist/client.js"></script>
</body>
</html>
`;
return page;
}
module.exports = template;
Немного сложнее становится наш Express-сервер:
// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
}
};
const {content, preloadedState} = render(initialState, {pathname: req.url});
res.send(template("Habr demo app", preloadedState, content));
});
Зато клиент — проще:
// frontend/src/client.js
import React from 'react'
import {hydrate} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
import {navigate} from "./redux/actions";
// Больше не надо задавать начальное состояние и дёргать навигацию!
const store = configureStore(window.__STATE__);
// render сменился на hydrate. hydrate возьмёт уже существующее
// DOM tree, провалидирует и навесит где надо ивент хендлеры.
hydrate(
<Provider store={store}>
<App/>
</Provider>,
document.querySelector('#app')
);
Дальше нужно вычистить ошибки кроссплатформенности вроде «history is not defined». Для этого добавим простую (пока что) фунцию куда-нибудь в utility.js.
// frontend/src/utility.js
export function isServerSide() {
// Вы можете возмутиться, что в браузере не будет process,
// но компиляция с полифиллами как-то разруливает этот вопрос.
return process.env.APP_ENV !== undefined;
}
Дальше будет какое-то количество рутинных изменений, которые я не буду тут приводить (но их можно посмотреть в соответствующем коммите). В итоге наше React-приложение сможет рендериться и в браузере, и на сервере.
Работает! Но есть, как говорится, один нюанс…
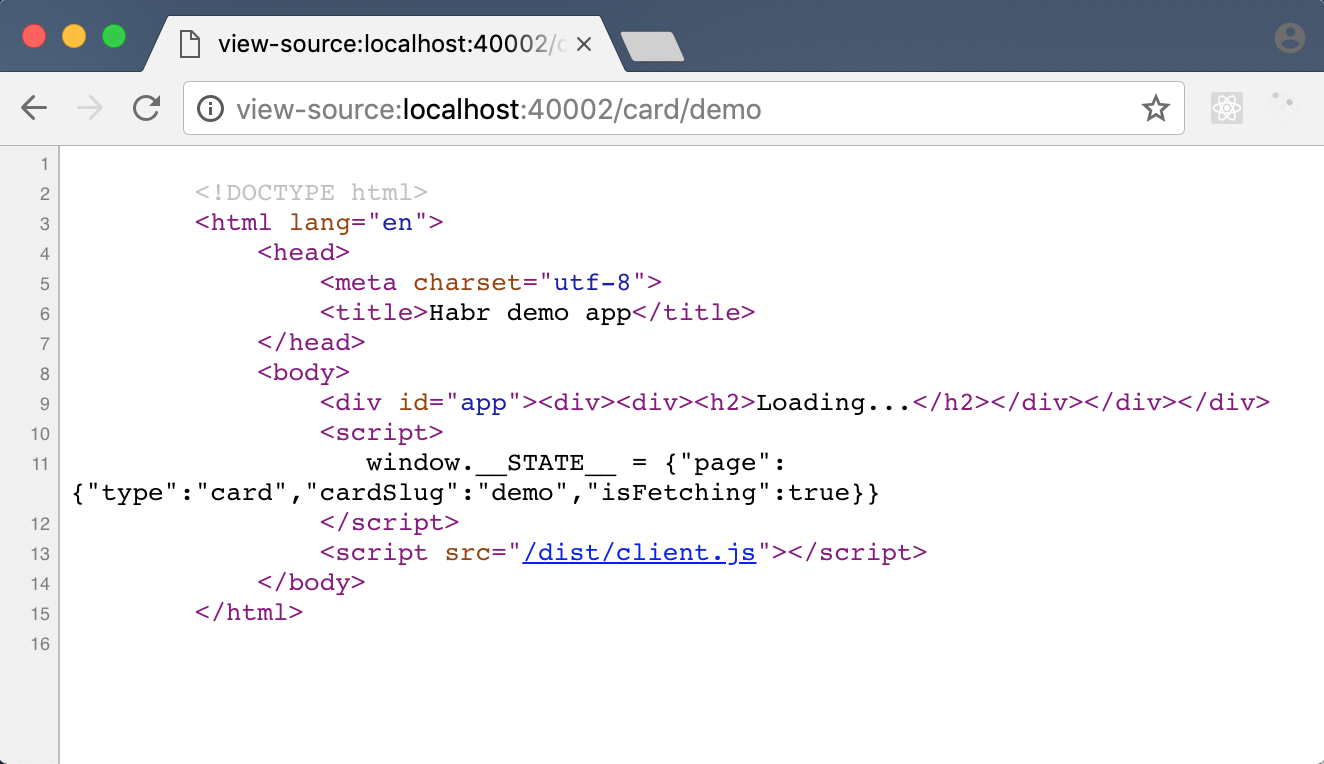
LOADING? Всё, что увидит Google на моём супер-крутом модном сервисе — это LOADING?!
Что ж, кажется, вся наша асинхронщина сыграла против нас. Теперь нам нужен способ дать серверу понять, что ответа от бэкенда с контентом карточки нужно дождаться, прежде чем рендерить React-приложение в строку и отправлять клиенту. И желательно, чтобы способ этот был достаточно общий.
Здесь может быть много решений. Один из подходов — описать в отдельном файле, для каких путей какие данные нужно зафетчить, и сделать это перед тем, как рендерить приложение (статья). У этого решения много плюсов. Оно простое, оно явное и оно работает.
В качестве эксперимента (должен же быть в статье хоть где-то ориджинал контент!) я предлагаю другую схему. Давайте каждый раз, когда мы запускаем что-то асинхронное, чего надо дожидаться, добавлять соответствующий промис (например, тот, который возвращает fetch) куда-нибудь в наше состояние. Так у нас будет место, где всегда можно проверить, всё ли скачалось.
Добавим два новых действия.
// frontend/src/redux/actions.js
function addPromise(promise) {
return {
type: ADD_PROMISE,
promise: promise
};
}
function removePromise(promise) {
return {
type: REMOVE_PROMISE,
promise: promise,
};
}
Первое будем вызывать, когда запустили фетч, второе — в конце его .then().
Теперь добавим их обработку в редьюсер:
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
switch (action.type) {
case ADD_PROMISE:
return {
...state,
promises: [...state.promises, action.promise]
};
case REMOVE_PROMISE:
return {
...state,
promises: state.promises.filter(p => p !== action.promise)
};
...
Теперь усовершенствуем действие fetchCard:
// frontend/src/redux/actions.js
function fetchCard() {
return (dispatch, getState) => {
dispatch(startFetchingCard());
let url = apiPath() + "/card/" + getState().page.cardSlug;
let promise = fetch(url)
.then(response => response.json())
.then(json => {
dispatch(finishFetchingCard(json));
// "Я закончил, можете рендерить"
dispatch(removePromise(promise));
});
// "Я запустил промис, дождитесь его"
return dispatch(addPromise(promise));
};
}
Осталось добавить в initialState пустой массив промисов и заставить сервер дождаться их всех! Функция render становится асинхронной и принимает такой вид:
// frontend/src/server.js
function hasPromises(state) {
return state.promises.length > 0
}
export default async function render(initialState, url) {
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
<Provider store={store}>
<App/>
</Provider>
);
// Вызов renderToString запускает жизненный цикл компонент
// (пусть и ограниченный). CardPage запускает фетч и так далее.
renderToString(app);
// Ждём, пока промисы закончатся! Если мы захотим когда-нибудь
// делать регулярные запросы (логировать пользовательское
// поведение, например), соответствующие промисы не надо
// добавлять в этот список.
let preloadedState = store.getState();
while (hasPromises(preloadedState)) {
await preloadedState.promises[0];
preloadedState = store.getState()
}
// Финальный renderToString. Теперь уже ради HTML.
let content = renderToString(app);
return {content, preloadedState};
};
Ввиду обретённой render асинхронности обработчик запроса тоже слегка усложняется:
// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
},
promises: []
};
render(initialState, {pathname: req.url}).then(result => {
const {content, preloadedState} = result;
const response = template("Habr demo app", preloadedState, content);
res.send(response);
}, (reason) => {
console.log(reason);
res.status(500).send("Server side rendering failed!");
});
});
Et voilà!

Заключение
Как вы видите, сделать высокотехнологичное приложение не так уж и просто. Но не так уж и сложно! Итоговое приложение лежит в репозитории на Github и, теоретически, вам достаточно одного только Docker, чтобы запустить его.
Если статья окажется востребованной, репозиторий этот даже не будет заброшен! Мы сможем на нём же рассмотреть что-нибудь из других знаний, обязательно нужных:
- логирование, мониторинг, нагрузочное тестирование.
- тестирование, CI, CD.
- более крутые фичи вроде авторизации или полнотекстового поиска.
- настройка и развёртка продакшн-окружения.
Спасибо за внимание!
На сегодняшний день в мире разработки на Java существует огромное количество библиотек и технологий, в которых новичку очень легко запутаться. В этом руководстве я постараюсь простым языком описать все шаги, возникающие проблемы и пути их решения. Начинать будем с самого простого и постепенно наращивать функциональность.
Spring Boot
Spring Boot — один из самых популярных универсальных фреймворков для построения веб-приложений на Java. Создадим в среде разработки Gradle Project. Для облегчения работы воспользуемся сайтом https://start.spring.io, который поможет сформировать build.gradle.
