На кого рассчитана данная статья
Данная статья рассчитана на всех интересующихся, т.к. по большей части материал будет повествоваться в упрощенном абстрактном виде (схемы, картинки) в угоду легкому пониманию, без кучи кода. Будет обсуждаться проблема, какие были способы её решить и какой выбрали мы. Любая конструктивная критика касательно принятых нами решений и предложения по улучшению материала приветствуется в комментариях.
В чём собственно сложность
Не секрет, что разработка своей игры – желание многих разработчиков, именно с этого у некоторых появилось увлечение IT. А вот разработка онлайн игры – это уже посложнее сценарий и не до конца очевидный для всех, однако играть в игру, особенно в которой предусмотрен кооператив, всегда интересней, чем проходить её в соло. Даже самый скучный проект может засиять и подарить кучу положительных эмоций проходя это все с кем-то. Являясь любителем таких кооперативных PvE игр как Deep Rock Galactic, Remnant: From the Ashes, Helldivers и т.д., мне, как разработчику, всегда было интересно, как устроена их архитектура: как сервера организуют сессии, как справляются с обеспечением тысячи игроков ресурсами, как синхронизируют игроков друг с другом и тому подобное. Это и стало целью моего исследования.
В чем ценность данного материала
Потратив почти полтора года на разработку нашей кооперативной real-time игры мы (программист, графический дизайнер и саунд дизайнер) наконец-то довели её до preproduction состояния. Проект начинался исключительно на энтузиазме, как способ доказать нам самим, что мы можем создать свою собственную онлайн кооперативную игру с нуля (в моем случае — не используя готовых решений для организации игры по сети). Сам проект не будет упоминаться в материале ввиду того, что в публичный доступ он ещё не вышел (в случае, если эта статья вызовет интерес у читателей, в будущем возможно будет отдельный материал уже про другие аспекты разработки проекта, такие как графика, музыка, работа в команде и сравнение платформ Itch.io и Game Jolt).
Так как в ходе разработки проекта, а именно его бекенд части (создание архитектуры сервера, его оптимизация, развертывание в облаке с отказоустойчивостью) приходилось опираться на различные статьи, форумы и комментарии со всех уголков интернета, это подтолкнуло меня на написание данной статьи, в которой в структурированном виде будет рассказано обо всем опыте решения проблем при написании своего сервера, это может послужить полезным сборником опыта для начинающих интересоваться данной темой.
Немного теории: кто сервер, кто хост, а кто клиент

Начнём с самых основ, допустим у нас есть некая игра на одного игрока, мы управляем черным человечком, игра нам генерирует противников и обеспечивает физику объектов:
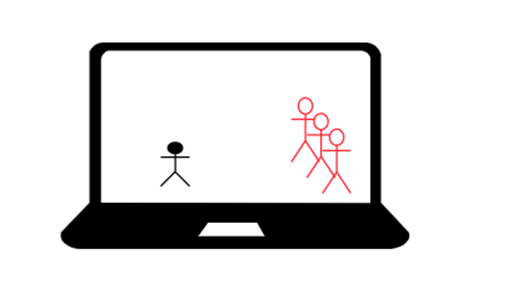
Мы хотим добавить в эту игру мультиплеер на два игрока, вдвоём играть всегда веселее, чем одному, но как нам это сделать? Имея исходный код проекта, немного изменим его: дублируем игру на второй компьютер, создаём второго человечка для второго игрока и программируем компы обмениваться координатами этих человечков:
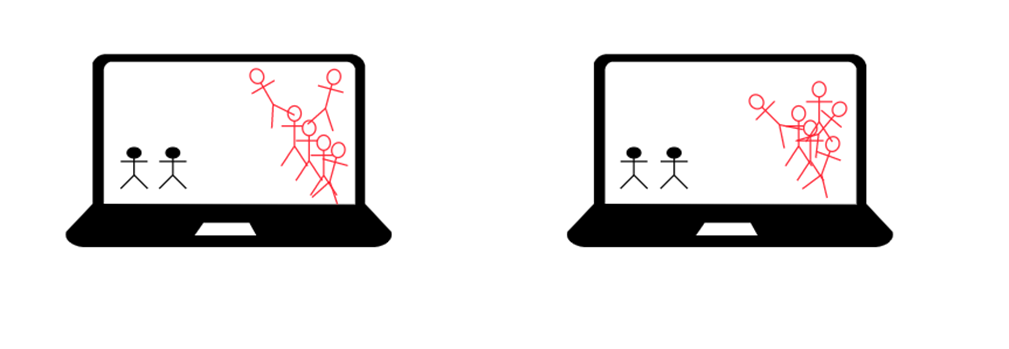
Упс, что-то пошло не так. Дело в том, что первый компьютер, как и второй – оба генерируют противников, вместо 3-ех противников, у нас их теперь 6 в одном и том же месте и из-за этого они разлетаются по сторонам согласно физике, которую каждый компьютер, опять же, вычисляет отдельно.
