Кратчайшее введение в создание компилятора
Давайте сделаем компилятор арифметических выражений. Такой, который переведет исходный текст в обратной польской форме записи (ее еще называют RPN или ПОЛИЗ) в промежуточный код стековой машины. Но у нас не будет интерпретатора стекового кода, как вы, возможно, могли подумать. Далее мы сразу переведем результат в представление на языке Си. То есть у нас получится компилятор RPN в Си.
Кстати говоря, писать компилятор мы будем на Python. Но пусть это не останавливает тех, кто предпочитает какой-то иной язык программирования. Вот вам полезное упражнение: переведите приведенный код на ваш любимый язык. Или воспользуйтесь уже готовым переводом:
Реализация на F# (автор gsomix):
первая версия,
SSA-версия
Начнем с синтаксического анализа
def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens]
Что мы здесь сделали? Функция scan получает от пользователя строку в обратной польской форме записи («2 2 +»).
А на выходе мы получаем промежуточное представление. Вот такое, например:
[('Push', 2), ('Push', 2), ('Op', '+')]
Итак, мы уже получили компилятор. Но уж очень он несерьезный. Вспомним, что изначально речь шла о коде на Си.
Займемся трансляцией в Си
def trans(ir): code = [] for (tag, val) in ir: if tag == 'Push': code.append('st[sp] = %d;' % val) code.append('sp += 1;') elif tag == 'Op': code.append('st[sp - 2] = st[sp - 2] %s st[sp - 1];' % val) code.append('sp -= 1;') return 'n'.join(code)
Что здесь происходит? Давайте посмотрим на вывод данной функции (на том же примере с «2 2 +»).
st[sp] = 2; sp += 1; st[sp] = 2; sp += 1; st[sp - 2] = st[sp - 2] + st[sp - 1]; sp -= 1;
Да, это уже похоже на код на Си. Массив st играет роль стека, а sp — его указатель. Обычно с этими вещами работают виртуальные стековые машины.
Вот только самой машины — интерпретатора у нас-то и нет. Есть компилятор. Что нам осталось? Надо добавить необходимое обрамление для программы на Си.
Наш первый компилятор в готовом виде
ST_SIZE = 100 C_CODE = r"""#include <stdio.h> int main(int argc, char** argv) { int st[%d], sp = 0; %s printf("%%dn", st[sp - 1]); return 0; }""" def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens] def trans(ir): code = [] for (tag, val) in ir: if tag == 'Push': code.append('st[sp] = %d;' % val) code.append('sp += 1;') elif tag == 'Op': code.append('st[sp - 2] = st[sp - 2] %s st[sp - 1];' % val) code.append('sp -= 1;') return 'n'.join(code) def rpn_to_c(source): return C_CODE % (ST_SIZE, trans(scan(source))) print rpn_to_c('2 2 +')
Остается скомпилировать вывод данной программы компилятором Си.
Вы все еще готовы продолжать? Тогда давайте обсудим, что у нас получилось. Есть один сомнительный момент — наш компилятор транслирует константные выражения, а ведь их можно вычислить просто на этапе компиляции. Нет смысла переводить их в код. Но давайте пока считать, что какие-то аргументы могут попасть в стек извне. Например, из аргументов командной строки. Остановимся на том, что практический смысл нашей разработке можно придать и позднее. Сейчас же важно получить общее представление о построении простейших компиляторов, верно?
Компилятор с использованием формы SSA
Вам нравится заголовок? SSA — это звучит очень солидно для любого компиляторщика. А мы уже сейчас будем использовать эту самую SSA. Что это такое? Давайте двигаться по порядку.
Мы генерируем в данный момент код на Си, безо всяких виртуальных машин. Но зачем нам тогда рудимент в виде операций со стеком? Давайте заменим эти операции работой с обычными переменными из Си. Причем, мы не будем экономить переменные — для каждого выражения заведем новое имя. Пусть компилятор Си сам со всем этим разбирается. Получается, что у нас каждой переменной значение присваивается лишь однажды. А это, кстати говоря, и есть форма SSA.
Вот наш новый компилятор.