Для начала нам необходимо выбрать следующие зависимости:
- Spring Web — необходим для создания веб-приложения;
- Spring Data JPA — для работы с базами данных;
- PostgreSQL Driver — драйвер для работы с PostgreSQL;
- Lombok — библиотека, позволяющая уменьшить количество повторяющегося кода.
В результате генерации build.gradle должно получиться что-то похожее:
plugins {
id 'org.springframework.boot' version '2.4.3'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok:1.18.22'
annotationProcessor 'org.projectlombok:lombok:1.18.22'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
runtimeOnly 'org.postgresql:postgresql'
}
test {
useJUnitPlatform()
}Тот же результат можно получить и в самой IntelliJ Idea: File → New → Project → Spring Initializr.
Объявим Main-класс:
@SpringBootApplication
public class SpringDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDemoApplication.class, args);
}
}Опишем самый простой контроллер, чтобы удостовериться, что проект работает:
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello(@RequestParam(required = false) String name) {
return "Hello, " + name;
}
}Запустим проект в среде разработки или через терминал: ./gradlew bootRun.
Результат работы можно проверить в браузере перейдя по адресу http://localhost:8080/hello?name=World или с помощью консольной утилиты curl:
curl "http://localhost:8080/hello?name=World"
Hello, WorldНаш сервис запускается и работает, пора переходить к следующему шагу.
Представим, что нам требуется разработать некий сервис для интернет-магазина по продаже книг. Это будет rest-сервис, который будет позволять добавлять, редактировать, получать описание книги. Хранить данные будем в БД Postgres.
Docker
Для хранения данных нам потребуется база данных. Проще всего запустить инстанс БД с помощью Docker. Docker позволяет запускать приложение в изолированной среде выполнения — контейнере. Поддерживается всеми операционными системами.
Выкачиваем образ БД и запускаем контейнер:
docker pull postgres:12-alpine
docker run -d -p 5432:5432 --name db
-e POSTGRES_USER=admin
-e POSTGRES_PASSWORD=password
-e POSTGRES_DB=demo
postgres:12-alpineLombok
Создадим data-класс «книга». Он будет иметь несколько полей, которые должны иметь getters, конструктор и должна быть неизменяемой (immutable). Среда разработки позволяет автоматически генерировать конструктор и методы доступа к полям, но чтобы уменьшить количество однотипного кода, будем использовать Lombok.
Аннотация @Value при компиляции исходного кода добавит в наш класс getters, конструктор, пометит все поля класса private final, добавит методы hashCode, equals и toString.
@Value
public class Book {
Long id;
String author;
String title;
Double price;
}После сборки проекта можно посмотреть, как выглядит класс после компиляции. Воспользуемся стандартной утилитой, входящей в состав JDK:
javap -private build/classes/java/main/com/example/BookStore/model/Book
public final class com.example.bookstore.model.Book {
private final java.lang.Long id;
private final java.lang.String author;
private final java.lang.String title;
private final java.lang.Double price;
public com.example.bookstore.model.Book(java.lang.Long, java.lang.String, java.lang.String, java.lang.Double);
public java.lang.Long getId();
public java.lang.String getAuthor();
public java.lang.String getTitle();
public java.lang.Double getPrice();
public boolean equals(java.lang.Object);
public int hashCode();
public java.lang.String toString();
}Lombok очень упрощает читаемость подобного рода классов и очень широко используется в современной разработке.
Spring Data JPA
Для работы с БД нам потребуется Spring Data JPA, который мы уже добавили в зависимости проекта. Дальше нам нужно описать классы Entity и Repository. Первый соответствует таблице в БД, второй необходим для загрузки и сохранения записей в эту таблицу.
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name = "books")
public class BookEntity {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String author;
private String title;
private Double price;
}Мы также используем аннотации Lombok: @Data добавляет getters и setters, @NoArgsConstructor и @AllArgsConstructor — конструкторы без параметров и со всеми параметрами, соответственно. @Entity, @Table, @Id, @GeneratedValue — аннотации относящиеся к JPA. Здесь мы указываем, что это объект БД, название таблицы, первичный ключ и стратегию его генерации (в нашем случае автоматическую).
Класс Repository будет выглядеть совсем просто — достаточно объявить интерфейс и наследоваться от CrudRepository:
public interface BookRepository extends CrudRepository<BookEntity, Long> {
}Никакой реализации не требуется. Spring всё сделает за нас. В данном случае мы сразу получим функциональность CRUD — create, read, update, delete. Функционал можно наращивать — чуть позже мы это увидим. Мы описали DAO-слой.
Теперь нам нужен некий сервис, который будет иметь примерно следующий интерфейс:
public interface BookService {
Book getBookById(Long id);// получить книгу по id
List<Book> getAllBooks();// получить список всех книг
void addBook(Book book);// добавить книгу
}Это так называемый сервисный слой. Реализуем этот интерфейс:
@Service
@RequiredArgsConstructor
public class DefaultBookService implements BookService{
private final BookRepository bookRepository;
@Override
public Book getBookById(Long id) {
BookEntity bookEntity = bookRepository
.findById(id)
.orElseThrow(() -> new BookNotFoundException("Book not found: id = " + id));
return new Book(bookEntity.getId(),
bookEntity.getAuthor(),
bookEntity.getTitle(),
bookEntity.getPrice());
}
@Override
public List<Book> getAllBooks() {
Iterable<BookEntity> iterable = bookRepository.findAll();
ArrayList<Book> books = new ArrayList<>();
for (BookEntity bookEntity : iterable) {
books.add(new Book(bookEntity.getId(),
bookEntity.getAuthor(),
bookEntity.getTitle(),
bookEntity.getPrice()));
}
return books;
}
@Override
public void addBook(Book book) {
BookEntity bookEntity = new BookEntity(null,
book.getAuthor(),
book.getTitle(),
book.getPrice());
bookRepository.save(bookEntity);
}
}Аннотацией @Service мы возлагаем на Spring создание объекта этого класса. @RequiredArgsConstructor — уже знакомая нам аннотация, которая генерирует конструктор с необходимыми аргументами. В нашем случае класс имеет final-поле bookRepository, которое необходимо проинициализировать. Добавив эту аннотацию, мы получим следующую реализацию:
public DefaultBookService(BookRepository bookRepository) {
this.bookRepository = bookRepository;
}При создании объекта класса Spring опять всё возьмёт на себя — сам создаст объект BookRepository и передаст его в конструктор. Имея объект репозитория мы можем выполнять операции с БД:
bookRepository.findById(id); //прочитать запись из БД по первичному ключу id
bookRepository.findAll(); //прочитать все записи из БД и вернуть их в виде списка
bookRepository.save(bookEntity); //сохранить объект в БДМетод findById возвращает объект типа Optional<BookEntity>. Это такой специальный тип который может содержать, а может и не содержать значение. Альтернативный способ проверки на null, но позволяющий более изящно написать код. Метод orElseThrow извлекает значение из Optional, и, если оно отсутствует, бросает исключение, которое создается в переданном в качестве аргумента лямбда-выражении. То есть объект исключения будет создаваться только в случае отсутствия значения в Optional.
MapStruct
Смотря на код может показаться, что класс Book не нужен, и достаточно только BookEntity, но это не так. Book — это класс сервисного слоя, а BookEntity — DAO. В нашем простом случае они действительно повторяют друг друга, но бывают и более сложные случаи, когда сервисный слой оперирует с несколькими таблицами и соответственно DAO-объектами.
Если присмотреться, то и тут мы видим однотипный код, когда мы перекладываем данные из BookEntity в Book и обратно. Чтобы упростить себе жизнь и сделать код более читаемым, воспользуемся библиотекой MapStruct. Это mapper, который за нас будет выполнять перекладывание данных из одного объекта в другой и обратно. Для этого добавим зависимости в build.gradle:
dependencies {
...
implementation 'org.mapstruct:mapstruct:1.4.2.Final'
annotationProcessor 'org.mapstruct:mapstruct-processor:1.4.2.Final'
}Создадим mapper, для этого необходимо объявить интерфейс, в котором опишем методы для конвертации из BookEntity в Book и обратно:
@Mapper(componentModel = "spring")
public interface BookToEntityMapper {
BookEntity bookToBookEntity(Book book);
Book bookEntityToBook(BookEntity bookEntity);
}Так как имена полей классов соотносятся один к одному, то интерфейс получился таким простым. Если поля имеют отличающиеся имена, то потребуется аннотацией @Mapping указать какие поля соответствуют друг другу. Более подробно можно найти в документации. Чтобы spring смог сам создавать бины этого класса, необходимо указать componentModel = "spring".