Тут у нас возникает конфликт между двумя компьютерными «мозгами», каждый генерирует свой мир и вычисляет свою физику, из-за чего каждый игрок видит разную картину.
Как это решить? Нам нужен один источник правды, только один компьютер будет вычислять физику и генерировать противников, тратить на это свои вычислительные ресурсы, а второй компьютер будет просто повторять за первым, ему будут интересны лишь координаты всех объектов, чтобы их отрисовать:

Таким образом, 1-ый компьютер у нас становиться сервером (serve – обслуживать), он обслуживает остальных игроков (их компьютеры) своими ресурсами и отправляет им данные всех объектов, чтобы они за ним повторяли, а в ответ компьютеры игроков (клиенты) присылают данные движения своих персонажей (например, клавиши нажатия: влево, вправо, вниз, пробел и т.д.).
В итоге получаем, что игра, которая раньше была одной и целой делится на две отдельные программы – серверная часть и клиентская часть. Компьютер, который тратит свои вычислительные мощности на серверную часть проекта именуется как хост.
По такой клиент-серверной архитектуре и работают наши любимые онлайн игры, как PvP, так и кооперативные.
То есть хост и сервер – это одно и тоже?
Не совсем, сервер – это доминирующая часть приложения, которой подчиняются клиенты, а хост – машина, на которой работает сервер, а вот кто будет этим самым хостом — это вопрос, в зависимости от ответа на который, мы получим две принципиально разные архитектуры со своими преимуществами и недостатками:
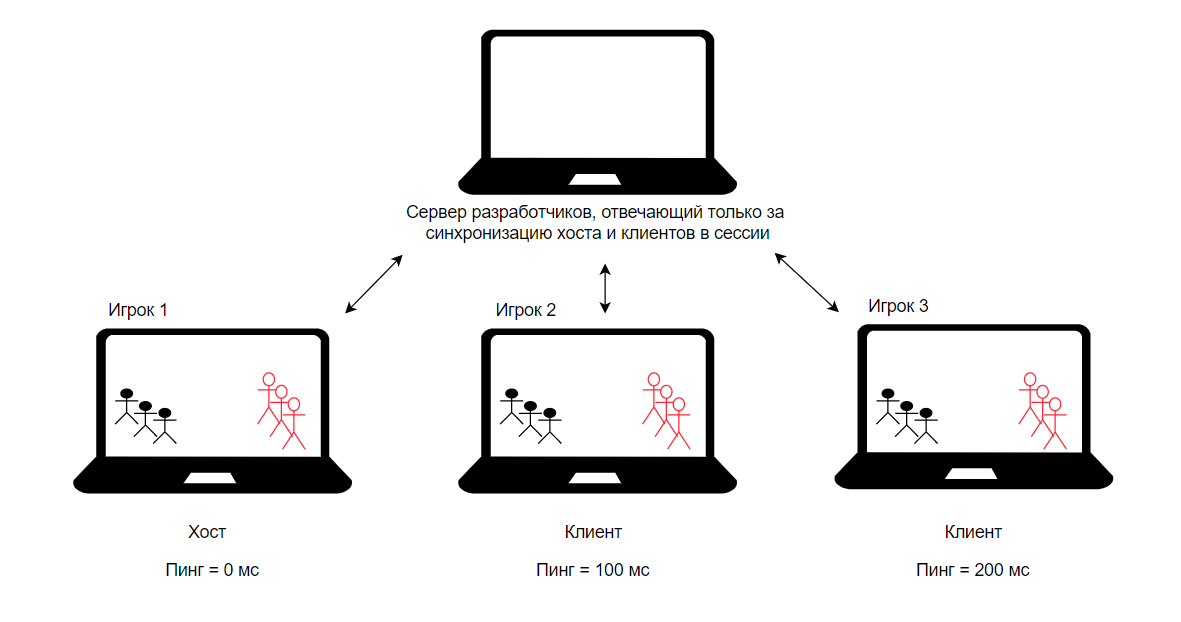
1) Хост – компьютер одного из игроков в сессии
В данном случае у игрока данного компьютера будет настоящий экземпляр игры, т.к. это его компьютер будет отвечать за генерацию и физику (как в нашем примере выше).