C_CODE = r"""#include <stdio.h> int main(int argc, char** argv) { %s printf("%%dn", %s); return 0; }""" def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens] def trans(ir): (stack, code) = ([], []) name_cnt = 0 for (tag, val) in ir: if tag == 'Push': code.append('int t%d = %d;' % (name_cnt, val)) stack.append('t%d' % name_cnt) name_cnt += 1 elif tag == 'Op': (a, b) = (stack.pop(), stack.pop()) code.append('int t%d = %s %s %s;' % (name_cnt, b, val, a)) stack.append('t%d' % name_cnt) name_cnt += 1 return ('n'.join(code), stack.pop()) def rpn_to_c(source): return C_CODE % trans(scan(source)) print rpn_to_c('2 2 +')
Обратите внимание — стека в коде на Си уже нет, а работа с ним имитируется в процессе трансляции. На стеке, который используется в процессе компиляции, содержатся не значения, а имена переменных.
Вот окончательный результат:
#include <stdio.h> int main(int argc, char** argv) { int t0 = 2; int t1 = 2; int t2 = t0 + t1; printf("%dn", t2); return 0; }
Похоже, пришла пора расширять возможности нашего входного языка, как вы считаете? И двигаться, на мой взгляд, здесь можно в направлении стековых языков, таких как Forth, Postscript, Joy или Factor. Конечно же, можно и пойти путем усложнения входного синтаксиса. Но все эти вопросы давайте оставим для следующих заметок. Успехов в построении компиляторов!
Intro
A typical compiler does the following steps:
- Parsing: the source text is converted to an abstract syntax tree (AST).
- Resolution of references to other modules (C postpones this step till linking).
- Semantic validation: weeding out syntactically correct statements that make no sense, e.g. unreachable code or duplicate declarations.
- Equivalent transformations and high-level optimization: the AST is transformed to represent a more efficient computation with the same semantics. This includes e.g. early calculation of common subexpressions and constant expressions, eliminating excessive local assignments (see also SSA), etc.
- Code generation: the AST is transformed into linear low-level code, with jumps, register allocation and the like. Some function calls can be inlined at this stage, some loops unrolled, etc.
- Peephole optimization: the low-level code is scanned for simple local inefficiencies which are eliminated.
Most modern compilers (for instance, gcc and clang) repeat the last two steps once more. They use an intermediate low-level but platform-independent language for initial code generation. Then that language is converted into platform-specific code (x86, ARM, etc) doing roughly the same thing in a platform-optimized way. This includes e.g. the use of vector instructions when possible, instruction reordering to increase branch prediction efficiency, and so on.
After that, object code is ready for linking. Most native-code compilers know how to call a linker to produce an executable, but it’s not a compilation step per se. In languages like Java and C# linking may be totally dynamic, done by the VM at load time.
Remember the basics
- Make it work
- Make it beautiful
- Make it efficient
This classic sequence applies to all software development, but bears repetition.
Concentrate on the first step of the sequence. Create the simplest thing that could possibly work.
Read the books!
Read the Dragon Book by Aho and Ullman. This is classic and is still quite applicable today.
Modern Compiler Design is also praised.
If this stuff is too hard for you right now, read some intros on parsing first; usually parsing libraries include intros and examples.
Make sure you’re comfortable working with graphs, especially trees. These things is the stuff programs are made of on the logical level.
Define your language well
Use whatever notation you want, but make sure you have a complete and consistent description of your language. This includes both syntax and semantics.
It’s high time to write snippets of code in your new language as test cases for the future compiler.
Use your favorite language
It’s totally OK to write a compiler in Python or Ruby or whatever language is easy for you. Use simple algorithms you understand well. The first version does not have to be fast, or efficient, or feature-complete. It only needs to be correct enough and easy to modify.
It’s also OK to write different stages of a compiler in different languages, if needed.
Prepare to write a lot of tests
Your entire language should be covered by test cases; effectively it will be defined by them. Get well-acquainted with your preferred testing framework. Write tests from day one. Concentrate on ‘positive’ tests that accept correct code, as opposed to detection of incorrect code.
Run all the tests regularly. Fix broken tests before proceeding. It would be a shame to end up with an ill-defined language that cannot accept valid code.