После сборки проекта, в каталоге build/generated/sources/annotationProcessor появится сгенерированный исходный код mapper, избавив нас от необходимости писать однотипные десятки строк кода:
@Component
public class BookToEntityMapperImpl implements BookToEntityMapper {
@Override
public BookEntity bookToBookEntity(Book book) {
if ( book == null ) {
return null;
}
BookEntity bookEntity = new BookEntity();
bookEntity.setId( book.getId() );
bookEntity.setAuthor( book.getAuthor() );
bookEntity.setTitle( book.getTitle() );
bookEntity.setPrice( book.getPrice() );
return bookEntity;
}
@Override
public Book bookEntityToBook(BookEntity bookEntity) {
if ( bookEntity == null ) {
return null;
}
Long id = null;
String author = null;
String title = null;
Double price = null;
id = bookEntity.getId();
author = bookEntity.getAuthor();
title = bookEntity.getTitle();
price = bookEntity.getPrice();
Book book = new Book( id, author, title, price );
return book;
}
}Воспользуемся мэппером и перепишем DefaultBookService. Для этого нам достаточно добавить добавить final-поле BookMapper, которое Lombok автоматически подставит в аргумент конструктора, а spring сам инстанциирует и передаст параметром в него:
@Service
@RequiredArgsConstructor
public class DefaultBookService implements BookService{
private final BookRepository bookRepository;
private final BookToEntityMapper mapper;
@Override
public Book getBookById(Long id) {
BookEntity bookEntity = bookRepository
.findById(id)
.orElseThrow(() -> new BookNotFoundException("Book not found: id = " + id));
return mapper.bookEntityToBook(bookEntity);
}
@Override
public List<Book> getAllBooks() {
Iterable<BookEntity> iterable = bookRepository.findAll();
ArrayList<Book> books = new ArrayList<>();
for (BookEntity bookEntity : iterable) {
books.add(mapper.bookEntityToBook(bookEntity));
}
return books;
}
@Override
public void addBook(Book book) {
BookEntity bookEntity = bookMapper.bookToBookEntity(book);
mapper.save(bookEntity);
}
...Теперь опишем контроллер, который будет позволять выполнять http-запросы к нашему сервису. Для добавления книги нам потребуется описать класс запроса. Это data transfer object, который относится к своему слою DTO.
@Data
public class BookRequest {
private String author;
private String title;
private Double price;
}Нам также потребуется конвертировать объект AddBookRequest в объект Book. Создадим для этого BookToDtoMapper:
@Mapper(componentModel = "spring")
public interface BookToDtoMapper {
Book AddBookRequestToBook(BookRequest bookRequest);
}Теперь объявим контроллер, на эндпоинты которого будут приходить запросы на создание и получение книг, добавив зависимости BookService и BookToDtoMapper. При необходимости аналогично объекту AddBookRequest можно описать Response-объект, добавив соответствующий метод в мэппер, который будет конвертировать Book в GetBookResponse. Контроллер будет содержать 3 метода: методом POST мы будем добавлять книгу, методом GET получать список всех книг и книгу по идентификатору, который будем передавать в качестве PathVariable.
@RestController()
@RequestMapping("/books")
@RequiredArgsConstructor
public class BookController {
private final BookService bookService;
private final BookToDtoMapper mapper;
@GetMapping("/{id}")
public Book getBookById(@PathVariable Long id) {
return bookService.getBookById(id);
}
@GetMapping
public List<Book> getAllBooks() {
return bookService.getAllBooks();
}
@PostMapping
public void addBook(@RequestBody AddBookRequest request) {
bookService.addBook(mapper.AddBookRequestToBook(request));
}
}Осталось создать файл настроек приложения. Для Spring boot по умолчанию это application.properties или application.yml. Мы будем использовать формат properties. Необходимо указать настройки для соединения с БД (выше мы задавали пользователя и его пароль при старте docker-контейнера):
spring.datasource.url=jdbc:postgresql://localhost:5432/demo
spring.datasource.username=admin
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=trueНастройка spring.jpa.hibernate.ddl-auto=update указывает hibernate необходимость обновить схему когда это нужно. Так как мы не создавали никаких схем, то приложение сделает это автоматически. В процессе промышленной разработки схемы баз данных постоянно меняются, и часто используются инструменты для версионирования и применения этих изменений, например Liquibase.
Запустим наше приложение и выполним запросы на добавление книг:
curl -X POST --location "http://localhost:8080/books"
-H "Content-Type: application/json"
-d "{
"author" : "Joshua Bloch",
"title" : "Effective Java",
"price" : 54.99
}"
curl -X POST --location "http://localhost:8080/books"
-H "Content-Type: application/json"
-d "{
"author" : "Kathy Sierra",
"title" : "Head First Java",
"price" : 12.66
}"
curl -X POST --location "http://localhost:8080/books"
-H "Content-Type: application/json"
-d "{
"author" : "Benjamin J. Evans",
"title" : "Java in a Nutshell: A Desktop Quick Reference",
"price" : 28.14
}"После выполнения запросов в таблице books должны появиться записи. Чтобы удостовериться в этом, можно использовать любой удобный клиент БД. Для примера сделаем это, используя консольный клиент, входящий в состав docker-контейнера. При создании контейнера, мы указали его имя ‘db’ (если имя не задавалось, то можно вывести список всех запущенных контейнеров командой docker container ls, и дальше использовать идентификатор нужного контейнера). Для доступа к шелл-оболочке выполним:
docker exec -ti db shЗапустим клиент БД и выполним sql-запрос:
psql --username=admin --dbname=demo
psql (12.6)
Type "help" for help.
demo=# SELECT * FROM books;
id | author | price | title
----+-------------------+-------+-----------------------------------------------
1 | Joshua Bloch | 54.99 | Effective Java
2 | Kathy Sierra | 12.66 | Head First Java
3 | Benjamin J. Evans | 28.14 | Java in a Nutshell: A Desktop Quick Reference
(3 rows)Получим список всех книг:
curl -X GET --location "http://localhost:8080/books"
-H "Accept: application/json"
[
{
"id": 1,
"author": "Joshua Bloch",
"title": "Effective Java",
"price": 54.99
},
{
"id": 2,
"author": "Kathy Sierra",
"title": "Head First Java",
"price": 12.66
},
{
"id": 3,
"author": "Benjamin J. Evans",
"title": "Java in a Nutshell: A Desktop Quick Reference",
"price": 28.14
}
]Получим книгу через запрос к api нашего сервиса, указав идентификатор книги:
curl -X GET --location "http://localhost:8080/books/2"
-H "Accept: application/json"
{
"id": 2,
"author": "Kathy Sierra",
"title": "Head First Java",
"price": 12.66
}Добавим к нашему api более сложную функциональность — поиск по автору книги. Для этого в BookRepository нужно описать метод, который будет делать соответствующий SELECT из БД. Это можно сделать с помощью аннотации @Query, а можно назвать метод в соответствии со специальной нотацией Spring:
List<BookEntity> findAllByAuthorContaining(String author);В документации можно подробнее прочитать об именовании методов. Здесь мы указываем findAll — найти все записи, ByAuthor — параметр обрамляется %. При вызове этого метода (например с аргументом ‘Bloch’) будет сгенерирован следующий запрос:
SELECT * FROM books WHERE author LIKE '%Bloch%';Далее добавим метод в BookService и DefaultBookService:
@Override
public List<Book> findByAuthor(String author) {
Iterable<BookEntity> iterable = bookRepository.findAllByAuthorContaining(author);
ArrayList<Book> books = new ArrayList<>();
for (BookEntity bookEntity : iterable) {
books.add(mapper.bookEntityToBook(bookEntity));
}
return books;
}А в контроллере немного модифицируем метод получения списка книг таким образом, что при передаче get-параметра author мы искали по автору, а если параметр не передётся, то используется старая логика и выводится список всех книг:
@GetMapping
public List<Book> getAllBooks(@RequestParam(required = false) String author) {
if (author != null)
return bookService.findByAuthor(author);
return bookService.getAllBooks();
}Теперь можно выполнить поиск:
curl -X GET --location "http://localhost:8080/books?author=Bloch"
-H "Accept: application/json"
[
{
"id": 1,
"author": "Joshua Bloch",
"title": "Effective Java",
"price": 54.99
}
]Итак, мы написали веб-сервис и познакомились с очень распространенными библиотеками. В следующей части продолжим улучшать наше приложение, добавив в него авторизацию, а также напишем отдельный микросервис, который будет выписывать токены доступа.
Код проекта доступен на GitHub.
Если вы всерьез подумываете о разработке своего веб-приложения, сначала ответьте на два вопроса:
- Для решения какой задачи будет использоваться это приложение?
- Каким способом будет разработано данное приложение?
Первое — веб-приложение всегда разрабатывается для решения конкретной задачи, как правило, одной. Оно должно быстро реагировать на изменения, и чем проще и меньше время реакции, тем более веб-приложение жизнеспособно.
Второе — есть по меньшей мере 6 путей к разработке веб-приложения, самым современным из которых является реализация фронтенда как single page application, где контакт с бэкендом реализуется через REST API. Данный путь к созданию веб-приложения достигается за 8 шагов.
1. Работа с бизнес-логикой бэкенда
Есть два способа такой работы: вы можете сгруппировать бизнес-логику бэкенда в одном сервисе (монолитная логика) или реализовать каждый ее компонент в отдельном микросервисе. Работая с небольшим проектом, используйте первый способ, а при работе с крупным проектом идеально подойдет второй.