Преимущества данного подхода:
-
Разработчику онлайн игры не нужно тратить деньги на мощные сервера для игроков, ведь все вычисления будут на одном из игроков в сессии (машины разработчиков, как правило, будут просто заниматься синхронизацией хоста с клиентами и сбором данных, на это много мощностей не нужно)
Недостатки данного подхода:
-
Игрок, являющийся хостом, будет иметь преимущество над остальными игроками, так как для него ping (задержка) будет 0 мс, поэтому данный подход не очень честен для PvP сессий, а скорее подходит для кооперативных игр
-
Так как серверная часть игры находится под контролем одного из игроков, резко возрастает возможность для читерства со стороны данного игрока
-
Если во время игровой сессии, хост перестанет справляться с нагрузкой (что довольно типично для игроков со слабым железом), или у хоста будут проблемы с сетью, то это скажется на всех остальных игроках вплоть до прекращения сессии
Как можно заметить, данный способ является довольно экономным для разработчика, однако несёт в себе несколько рисков в виду того, что серверную часть контролирует игрок-хост.
2) Хост – компьютер, принадлежащий разработчикам игры (авторитарный сервер)
В данной архитектуре подразумевается, что разработчики онлайн игры будут сами обслуживать игровые сессии для игроков. Делать они это могут несколькими способами, либо арендовать/покупать машины в дата центре, которые будут обслуживать игровые сессии, либо арендовать виртуальные машины у поставщиков облачных ресурсов по типу AWS, Google Cloud, Azure и т.д.

Преимущества данного подхода:
-
Код серверной части не будет доступен игрокам, соответственно резко уменьшается пространство для читерства и поиска уязвимостей
-
Разработчики, как правило, арендуют стабильные машины для запуска своих серверов, с достаточным железом и стабильной сетью, что гарантирует всем игрокам беспрерывную игровую сессию
-
Ни у кого из игроков нет преимуществ над остальными, все в равных условиях и подчиняются одному, как его называют, авторитарному серверу, а поэтому данная архитектура хорошо подходит для PvP сессий
Недостатки данного подхода:
-
Если игра подразумевает сложную генерацию мира, объектов, а также вычисление физики, то на обработку каждой сессии нужно немалое кол-во ресурсов (оперативной памяти, процессорного времени), поэтому покупка, как и аренда машин для таких игровых сессий могут сильно ударить по карману разработчика
Реализация архитектуры авторитарного сервера
Почему выбор пал на авторитарный сервер?
Несколько причин:
-
В игре хоть и присутствуют генерация мира и вычисление физики объектов, но это не сильно бьет по процессорному времени, так как игра 2D и действия проходят на одной не самой большой карте
-
Хоть читерство и непрерывность игровой сессии более критичны в PvP игре, нежели чем в кооперативной PvE, так или иначе, иметь эти преимущества тоже приятно, когда ты полностью контролируешь сервер
-
Сервер написан на Python, а с Python, к сожалению, очень сложно спрятать исходный код от игроков. Python — язык интерпретируемый, что означает, что ваша программа не компилируется в машинный код (.exe файлы в случае Windows), а просто представляет из себя текстовые файлы, которые все могут прочитать и которые запускает сам Python. Да, соглашусь, что этот момент немного спорный, так как все таки есть разные ухищрения, который затрудняют reverse engineering Python приложений, да и в-принципе от reverse engineering’a не защищен даже машинный код, но этот момент также сделал выбор авторитарного сервера более привлекательным
Как в-принципе сочетаются Python и real-time игра с физикой
Понимаю, выбор языка может показаться странным, многие наслышаны о медленной производительности Python, однако трюк тут состоит в том, что зачастую Python не сам вычисляет сложные формулы и физику, а делегирует это Си-библиотекам, которые и работают под его капотом.