Create a good parser
Parser generators are many. Pick whatever you want. You may also write your own parser from scratch, but it only worth it if syntax of your language is dead simple.
The parser should detect and report syntax errors. Write a lot of test cases, both positive and negative; reuse the code you wrote while defining the language.
Output of your parser is an abstract syntax tree.
If your language has modules, the output of the parser may be the simplest representation of ‘object code’ you generate. There are plenty of simple ways to dump a tree to a file and to quickly load it back.
Create a semantic validator
Most probably your language allows for syntactically correct constructions that may make no sense in certain contexts. An example is a duplicate declaration of the same variable or passing a parameter of a wrong type. The validator will detect such errors looking at the tree.
The validator will also resolve references to other modules written in your language, load these other modules and use in the validation process. For instance, this step will make sure that the number of parameters passed to a function from another module is correct.
Again, write and run a lot of test cases. Trivial cases are as indispensable at troubleshooting as smart and complex.
Generate code
Use the simplest techniques you know. Often it’s OK to directly translate a language construct (like an if statement) to a lightly-parametrized code template, not unlike an HTML template.
Again, ignore efficiency and concentrate on correctness.
Target a platform-independent low-level VM
I suppose that you ignore low-level stuff unless you’re keenly interested in hardware-specific details. These details are gory and complex.
Your options:
- LLVM: allows for efficient machine code generation, usually for x86 and ARM.
- CLR: targets .NET, multiplatform; has a good JIT.
- JVM: targets Java world, quite multiplatform, has a good JIT.
Ignore optimization
Optimization is hard. Almost always optimization is premature.
Generate inefficient but correct code. Implement the whole language before you try to optimize the resulting code.
Of course, trivial optimizations are OK to introduce. But avoid any cunning, hairy stuff before your compiler is stable.
So what?
If all this stuff is not too intimidating for you, please proceed! For a simple language, each of the steps may be simpler than you might think.
Seeing a ‘Hello world’ from a program that your compiler created might be worth the effort.
Intro
A typical compiler does the following steps:
- Parsing: the source text is converted to an abstract syntax tree (AST).
- Resolution of references to other modules (C postpones this step till linking).
- Semantic validation: weeding out syntactically correct statements that make no sense, e.g. unreachable code or duplicate declarations.
- Equivalent transformations and high-level optimization: the AST is transformed to represent a more efficient computation with the same semantics. This includes e.g. early calculation of common subexpressions and constant expressions, eliminating excessive local assignments (see also SSA), etc.
- Code generation: the AST is transformed into linear low-level code, with jumps, register allocation and the like. Some function calls can be inlined at this stage, some loops unrolled, etc.
- Peephole optimization: the low-level code is scanned for simple local inefficiencies which are eliminated.
Most modern compilers (for instance, gcc and clang) repeat the last two steps once more. They use an intermediate low-level but platform-independent language for initial code generation. Then that language is converted into platform-specific code (x86, ARM, etc) doing roughly the same thing in a platform-optimized way. This includes e.g. the use of vector instructions when possible, instruction reordering to increase branch prediction efficiency, and so on.
After that, object code is ready for linking. Most native-code compilers know how to call a linker to produce an executable, but it’s not a compilation step per se. In languages like Java and C# linking may be totally dynamic, done by the VM at load time.
Remember the basics
- Make it work
- Make it beautiful
- Make it efficient
This classic sequence applies to all software development, but bears repetition.
Concentrate on the first step of the sequence. Create the simplest thing that could possibly work.
Read the books!
Read the Dragon Book by Aho and Ullman. This is classic and is still quite applicable today.
Modern Compiler Design is also praised.
If this stuff is too hard for you right now, read some intros on parsing first; usually parsing libraries include intros and examples.
Make sure you’re comfortable working with graphs, especially trees. These things is the stuff programs are made of on the logical level.
Define your language well
Use whatever notation you want, but make sure you have a complete and consistent description of your language. This includes both syntax and semantics.
It’s high time to write snippets of code in your new language as test cases for the future compiler.