2. Выбор языка программирования
Если вам менее важна производительность веб-приложения, пишите на Python (фреймворки Django, Flask), Node JS (фреймворки Express JS, Koa JS, Gatsby JS), Ruby (фреймворки Ruby on Rails, Grape). Если в приоритете скорость приложения — используйте Golang (фреймворки Gingonic, Beego, Revel). Еще вы можете использовать популярный язык программирования от Microsoft — C#, который произносится как «си шарп». Он разработан в качестве языка прикладного уровня для CLR. С# вобрал в себя многое от C++, Модула, Delphi, Smalltalk и Java, но разница состоит в том, что С# исключает модели, которые зарекомендовали себя как проблемные при разработке ПС. К примеру, C# в отличие от C++ не поддерживает множественное наследование классов, но допускает множественную реализацию интерфейсов. Главное, какой бы язык вы не выбрали, кодить на том, который вы хорошо знаете.
3. Реализация бизнес-логики
Сперва ориентируйтесь на паттерн MVC, а когда поймете, что бизнес-логика начинает усложняться, используйте presenter и interactor. Но помните, что presenter и interactor находится на разных уровнях и выполняют различные смысловые и функциональные нагрузки.
Presenter обрабатывают события от пользовательского интерфейса (UI) и выполняют роль callback из внутренних уровней (Interactors). Presenters легко тестировать и их задача состоит в том, чтобы получить информацию от веб-приложения и преобразовать ее для перемещения presenters на экран с помощью представления (View).
Interactor по факту вмещают бизнес-логику веб-приложения, то есть проверку условий и обработку информации. Interactor работают фоном и перемещают события и информацию на верхний уровень, presenters, c помощью callback.
4. QA-тестирование бэкенда
Тестирование нужно обязательно делать для того, чтобы знать, правильно ли работает бизнес-логика вашего веб-приложения, а также для того чтобы не проверять постоянно «вручную» работоспособность кода. Используйте автоматическое тестирование для модулей и библиотек, соответствия UI/UX и API. Пропишите несколько вариантов тестирования. Разработайте roadmap для платформы, чтобы управлять испытаниями для всех типов тестирования. Обязательно сделайте подключение инструментов отслеживания текущего покрытия кода, чтобы убедиться в том, что ваше веб-приложение не «виснет» и работает без багов и перебоев.
5. Добавление поддержки сваггера
Swagger – это «умная» документация RESTful web-API. По сути, это фреймворк для спецификации REST API, дающий возможность не только просматривать спецификацию в интерактивном режиме, но и отправлять запросы, именуемые Swagger UI. А теперь на счет веб-приложения.
Предположим, вы уже начали разработку фронтенда вашего веб-приложения. Как вам понять, какие параметры и запросы отправлять на сервер? Заглядывать в код бэкенда? Поверьте, это не лучший выход.
Рекомендую вам добавить поддержку сваггера, при этом очень здорово, если сваггер еще и поддерживает генерацию через тесты. Таким образом, он поможет вам документировать API.
6. Работа с бизнес-логикой фронтенда
Сложность работы с бизнес-логикой фронтенда заключается в том, что тут очень много фреймворков. Обычно в современном програмировании используются Angular, React, Vue. У них у всех есть как свои достоинства, так и свои недостатки. Но я рекомендую вам выбирать для работы с фронтендом React, так как он легче, проще и более гибкий.
7. QA-тестирование фронтенда
Фронтенд тестируют двумя основными видами тестов — на логику и на отображение. Тесты на логику проверяют логическую реализацию функций и классов. Тесты на отображение отвечают за то, чтобы наполнение демонстрировалось пользователю в том виде, который вы задумали, прописывая фронтенд. Для осуществления QA-тестирования фронтенда используйте такие фреймворки, как Mocha, Chai, Jest, Ava, Enzyme, Jest — они самые ходовые, простые в эксплуатации и наиболее понятные из всех.
8. Мониторинг качества веб-приложения
Когда вы завершили седьмой этап, ваше веб-приложение, можно сказать, готово. Ну, или оно находится на финальной стадии готовности — 98%. Что вам нужно знать по итогу? Естественно, первое, что нужно, — это понять, насколько качественно реализовано приложение, как оно будет работать и на какое время хватит его износостойкости. В этом вам поможет Lighthouse — автоматизированный инструмент с открытым исходным кодом для мониторинга качества вашего веб-приложения. Lighthouse проводит системный аудит производительности и доступности веб-приложения для понимания обычного пользователя.
Собранные с помощью Lighthouse данные помогут вам в дальнейшем в случае надобности дорабатывать ваше веб-приложение, изменять в нем какие-то детали или же добавлять и оптимизировать новые функции.
Имейте в виду, что, начав разработку веб-приложения, вам нужно будет изучить все «подводные камни» каждого этапа, а также запастись терпением, потому как сама разработка может занять у вас несколько дней, а вот тестирование и доработка с устранением багов может затянуться и на многие месяцы. Будьте ко всему готовы и помните про первые и самые важные два вопроса: всегда ставьте конкретную задачу, которую должно решать ваше приложение, перед тем, как начать разработку, и выбирайте самый удобный и легкий для вас способ разработки, в котором вы хорошо ориентируетесь. Ведь разработка веб-приложения — это именно тот случай, когда надо идти путем наименьшего сопротивления.
Многие современные программисты предпочитают в своей работе пользоваться Java. Несмотря на то, что спросом пользуется Си-семейство, Джава тоже не уступает. Связано это с тем, что данный язык является универсальным. Он удобен, понятен и практичен.
С самого своего возникновения (в 1995 году) стал активно развиваться и совершенствоваться. Сейчас Java удобно использовать как для компьютерных программ, так и для мобильных платформ. Это – полноценный язык, поддерживающий объектно-ориентированное программирование. Ключевая особенность Java – возможность создавать веб-приложения и расширения.
Перед тем, как садиться за написание первых приложений на Джаве, нужно знать, какими особенностями обладает соответствующий язык. Далеко не все «способы общения» с софтом и «железом» подходят для написания конкретного контента.
У Java следующие особенности:
- наличие функционала для ООП;
- понятный и относительно простой синтаксис – освоить его может даже начинающий программист-любитель;
- хорошая пользовательская поддержка – она дружелюбна к новичкам;
- достаточное количество документации на всех языках, включая русский;
- движок и библиотеки для написания игр и всевозможных веб утилит.
Java великолепно «работает» с Сетью. Именно для этой цели изначально планировалось создание оного. Также стоит отметить – упомянутый язык является кроссплатформенным. Перенести программу из одной ОС в другую удается в кратчайшие сроки и без потери качества исходной кодификации.
Понятие веб-приложения
Веб-приложение в Java – это специальная программа, основанная на принципе работы по типу клиент-сервис. Давайте рассмотри соответствующие понятия позже. Сначала стоит разобраться, что собой представляет тип утилиты, которую хочется написать на Джаве на этот раз.
В веб-приложении клиент будет взаимодействовать с веб-сервером посредством вспомогательных утилит. Их называют браузерами. Логика распределяется между сервером и клиентом. Хранение информации производится в основном на servers. Обмен данными обеспечивается Сетью.
Основное преимущество подобного контента – это то, что клиенты не будут зависеть от той или иной операционной системы. Не важно, какая ОС установлена на задействованном устройстве. Web-приложения будут работать везде. Это – кроссплатформенный вариант.
Техособенности
Веб приложения имеют ряд особенностей, которые делают соответствующий контент удобным и продуктивным. Важно учитывать следующие моменты:
- Функции выполняются независимо от ОС пользователя.
- Приложение будет создаваться всего один раз для произвольно выбранной платформе. Именно на ней осуществляется дальнейшее развертывание.
- Иногда пользовательские права на редактирование настроек интернет-обозревателя способны доставить немало хлопот. Приложения для работы с сетью будут отображаться некорректно.
- Не исключены проблемы при разработке и поддержке утилит из-за разной реализации CSS и DOM.
- Возможно использование Java-апплетов и Adobe Flash. Со вторым типом приложений сегодня возникают затруднения. Связано это с тем, что Flash-технологии с 2015 года перестали поддерживаться.
В каком-то смысле веб приложения можно отнести к «толстым» клиентам. Связано это с особенностями архитектуры рассматриваемого контента.
Архитектурный вопрос
Для начала рекомендуется разобраться, какова архитектура у приложений типа «веб». Она включает в себя клиентскую и серверную части. За счет этого в жизнь воплощается технология под названием «клиент-сервер».
Клиент отвечает за реализацию пользовательского interface. Также он формирует серверные запросы и обрабатывает ответы, получаемые от соответствующих «команд».
Серверная часть:
- получает заданный клиентом (юзером) запрос;
- производит необходимые вычисления;
- формирует веб-страничку для дальнейших манипуляций;
- производит отправку полученной страницы пользователю по Сети, используя протоколы HTTP.
Веб приложение может являться клиентом иных служб.: баз данных или иных утилит, хранящихся на тех или иных серверах. Пока удается привести один узнаваемый пример – Википедия и ее система управления. Здесь n-количество участников способны принимать участие в разработке сетевой энциклопедии. Работа ведется посредством браузеров. Дополнительные исполняемые модули не загружаются.
Веб-сервер – это…
Перед тем, как писать собственный контент, надо хорошо разбираться в том, какие процессы будут происходить внутри программы. Особенно тогда, когда речь заходит о создании утилит для работы с Сетью.