Например для физики мы используем библиотеку pymunk, которая просто является питоновской надстройкой над библиотекой chipmunk, которая уже, в свою очередь, написана на C, а отсюда и быстродействие её работы.
Чем же реально Python занимается на сервере, так это бесконечным циклом (`while True:`, типичный код для любой игры, чтобы игра бесконечно обновлялась и не останавливалась, тут важно, чтобы игра обновлялась хотя бы 60 раз в секунду, что равно 60 FPS), созданием игровых объектов, событий и обработкой подключенных игроков. С этими задачами Python справляется на достаточном уровне.
Архитектура игровой сессии на сервере
Каждая сессия может содержать в себе до 3-ёх игроков в нашем проекте. А что такое игрок в нашем серверном понимании? Это подключение к нашему серверу, игрок нам шлёт нажатые клавиши (влево, вправо, вниз, пробел и т.д.), а мы ему в ответ состояние текущей игры. И подобное действие нам необходимо делать параллельно ещё с двумя другими подключенными игроками. Но и это ещё не всё, также параллельно со всем этим должна работать и сама игра данной игровой сессии, в которую игроки собственно и играют. Итого мы получаем 4 потока в игровой сессии (подключение 1-го игрока, 2-го, 3-го и сама игра), которые должны работать параллельно. Как такого достичь?

Пара слов о параллельном программировании: процессы и потоки
Когда вы запускаете приложение (будь-то игра, сервер, бразуер), для неё создается процесс в системе, вы их можете увидеть в диспетчере задач, сам процесс содержит внутри себя хотя бы 1 поток. Поток — это и есть способ выполнения процесса и выполняется он на одном ядре процессора. То есть, если у вашего процессора 8 ядер, то процесс с одним потоком сможет занять только 1 ядро вашего процессора (12,5%). Соответственно, если вы желаете отдать вашей программе всю мощность вашего процессора, вам необходимо создать 8 потоков внутри процесса вашей программы и тогда оно захватит все доступные ядра и забьёт процессор на 100%. То есть увеличение потоков — это способ распараллелить процесс программы, заставить ее делать несколько действий одновременно (многозадачность), или же просто увеличить производительность программы.
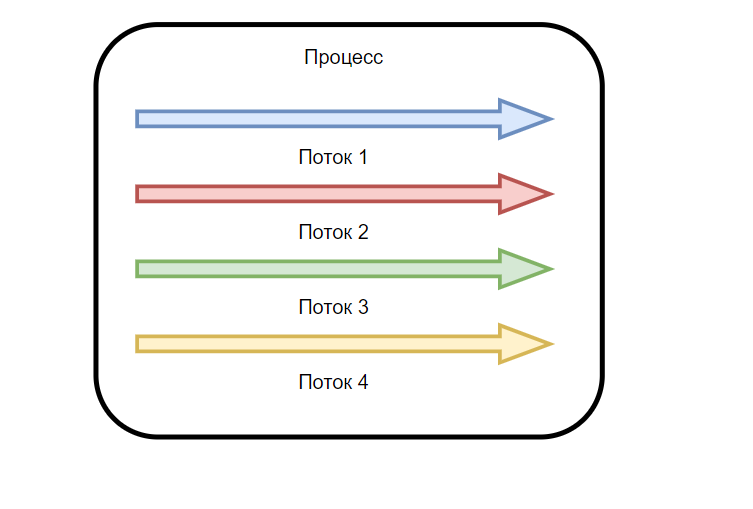
В нашем случае, нас интересует многозадачность, нам нужно параллельно обрабатывать подключение 1-го игрока, 2-го, 3-го и саму игру внутри одной игровой сессии, то есть для одного процесса с игровой сессией нам нужно 4 потока. Но, просто создать 4 потока недостаточно, нужно же сделать так, чтобы они общались между собой, как это устроить? Ответ — очереди.