Use your favorite language
It’s totally OK to write a compiler in Python or Ruby or whatever language is easy for you. Use simple algorithms you understand well. The first version does not have to be fast, or efficient, or feature-complete. It only needs to be correct enough and easy to modify.
It’s also OK to write different stages of a compiler in different languages, if needed.
Prepare to write a lot of tests
Your entire language should be covered by test cases; effectively it will be defined by them. Get well-acquainted with your preferred testing framework. Write tests from day one. Concentrate on ‘positive’ tests that accept correct code, as opposed to detection of incorrect code.
Run all the tests regularly. Fix broken tests before proceeding. It would be a shame to end up with an ill-defined language that cannot accept valid code.
Create a good parser
Parser generators are many. Pick whatever you want. You may also write your own parser from scratch, but it only worth it if syntax of your language is dead simple.
The parser should detect and report syntax errors. Write a lot of test cases, both positive and negative; reuse the code you wrote while defining the language.
Output of your parser is an abstract syntax tree.
If your language has modules, the output of the parser may be the simplest representation of ‘object code’ you generate. There are plenty of simple ways to dump a tree to a file and to quickly load it back.
Create a semantic validator
Most probably your language allows for syntactically correct constructions that may make no sense in certain contexts. An example is a duplicate declaration of the same variable or passing a parameter of a wrong type. The validator will detect such errors looking at the tree.
The validator will also resolve references to other modules written in your language, load these other modules and use in the validation process. For instance, this step will make sure that the number of parameters passed to a function from another module is correct.
Again, write and run a lot of test cases. Trivial cases are as indispensable at troubleshooting as smart and complex.
Generate code
Use the simplest techniques you know. Often it’s OK to directly translate a language construct (like an if statement) to a lightly-parametrized code template, not unlike an HTML template.
Again, ignore efficiency and concentrate on correctness.
Target a platform-independent low-level VM
I suppose that you ignore low-level stuff unless you’re keenly interested in hardware-specific details. These details are gory and complex.
Your options:
- LLVM: allows for efficient machine code generation, usually for x86 and ARM.
- CLR: targets .NET, multiplatform; has a good JIT.
- JVM: targets Java world, quite multiplatform, has a good JIT.
Ignore optimization
Optimization is hard. Almost always optimization is premature.
Generate inefficient but correct code. Implement the whole language before you try to optimize the resulting code.
Of course, trivial optimizations are OK to introduce. But avoid any cunning, hairy stuff before your compiler is stable.
So what?
If all this stuff is not too intimidating for you, please proceed! For a simple language, each of the steps may be simpler than you might think.
Seeing a ‘Hello world’ from a program that your compiler created might be worth the effort.
Методики создания компилятора
Написание компилятора может потребоваться в самых разнообразных условиях — для различных языков, целевых платформ, с различными требованиями к работе компилятора и т.д. Например, одна из типичных проблем написания компилятора связана с тем, что на целевой платформе могут отсутствовать подходящие средства для разработки. Именно так обычно обстоят дела при создании новой компьютерной архитектуры: на начальном этапе жизни компьютера системные программисты не имеют никаких средств разработки, кроме системы команд самого компьютера (на этом этапе даже ассемблер может отсутствовать). Бывают и такие случаи, когда компилятор создается для еще не существующей целевой платформы.
Таким образом, цели и условия написания компиляторов могут очень сильно варьироваться от одного проекта к другому. Поэтому существует целый ряд методик разработки компиляторов; мы остановимся на наиболее распространенных из них:
- прямой, в котором целевым языком и языком реализации является язык ассемблера
- метод раскрутки
- использование кросс-трансляторов
- использование виртуальных машин
- компиляция «на лету»
Метод раскрутки

Компилятор — это весьма большая и сложная программа; на написание и отладку компилятора на языке ассемблера можно истратить слишком много времени. Для того, чтобы как-то справиться с этой проблемой, был придуман метод раскрутки, суть которого заключается в следующем.