Web Applications работают по принципу «клиент-сервер». Но не совсем понятно, что такое server, как он реализован. Даже сложные и глобальные проекты будут функционировать по примерно одному и тому же принципу.
Веб-сервер – своеобразный сервер, который принимает HTTP-запросы от клиента, а затем выдает соответствующие ответы. Специальное программное обеспечение, которое выполняет функции веб-server. Может быть выражен «железом» с ПО для взаимодействия с Сетью.
Web Servers, как сказано в Google, обладают дополнительным функционалом. Примеры:
- автоматизация работы страничек в Сети;
- авторизация и аутентификация пользователей;
- поддержка страниц, которые генерируются динамически;
- возможность поддержки HTTPS для защищенных соединений;
- ведение журнала пользовательских обращений к тем или иным ресурсам.
Вариантов веб-серверов очень много. Это говорит о том, что данное направление является весьма перспективным. Вот примеры самых популярных веб-серверов:
- Apache;
- Nginx;
- Microsoft IIS.
Выбрать можно вариант, который пользователю кажется наиболее удобным.
Сервер приложений
Java, как и любой другой язык программирования, непрестанно совершенствуется. Для того, чтобы написать любое приложение, сначала необходимо изучить максимум информации о процессах и ресурсах, которые могут потребоваться в процессе реализации задачи.
В случае с веб утилитами (не только на Java) важно разграничивать сервера и сервера приложений. Это два разных элемента.
Application Server – утилита, представленная сервером. Последний занимается системной поддержкой программ, а также отвечает за обеспечение жизненных циклов в соответствие с установленными принципами работы. Функционирует или самостоятельно, или выступает в качестве поставщика страниц для иных web-servers. Отвечает за обмен информации между софтом и клиентами. Создает программную среду для итогового приложения, помогает авторизовывать и идентифицировать клиентов, организовывает сессии для каждого «подключившегося».
Вот несколько распространенных серверов утилит на Java:
- Tomcat Apache;
- JBoss;
- IBM WebSphere;
- Oracle WebLogic.
Веб-сервер имеет отношение преимущественно к способу передачи данных. Если говорить об Application Server, можно сделать вывод о том, что это – более узкое понятие. Относится к способу исполнения программ (удаленная обработка клиентских команд). В одном ряду соответствующие термины не размещаются. Они отвечают за совершенно разные признаки софта.
Серверные технологии
Java, как и любой другой язык программирования, позволяет создавать уникальный контент. Если он относится к типу «веб», предстоит сначала разобраться в технологиях, используемых для запуска софта и обработки информации. У Джавы их несколько. Выбирать стоит в зависимости от того, для чего конкретно пишется программа.
Технология AJAX
AJAX – это асинхронный JavaScript и XML. Технология, которую можно считать относительно новой. При ней утилита не будет перезагружаться полностью. Для обновления информации осуществляется подгрузка недостающих/новых сведений. Это значительно ускоряет работу и упрощает ее.
AJAX в основном используется при интерактивных пользовательских интерфейсах. Обмен данными «браузер-сервер» протекает в фоновом режиме. Описать данный процесс можно так:
- Юзер открывает страничку в интернете.
- Происходит взаимодействие с тем или иным элементом.
- Скрипт JS определяет, какие данные нужны для обновления.
- Браузер отправляет соответствующий запрос на веб-сервер.
- Последний отвечает за возврат документа, на которую посылался запрос.
- Скрипт корректирует страницу с учетом полученных данных.
Вообще, принцип работы базируется на двух вариантах. Каждый обладает своими нюансами.
Динамическое обращение
Первый вариант развития событий – это технология динамического обращения к серверам «на лету» посредством динамического создания:
- фреймов дочернего характера;
- тегов <script>;
- тегов <img>.
После применения данных технологий происходит функционирование без перезагрузки всей страницы целиком. Это – относительно быстрое решение поставленной задачи.
Второй подход – задействование DHTML для динамического корректирования информации на страничке.
Что включает в себя AJAX
При составлении кода утилиты и изучении материалов о принципах работы веб-софта нужно уяснить – AJAX не является самостоятельной технологией. Она включает в себя следующие методы реализации:
- HTML и CSS – для того, чтобы подавать и стилизировать электронные материалы;
- DOM-модели – в ответе за динамическое отображение и взаимодействие с соответствующими сведениями через JS;
- XMLHttpRequest или иные транспорты (Iframe, SCRIPT-теги и так далее) – асинхронизированый обмен материалами с web server;
- JSON или иной формат соответствующего характера (форматированные HTML, тестовые «вариации», XML) – обмен информацией.
Фактически AJAX – это концепция применения сразу нескольких технологий серверного характера.
Технологии WebSocket
WebSoket – еще один популярный нынче вариант. Стараясь разобраться в теме веб-приложений перед написанием оного, важно осознавать, какие технологии будут применяться в том или ином случае.
WebSoket – протокол полнодуплексной связи, накладываемый поверх TCP-соединения. Он предназначается для того, чтобы сервер обменивался данными с интернет-обозревателем в режиме реального времени, «здесь и сейчас». Комментарии тут излишни.
Достаточно запомнить, что данный вариант предусматривает две URI схема:
- ws: – нешифрованное соединение;
- wss: — шифрованный «коннектинг».
Технология не требует постоянных запросов клиент-сервер. В процессе реализации всегда создается двунаправленное соединение. Данные с server могут отправляться к client без запроса от оного.
А что о CGI?
Создавая приложение на Джаве, программист должен предварительно изучить возможные технологии работы веб-утилит. Есть вариант CGI. Это – низкоуровневый вариант. Стандарт, который использует интерфейс. Последний задействуется для связи внешней программы с сервером.
CGI обладает хорошей реализацией. Там можно использовать практически любой язык программирования, а не просто Java или JavaScript. Соответствующий вариант имеет следующие плюсы и минусы:
- универсален за счет отсутствия требований к платформам;
- позволяет использовать тот язык программирования, который хотим;
- CGI – это готовый к запуску файл, что делает затрудненным расширение системы.
Все это заставило программистов развиваться в технологиях работы с серверными каналами. Теперь существуют более совершенные «версии» технологий.
Java Servlet
Сервлет относится к «методикам» Java. Сочетает в себе особенности API и CGI. Помогает разобраться с производительностью, так как все запросы будут выполняться в едином потоке в одном и том же процессе. Сервлеты не имеют никакой зависимости от платформы.
Servlet – это класс Java, который выполняется внутри Джава VM:
- Контейнер веб-утилиты вида Tomcat начинает загрузку сервлета. Это происходит при первом обращении или в процессе запуска сервера согласно установленным конфигурационным параметрам.
- Servlet загружается и остается в подобном состоянии до тех пор, пока не будет произведена явная выгрузка.
- Возможно отключение посредством остановки контейнера.
Java Servlets имеет программный интерфейс, позволяющий вести обработку запросов на низком уровне. Обработка ведется в едином процессе посредством создания потоков внутри. Код предстоит составлять так, чтобы он был безопасным.
JSP – нюансы
Еще один вариант, применяемый для приложений, написанных на Джаве – это JSP. Разработка здесь больше не требует особых временных затрат. Связано это с тем, что программисту предстоит работать с шаблонами.
JSP – шаблоны страничек, похожих на ASP и PHP. Привязки к ПО и аппаратным платформам нет. Производительность ограничена:
- странички нужно компилировать в сервлеты, но только при первом обращении;
- servlets обрабатываются в JVM.
Основная нагрузка при реализации за счет кластеризации переходит на аппаратное обеспечение.
PHP – что такое?
PHP – распространенный «формат», который используют многие сервисы и приложения. Обладает высоким уровнем безопасности. Основывается на принципе построения страничек по шаблонам.
PHP-страницы – это обычные HTML, включающие в себя особые тэги. Каждый такой элемент виден сразу. Он имеет форму <?php?>.



Орфографический словарь русского языка (онлайн)
Как пишется слово «веб-приложение» ?