Снова немного теории. Очередь — это некий контейнер, который позволяет нам наладить общение между потоками, пока одни потоки туда складывают информацию, другие оттуда её читают. Согласитесь, удобно, поток с 1-ым игроком кладет в очередь нажатые клавиши этого первого игрока, а поток с игрой эту очередь читает в порядке “что первым пришло, то первым и получил” (FIFO) и затем применяет входные данные (нажатые клавиши игрока) в действие, из-за чего персонаж, которым управляет 1-ый игрок действительно движется туда, куда приказал игрок.
Архитектура игровой сессии: общая картина

Есть поток с игрой (Game, самый верхний), мы видим что он читает (get — получить) три очереди user movements из трёх других потоков (1-го, 2-го и 3-го игрока), таким образом, игра (поток с игрой) успешно ловит нажатые клавиши всех 3-ёх игроков. Игра эти нажатые клавиши обрабатывает, двигает персонажей игроков и взамен отсылает (put — класть) состояние всей игры (координаты всех объектов) в очереди Objects для каждого потока игроков (1-ый, 2-ой и 3-ий).
Таким образом у нас получается простая, но рабочая система. Игроки присылают нажатые клавиши, игра это обрабатывает, учитывает и в ответ отсылает координаты всех объектов (состояние игры), всё это происходит каждый кадр игры, из-за чего игроки даже не подозревают обо всех этих процессах происходящих под капотом. Кажется, что игрок нажал влево и персонаж пошел влево, просто потому что его компьютер сказал ему пойти влево, но в реальности компьютер лишь передал нажатую клавишу игрока на удаленный сервер в поток с подключением данного игрока, тот его положил в очередь для нажатий данного игрока, игра с этой очереди прочитала нажатую клавишу, подвинула персонажа, отправила координаты (состояние игры) в поток с подключением этого игрока, тот поток уже отправил координаты компьютеру игрока и уже тот поправил картину по новым координатам. Вот такая магия.
Про Python и его проблему с потоками
Не секрет, что Python, к сожалению, не позволяет всем 4-ым потокам быть активными в один момент времени, только один поток в один момент времени может быть активным из-за известного всем Python разработчикам GIL. Из-за чего о росте производительности тут речи не идёт, однако мы добиваемся многозадачности, а производительности одного ядра (так как у нас только один поток работает в момент времени из-за Python) хватает на 3 подключения и саму игру.
Как происходит создание и удаление игровых сессий
Архитектура, изложенная сверху, покрывает лишь саму игровую сессию, однако нужен ещё один процесс, который уже будет управлять созданием, отслеживанием и удалением этих самых игровых сессий (а вернее, их процессов), то есть это некий процесс, занимающийся оркестрацией других процессов. Это процесс, с которым игроки будут взаимодействовать до того, как они попадут в саму игровую сессию. Назовём этот процесс — main server, главный сервер. Игроки будут просить главный сервер дать список текущий сессий (чтобы подключиться к ним) или же создать новую сессию. Покажем как это выглядит на следующей схеме:

Оптимизация сервера (и немного клиента)
В связи с тем, что проект, в первую очередь, real-time (то есть необходимо как можно сильнее сократить время от того, как клиент получит нажатия игрока, до того, как клиент отобразит результат этих самых действий игрока) пришлось выполнить ряд оптимизаций, как на сервере, так и на клиенте, чтобы добится оптимальной производительности и стабильности.