Пусть есть компилятор 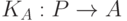 , где P — некоторый язык более высокого уровня, чем язык ассемблера. Тогда напишем
, где P — некоторый язык более высокого уровня, чем язык ассемблера. Тогда напишем 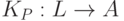 , а затем применим компилятор
, а затем применим компилятор 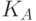 к компилятору
к компилятору 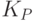 , т.е. получим
, т.е. получим 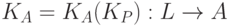 . Такая схема проиллюстрирована с помощью Т-диаграмм на слайде и называется раскруткой ( bootstrapping2Название метода раскрутки произошло от фразы «to pull oneself up by one’s bootstrap«, т.е. «вытянуть себя за шнурки», аналогично легендарному методу барона Мюнхгаузена ); компилятор как бы «раскручивается» с помощью компилятора .
. Такая схема проиллюстрирована с помощью Т-диаграмм на слайде и называется раскруткой ( bootstrapping2Название метода раскрутки произошло от фразы «to pull oneself up by one’s bootstrap«, т.е. «вытянуть себя за шнурки», аналогично легендарному методу барона Мюнхгаузена ); компилятор как бы «раскручивается» с помощью компилятора .
Описанная схема может быть использована при написании компилятора некоторого языка на нем самом. Пусть у нас есть компилятор некоторого подмножества S языка L в язык A, написанный на языке A, 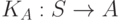 . Тогда мы можем написать
. Тогда мы можем написать 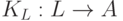 и получим новый компилятор
и получим новый компилятор  . Мы используем это подмножество S для того, чтобы написать компилятор языка L в язык A,
. Мы используем это подмножество S для того, чтобы написать компилятор языка L в язык A, 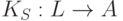 . Если теперь мы применим компилятор к программе
. Если теперь мы применим компилятор к программе 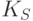 , то получим
, то получим 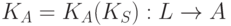
Впервые такая схема была применена в 1960 году при реализации языка Neliac. В 1971 году Вирт написал с использованием раскрутки транслятор языка Pascal, причем самый первый компилятор был оттранслирован вручную. Количество шагов раскрутки было больше 1, т.е. была построена последовательность языков 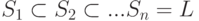 и построена последовательность компиляторов:
и построена последовательность компиляторов: 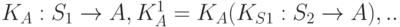 .
.
Раскрутку можно использовать и в следующей ситуации. Пусть у нас есть недостаточно эффективный компилятор 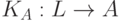 . Можно написать более эффективный компилятор , а затем применить раскрутку.
. Можно написать более эффективный компилятор , а затем применить раскрутку.
Кросс-транслятор
Пусть у нас есть два компьютера: компьютер M с языком ассемблера A и компьютер 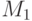 с языком ассемблера
с языком ассемблера 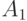 . Кроме того, предположим, что имеется компилятор
. Кроме того, предположим, что имеется компилятор 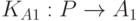 , а сам компьютер M по каким-то причинам не доступен либо пока еще не существует компилятор . Нас интересует компилятор . В такой ситуации мы можем использовать в качестве инструментальной машины и написать компилятор
, а сам компьютер M по каким-то причинам не доступен либо пока еще не существует компилятор . Нас интересует компилятор . В такой ситуации мы можем использовать в качестве инструментальной машины и написать компилятор  , который принято называть кросс-транслятором (cross-compiler) . Как только машина M станет доступной, мы сможем перенести на M и «раскрутить» его с помощью . Понятно, что это решение достаточно трудоемко, поскольку могут возникнуть проблемы при переносе, например, из-за различий операционных систем.
, который принято называть кросс-транслятором (cross-compiler) . Как только машина M станет доступной, мы сможем перенести на M и «раскрутить» его с помощью . Понятно, что это решение достаточно трудоемко, поскольку могут возникнуть проблемы при переносе, например, из-за различий операционных систем.
Под переносимой (portable) программой понимается программа, которая может без перетрансляции выполняться на нескольких (по меньшей мере, на двух) платформах. В связи с этим возникает вопрос о переносимости объектных программ, создаваемых компилятором. Компиляторы, созданные по методикам, рассмотренным выше, порождают непереносимые (non-portable) объектные программы. Поскольку компилятор, в конечном итоге, является программой, то мы можем говорить и о переносимых компиляторах. Одним из способов получения переносимых объектных программ является генерация объектной программы на языке более высокого уровня, чем язык ассемблера. Такие компиляторы иногда называют конвертерами (converter) .