Правописание слова «веб-приложение»
А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я
веб-приложе́ние, -я
Рядом по алфавиту:
веб-ма́стер , -а
веб-ма́стеринг , -а
веб-навига́тор , -а
веб-навигацио́нный
веб-навига́ция , -и
веб-обновле́ние , -я
веб-обозрева́тель , -я
веб-обозре́ние , -я
веб-объе́кт , -а
веб-пали́тра , -ы
веб-па́пка , -и, р. мн. -па́пок
веб-по́чта , -ы
веб-представи́тельство , -а
веб-приложе́ние , -я
веб-приста́вка , -и, р. мн. -вок
веб-программи́рование , -я
веб-программи́ст , -а
веб-прое́кт , -а
веб-простра́нство , -а
веб-публика́ция , -и
веб-разрабо́тка , -и, р. мн. -ток
веб-разрабо́тчик , -а
веб-редакти́рование , -я
веб-реда́ктор , -а
веб-реда́кция , -и
веб-ресу́рс , -а
веб-реше́ние , -я
веб-ры́нок , -нка
веб-са́йт , -а
вебло́г , -а
вебме́йкер , -а
Архитектура Web-приложений
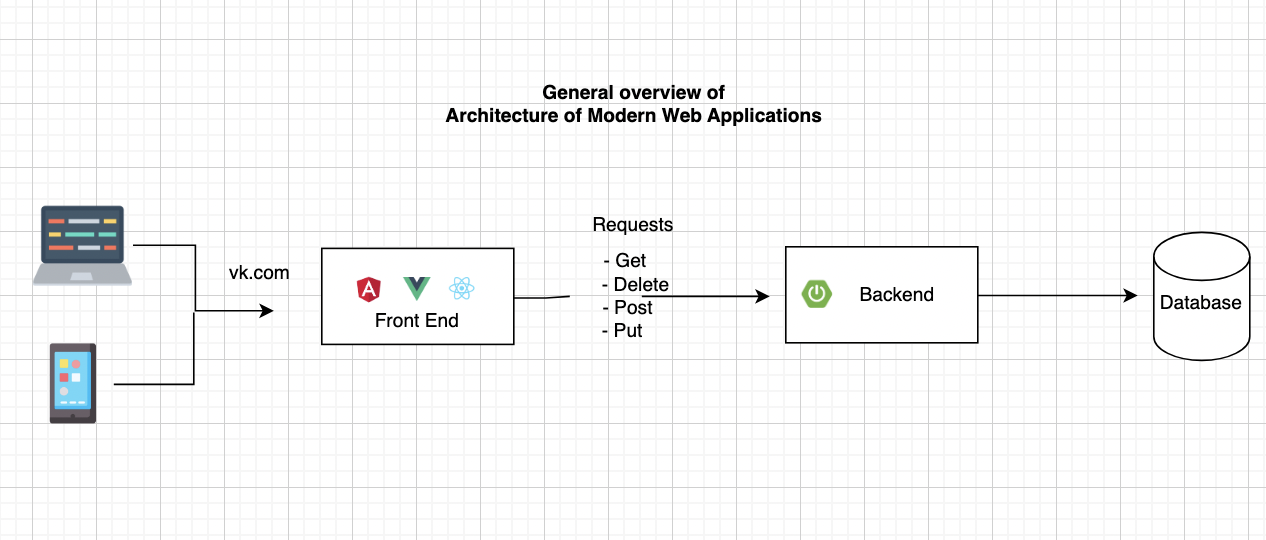
Архитектура современных приложений состоит из отдельных модулей, как показано на рисунке выше. Эти модули часто называют Frontend и Backend. Frontend – это модуль, который отвечает за юзер-интерфейс и логику, которые предоставляется приложением при использовании. Так, например когда мы заходим в соцсети через браузер, мы взаимодействуем именно с FrontEnd-модулем приложения. То, как отображаются наши посты в виде сторисов или карточек, сообщения и другие активности реализуются именно в FrontEnd-модуле. А все данные, которые мы видим, хранятся и обрабатываются в Backend или серверной части приложения. Эти модули обмениваются между собой посредством разных архитектурных стилей: REST, GRPC и форматов сообщений – JSON и XML.
В этой статье мы напишем примитивную серверную часть социальной сети с использованием Spring Boot, запустим свой сервер, рассмотрим разные типы HTTP запросов и их применение.
Необходимое требование к читателю: умение писать на Java и базовые знания Spring Framework. Данная статья познакомит вас со Spring Boot и даст базовые понятия данного фреймворка.
Инициализация проекта
Чтобы создать Spring Boot проект, перейдем на страницу https://start.spring.io/ и выберем необходимые зависимости: в нашем случае Spring Web. Чтобы запустить проект, необходима минимальная версия Java 17. Скачиваем проект и открываем в любом IDE (в моем случае – Intellij Idea)
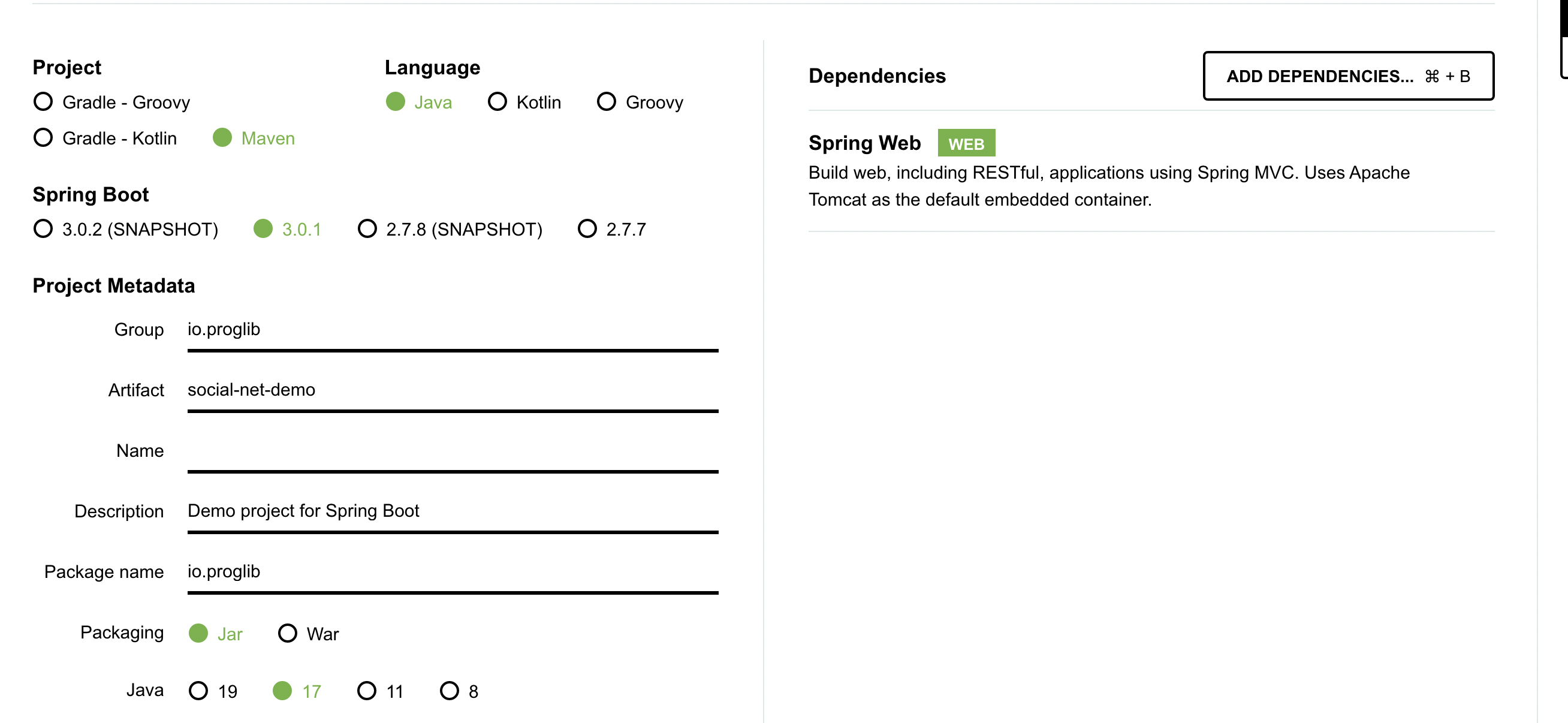
Spring Web – зависимость, которая предоставляет контейнер сервлетов Apache Tomcat (является дефолтным веб-сервером). Проще говоря, сервлеты – это классы, которые обрабатывают все входящие запросы.
Открываем проект и запускаем.
Мы видим, что проект запустился и готов обрабатывать запросы на порту 8080 – Tomcat started on port(s): 8080 (http).
Теперь создадим свой первый класс – GreetingController. Controller-классы ответственны за обработку входящих запросов и возвращают ответ.
Чтобы сделать наш класс Controller, достаточно прописать аннотацию @RestController. @RequestMapping указывает, по какому пути будет находиться определённый ресурс или выполняться логика.
package io.proglib;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet() {
return "Hello";
}
}
Перезапускаем проект, и сервер готов уже обрабатывать наши запросы.
Открываем браузер по адресу http://localhost:8080/greet и получаем следующий вывод.
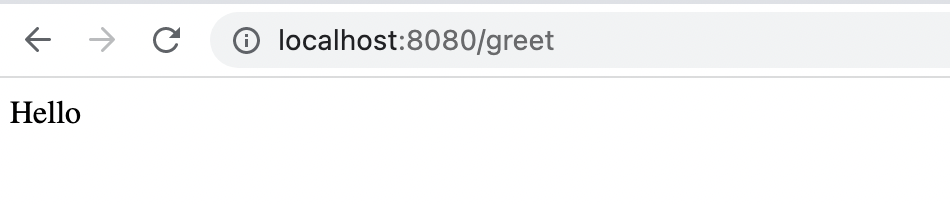
Если отправить запрос по адресу http://localhost:8080/ , мы получим ошибку, т. к. по этому пути не определены логика обработки запроса и ресурсы.
Request Params
При отправке запросов мы часто используем переменные в запросе, чтобы передавать дополнительную информацию или же делать запросы гибкими. Параметр в запросе передаётся в конце адреса (=url) сервера и указывается после вопросительного знака (=?).
Например, http://localhost:8080/greet?name=Alice. Параметр запроса является = name cо значением = Alice.
Чтобы обрабатывать переменную запроса, используется аннотация @RequestParam. Параметры запроса могут быть опциональными или же обязательными. @RequestParam("name") означает следующее: взять ту переменную из запроса, название которого равно name.
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
}
Вдобавок, запрос может содержать несколько параметров.
Например, http://localhost:8080/greet/full?name=John&surname=Smith. Параметры выделяются знаком &. В этом запросе два параметра: name=John и surname=Smith.
Чтобы обработать каждый параметр запроса, нужно пометить каждую переменную @RequestParam.
package io.proglib;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
@GetMapping("/full")
public String fullGreeting(@RequestParam("name") String name,
@RequestParam("surname") String surname) {
return "Nice to meet you, " + name + " " + surname;
}
}

Path Variable
PathVariable по применению похож на @Request Param. @PathVariable также является параметром запроса, но используются внутри адреса запроса. Например,
RequestParam – http://localhost:8080/greet/full?name=John&surname=Smith PathVariable – http://localhost:8080/greet/John. В этом случае John является PathVariable.
В запросе можно указывать несколько PathVariable, как и в случае RequestParam
package io.proglib;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
@GetMapping("/full")
public String fullGreeting(@RequestParam("name") String name, @RequestParam("surname") String surname) {
return "Nice to meet you, " + name + " " + surname;
}
@GetMapping("/{name}")
public String greetWithPathVariable(@PathVariable("name") String name) {
return "Hello, " + name;
}
}
Чтобы протестировать, открываем браузер и переходим по адресам: http://localhost:8080/greet/John/Smith и http://localhost:8080/greet/John

Запрос с двумя параметризованными PathVariable.

HTTP-методы
Когда мы говорим о запросах, мы также подразумеваем HTTP-метод, который используется при отправке этого запроса. Каждый запрос представляет собой некий HTTP-метод. Например, когда мы переходим в браузере по адресу http://localhost:8080/greet/John/Smith, наш браузер отправляет GET-запрос на сервер.
Большая часть информационных систем обмениваются данными посредством HTTP-методов. Основными HTTP-методами являются – POST, GET, PUT, DELETE. Эти четыре запроса также называют CRUD-запросами.
- POST-метод – используется при создании новых ресурсов или данных. Например, когда мы загружаем новые посты в соцсетях, чаще всего используется POST-запросы. POST-запрос может иметь тело запроса.
- GET-метод – используется при получении данных. Например, при открытии любого веб-приложения, отправляется именно GET-запрос для получения данных и отображения их на странице. GET-запрос не имеет тела запроса.
- PUT-метод – используется для обновления данных, а также может иметь тело запроса, как и POST.
- DELETE-метод – используется для удаления данных.
Реализация основных методов
Давайте создадим сущности и реализуем методы, чтобы наш сервер принимал все четыре запроса. Для этого создадим сущности User и Post, и будем проводить операции над ними.
Для простоты User имеет только два поля: username и список постов posts, а сущность Post имеет поле description и imageUrl.
Сущность User:
package io.proglib;
import java.util.ArrayList;
import java.util.List;
public class User {
private String username;
private List<Post> posts;
public User() {
posts = new ArrayList<>();
}
public User(String username, List<Post> posts) {
this.username = username;
this.posts = posts == null ? new ArrayList<>() : posts;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public List<Post> getPosts() {
return posts;
}
public void setPosts(List<Post> posts) {
this.posts = posts;
}
}
Сущность Post:
package io.proglib;
public record Post(
String description,
String imageUrl
) {
}
Создаем новый класс контроллер – UserActivityController, который будет обрабатывать наши запросы – POST, GET, PUT, DELETE.
Наш контроллер: UserActivityController.
Будем использовать список – List<User> users в качестве локальной базы данных, где будем хранить все наши данные.
package io.proglib;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/users")
public class UserActivityController {
private final static List<User> users = new ArrayList<>();
}
POST-запрос: добавление нового пользователя
Чтобы указать, что метод принимает POST-запросы используем аннотацию – @PostMapping. Так как запрос имеет тело запроса, где мы передаем пользователя, нужно пометить переменную user аннотацией @RequestBody.
@PostMapping("")
public User addUser(@RequestBody User user) {
users.add(user);
return user;
}
GET-запрос: получение пользователей
@GetMapping("")
public List<User> getUsers() {
return users;
}
@GetMapping("/{username}")
public User getUserByUsername(@PathVariable("username") String username) {
return users.stream().filter(user -> user.getUsername().equals(username))
.findFirst().get();
}
@Getmapping("") указывает, что методы обрабатывают GET-запросы. Значение, которое передаётся внутри аннотации, является частью url или адреса. Например, запрос http://localhost:8080/users/baggio обработается методом getUserByUsername(), а запрос http://localhost:8080/users/ обработается методом http://localhost:8080/users.
PUT-запрос: обновление данных
@PutMapping("/{username}")
public Post update(@PathVariable("username") String username, @RequestBody Post post) {
users.stream().filter(user ->
user.getUsername().equals(username))
.findAny()
.ifPresent(user -> user.getPosts().add(post));
return post;
}
@PutMapping("/{username}") указывает, что метод принимает PUT-запросы. В нашем примере в запросе мы передаем параметр запроса, а также тело запроса – post. Метод принимает – username, ищет юзера из списка с таким username и добавляем новый пост к его списку постов.
Delete-запрос: удаление данных
@DeleteMapping("/{username}")
public String deleteUser(@PathVariable("username") String username) {
users.stream().filter(user ->
user.getUsername().equals(username))
.findAny()
.ifPresent(users::remove);
return "User with username: " + username + " has been deleted";
}
@DeleteMapping("/{username}") – указывает, что метод принимает DELETE-запросы.
Данный метод получает параметр username из запроса и удаляет из списка пользователя с таким username.
Запуск приложения и тестирование
Чтобы убедиться, что все работает, мы можем отправить каждый вид запроса и протестировать. Для этого нам необходим API-client, который может посылать запросы. В примерах я использую POSTMAN.
Post-запрос: создание нового пользователя.
Тело запроса отправляется в виде JSON.
GET-запрос: получение пользователей
PUT-запрос: обновление списка постов пользователя
DELETE-запрос: удаление пользователя по username
***
В этой статье мы рассмотрели архитектуру современных web-приложений, а также написали свою серверную часть приложения, получив поверхностные знания по Spring Boot, HTTP запросы и параметры запросов.
Ссылка на репозиторий
Исходный код можно найти по ссылке.
Материалы по теме
- ☕ Сертификаты и тренинги для Java-разработчика
- ☕🛣️ Дорожная карта Java-разработчика в 2023 году: путь с нуля до первой работы
#статьи
- 3 авг 2022
-

0
Разберёмся в том, как устроен фреймворк Django, как он работает, и напишем своё первое приложение.
Иллюстрация: rawpixel.com / Freepik / mulyadi / Sebastian Dumitru / Unsplash / Дима Руденок для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Django — это фреймворк для веб-разработки, написанный на Python в 2005 году. Он позволяет создавать сайты и веб-приложения разной сложности — от личного блога до аудиоплатформы (на нём собран Spotify). От других фреймворков Django отличается модульностью и простотой освоения.
В этой статье мы увидим, как создавать веб-приложения на Django: рассмотрим его структуру и напишем первое веб-приложение — движок для блога, который умеет публиковать и редактировать записи. Это первая часть урока по Django — во второй мы будем настраивать админку и подтюним внешний вид наших постов.
Согласно исследованию Stack Overflow за 2022 год, Django занимает девятое место среди всех веб-фреймворков, обгоняя, например, популярные Spring и Ruby on Rails.
Скриншот: Stack Overflow
На Django работают многие известные сервисы — например, «Инстаграм»*, Pinterest, Spotify, Last.fm и сайт Mozilla. Однако его используют не только в энтерпрайзе: нередко на нём собирают личные сайты: блоги, фотогалереи, портфолио и так далее.
Одно из главных преимуществ Django — принцип DRY (don’t repeat yourself): единожды написанный код можно повторно использовать в различных проектах. Поэтому Django часто сравнивают с конструктором Lego.
Кроме принципа DRY Django имеет и другие преимущества:
- понятый и простой синтаксис (он написан на Python);
- большое количество готовых шаблонов и модулей, которые облегчают разработку и позволяют не использовать внешние библиотеки или расширения. Это помогает избегать конфликтов между ними после обновлений;
- подробная документация и большое комьюнити. Если у вас появился какой-то вопрос о коде, то вы легко найдёте на него ответ на Stack Overflow или других сайтах.
Фреймворк основывается на четырёх главных компонентах:
- Модели (Models) — взаимодействуют с базой данных и достают из неё ту информацию, которую необходимо отобразить в браузере.
- Представления (Views) — обрабатывают запрос и обращаются к модели, сообщая ей, какую информацию необходимо достать из базы данных.
- Шаблоны (Templates) — показывают, каким именно образом необходимо показать информацию, полученную из базы данных.
- URL-маршруты (URL dispatcher) — перенаправляют HTTP-запрос от браузера в представления.
Сейчас структура может казаться запутанной, но на самом деле она простая — мы разберёмся с ней на практике, и вы быстро всё поймёте.
Прежде чем перейти к установке Django и virtualenv, необходимо убедиться в том, что у вас уже установлен Python. Проверить это и узнать версию Python можно с помощью терминала. Откройте Terminal в своей IDE или операционной системе и введите команду:
% python --version
Если Python установлен, то терминал покажет его версию:

Если же Python не установлен, то можно воспользоваться другим нашим руководством. После этого переходим к настройке виртуального окружения.
Виртуальное окружение, создаваемое с помощью virtualenv, — это специальный инструмент, который помогает управлять зависимостями и изолировать проекты друг от друга: например, устанавливать дополнительные библиотеки и пакеты локально для каждого проекта, а не глобально для всего компьютера. Установить virtualenv тоже можно через терминал:
% sudo pip3 install virtualenv
После этого необходимо создать директорию для проекта, внутри которой мы развернём виртуальное окружение:
% mkdir blog % cd blog
С помощью команды mkdir мы создаём папку blog, а благодаря команде cd в терминале переходим в неё. Теперь папка blog — это каталог, где мы организуем виртуальное окружение и будем хранить все наши файлы, связанные с нашим проектом Django.
Развернём виртуальное окружение внутри папки development:
% virtualenv venv -p python3
Теперь его необходимо активировать, иначе оно не будет работать:
% source venv/bin/activate
После активации виртуального окружения мы увидим результат в самом терминале. Обратите внимание, что во второй строке команда теперь начинается с (venv), а не с (base), как раньше:

Сам фреймворк Django тоже устанавливается с помощью терминала:
% pip install django
Результат установки:
В последней строке видно, что установка прошла успешно. При этом мы установили не только Django последней версии, но и ещё две библиотеки:
- asgiref — интерфейс для взаимодействия с асинхронными веб-сервисами, платформами и приложениями на Python;
- sqlparse — простой парсер для работы с базами данных SQL.
Итак, убедитесь, что вы сделали всё по чек-листу:
- проверили, что у вас есть Python;
- создали директорию и развернули в ней виртуальное окружение с помощью virtualenv;
- установили в ту же папку Django.
Теперь можно переходить к созданию самого проекта.
Разобраться в основных понятиях фреймворка Django лучше всего на практике. Напишем веб-приложение для небольшого блога с текстовыми записями и поговорим про его работу. Весь процесс разобьём на семь простых шагов — да здравствует модульность 
Готовим и настраиваем окружение
Проще всего создать базовую структуру проекта с помощью терминала:
% django-admin startproject blog .
Очень важно не забыть точку в конце команды — она указывает на то, что проект создаётся в текущей папке без необходимости создания нового каталога. Если точку не поставить, то ничего не произойдёт и терминал выдаст ошибку.
Если всё прошло хорошо, то Django создаст в нашей директории blog файл manage.py, управляющий выполнением всех задач в терминале, и папку blog с пятью файлами:
Мы не будем подробно обсуждать предназначение каждого из этих файлов — не все из них нам надо будет редактировать. Если вам интересны подробности, просто откройте файлы, в шапке каждого из них будет написано, для чего он нужен.
Теперь нам надо продумать, где мы станем хранить записи блога. Для этого потребуется создать базу данных. Django может работать с различными базами данных, но по умолчанию работает с SQLite. Её нам будет достаточно — у нас всего один пользователь и простая структура записей.
Самое приятное — можно создать базу данных SQLite с помощью одной команды.
% python manage.py migrate
И всё. Если посмотреть в каталог проекта, вы увидите, что там появился файл db.sqlite3. Это и есть наша база данных.
Для работы с нашим блогом необходимо создать суперпользователя, обладающего возможностями администратора. Сделать это можно с помощью простой команды:
% python manage.py createsuperuser
После выполнения команды терминал попросит ввести имя пользователя, email и установить пароль. Запомните их — они нам ещё понадобятся.
Ещё одна команда, которой мы будем часто пользоваться — runserver. Она запускает веб-сервер для разработки:
% python manage.py runserver
По умолчанию сервер запускается на порту 8000 по адресу 127.0.0.1 и доступен только на вашем компьютере. Порт и IP-адрес можно указать самостоятельно, но сейчас это нам не нужно.
Когда сервер запущен, вы можете открыть проект Django в браузере, введя http://127.0.0.1:8000 или http://localhost:8000. Если все предыдущие этапы выполнены правильно, вы увидите приветственное окно Django:
Завершим настройку нашего проекта и перейдём на страницу администрирования http://localhost:8000/admin. В форме введём имя и пароль суперпользователя, которые мы задали в предыдущем пункте. В результате нам откроется панель администратора:
Панель администратора позволяет управлять контентом и пользователями сайта. Она понадобится нам на следующих этапах создания блога.
Проект Django содержит одно или несколько приложений. Вначале можно запутаться между понятиями «проект» и «приложение», но разница между ними простая:
- Приложение — это модуль нашего проекта. Оно может быть связано с конкретными функциями или группой пользователей. Например, если бы мы создавали социальную сеть, то сделали бы отдельные приложения для обычных пользователей, владельцев групп и модераторов контента.
- Проект — это вся наша программа в целом. Она может состоять из одного приложения (именно так будет у нас) или из нескольких.
Разделение функций проекта по разным приложениям позволяет легко использовать единожды написанный код в разных проектах, быстро добавляя нужную функциональность.
В нашем случае нам достаточно хранить и отображать текстовые заметки, поэтому мы обойдёмся одним приложением. Назовём его entries. Прежде чем создать его, необходимо остановить работу сервера с помощью команды в терминале. Для этого нажмём комбинацию клавиш Ctrl + C в Windows или Control + C в macOS.
Теперь создадим само приложение:
% python manage.py startapp entries
Эта команда создаст папку entries в проекте blog с набором предопределённых файлов (помните, что все эти команды терминала необходимо вводить в папке проекта). С некоторыми из них мы поработаем позже.
Пока что Django не видит созданное приложение entries. Чтобы его подключить, необходимо добавить название приложения в конец списка INSTALLED_APPS в файл blog/settings.py:
# Открываем файл blog/settings.py и добавляем в конец списка запись. INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'entries.apps.EntriesConfig', ]
Теперь приложение entries подключено к нашему проекту и Django видит его конфигурации. Одна из этих конфигураций — та самая модель, которая описывает, как записи блога должны выглядеть в базе данных.
После создания базы данных необходимо создать для неё таблицу, в которой будут храниться записи блога. В Django это делается с помощью класса Models. Как и обычные классы в Python, имена моделей принято задавать в единственном числе, и начинаться они должны с заглавной буквы. Так как наше приложение называется entries, модель будет называться Entry.
Поля Entry — это элементы, которыми будет обладать любая запись в блоге. На самом сайте они будут показаны в виде полей формы, а в базе данных — столбцами. У записи в блоге будет три элемента:
- title — заголовок;
- content — основной текст;
- date_created — дата и время создания.
В файле entries/models.py сначала импортируем модуль timezone из django.utils, а затем создадим класс Entry (в комментариях поясняется, за что отвечает тот или иной кусочек кода):
from django.db import models from django.utils import timezone class Entry(models.Model): # Создаём новый класс, который будет служить для блога моделью, указывая все необходимые элементы. title = models.CharField(max_length=200) content = models.TextField() date_created = models.DateTimeField(default=timezone.now) def __str__(self): # С помощью функции меняем то, как будет представлена запись в модели. return self.title # Указываем, что она будет идентифицироваться с помощью своего заголовка. class Meta: verbose_name_plural = "Entries" # Указываем правильное написание для множественного числа слова Entry.
После импорта модуля timezone мы можем использовать параметр timezone.now в качестве аргумента по умолчанию для date_created. Теперь при создании новой записи не придётся вручную указывать время и дату. Это пригодится нам позже, когда мы будем создавать форму для создания постов.
В дополнение к title, content и date_created Django автоматически добавит id как уникальный первичный ключ для всех записей. Строковое представление записи с первичным ключом 1 по умолчанию будет Entry object (1). Добавив функцию __str__(), мы настраиваем то, что будет отображаться вместо этой нумерации. Так как мы создаём блог, то лучше идентифицировать запись с помощью заголовка.
Ещё одна переменная, которую необходимо настроить вручную, — это verbose_name_plural. Если этого не сделать, то Django будет неправильно указывать множественное число Entry как Entrys (нам надо Entries).
Чтобы наша модель Entry отображалась в панели администрирования Django, регистрируем её в файле entries/admin.py:
from django.contrib import admin from .models import Entry admin.site.register(Entry) # Регистрируем модель.
Если этого не сделать, то Django не выдаст ошибку, однако при работе с блогом возможности управлять моделью через панель администратора уже не будет, а это неудобно.
После добавления нового класса и его регистрации в панели администратора необходимо создать файлы миграции для Django и запустить их. Создаются они с помощью команды makemigrations, а реализуются через команду migrate. Обе команды пишем в терминале:
python manage.py makemigrations python manage.py migrate
После завершения миграции переходим в панель администратора http://localhost:8000/admin. В ней появился раздел Entries с нашим приложением:
Сейчас в этом разделе нет никаких записей. Можно добавить их вручную, нажав Add. Однако удобнее реализовать добавление новых записей в блог через пользовательский интерфейс, а не панель администратора. Но это мы сделаем в следующей части статьи — следите за анонсами в Telegram-канале «Люди и код» и подписывайтесь на нашу рассылку, чтобы не пропустить.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: Python-фреймворк Django
Узнать больше