Оптимизации на сервере
1. Способ передачи данных
Изначально оба сервер и клиент были написаны на Python, а значит была возможность воспользоваться питоновским способом отправки объектов, а именно — pickle. Пример такого потока данных:
[<network_classes.border.NetworkBorder object at 0x000001A44EF51070>,
<network_classes.border.NetworkBorder object at 0x000001A44EF51280>,
<network_classes.border.NetworkBorder object at 0x000001A44EF51040>,
<network_classes.border.NetworkBorder object at 0x000001A44EF83550>,
<network_classes.border.NetworkBorder object at 0x000001A44EF83520>,
<network_classes.border.NetworkBorder object at 0x000001A44EF834F0>,
<network_classes.border.NetworkBorder object at 0x000001A44EEAF790>,
<network_classes.player_ball.PlayerNetworkBall object at 0x000001A44EEAF6D0> ……..]Преимущества такого подхода:
-
Легко реализовать на Python
Недостатки такого подхода:
-
Тяжелые объекты для real-time продукта
-
Не кросс-платформенно (настроить общение таким способом можно только между Python процессами)
-
Проблемы с безопасностью (в pickle довольно легко подсунуть вредоносный Python код для его выполнения получателем, поэтому pickle лучше использовать в частных приватных сетях, где вы точно можете доверять отправителю)
После осознания проблем с pickle, было принято решение перейти на более универсальный формат отправки данных — json. Пример такого потока данных:
[
{x: 12, y: 10, id: 30, radius: 80, color: “red”, cls: “ball”},
{a_x: 22, a_y: 45, b_x: 122, b_y: 145, id: 45, color: “blue”, cls: “border”},
...
]Преимущества такого подхода:
-
Легко реализовать
-
Кросс-платформенно
-
Нет фундаментальных проблем с безопасностью, как в случае с pickle
Недостатки такого подхода:
-
Все еще тяжелые объекты для real-time продукта (сервер будет отправлять состояние игры игрокам каждый проход цикла и каждый раз, вместе со значениями будут отправляться одни и те же ключи значений, что просто излишнее кол-во байт, также json нужно сериализовать перед отправкой и десериализовать при получении, что тратит процессорное время)
В попытках добиться наилучшей оптимизации было принято решение перейти на обычные строки, а вместо ключей — полагаться на порядок значений. Пример такого потока данных:
1.2.0.0.800.0.10.20.0.5;1.3.1200.0.2000.0.10.20.0.5;1.4.0.1200.2000.1200.10.20.0.5;1.5.0.0.0.640.10.20.0.5;1.6.0.960.0.1200.10.20.0.5;1.7.2000.0.2000.640.10.40.0.5;1.8.2000.960.2000.1200.10.40.0.5;3.11.400.100.90;3.12.1500.1100.90;3.13.1900.1000.120;3.14.300.1100.160;3.15.1200.600.50;3.16.700.1000.80;3.17.1600.700.170;3.18.800.900.170;2.1.832.1130.60.0.5.1.0.0;4.22.1832.1495.140;4.23.288.948.150;5.25.1855.531.60.7;5.26.1290.1130.60.7….Теперь у нас нет никакой лишней информации, у нас только голые значения и разделители.
Аналогично и с клиентом, если раньше он отсылал данные о нажатых клавишах в виде такого вот json:
{“up”: true, “right”: true, “left”: false, “down”: false, “attack”: true, “accelerate”: true} То теперь просто передает строку, содержащую ту же самую информацию, но будучи короче в ~10 раз:
110000Преимущества такого подхода:
-
Нет проблем с безопасностью
-
Легковесный объект
-
Кросс-плафтормено (нужно лишь реализовать логику по распаковке данной строки, что по-факту представляет из себя парочку `split`ов)
Недостатки такого подхода:
-
Трудно реализовать и поддерживать
Однако преимущества для меня перевесили недостатки и я решил остаться с этим вариантом.
2. Следите за блокирующими операциями
В программе, в которой у вас несколько потоков и подключений, важно следить, чтобы не было такого, что один поток встал и из-за него встали все остальные.
Как один из примеров, вот у нас в процессе с игровой сессией есть поток 1-го игрока, который кладет нажатые клавиши данного игрока в очередь, чтобы оттуда их прочитал поток с игрой, и тут важно сделать так, что если очередь пустая (допустим у игрока с сетью проблемы), то и ладно, нужно дальше продолжать работу. В том же Python это нужно явно указать, так как операция по получению чего-то (`.get()`) из очереди является блокирующей по-умолчанию.
То есть вот такой код:
player_move = player.move_queue.get()
player.move(player_move)Следует заменить вот таким:
try:
player_move = player.move_queue.get(block=False)
except Empty:
player_move = previous_player_move
player.move(player_move)Если нам ничего не пришло, то просто используем предыдущее данные, пакеты теряются часто и скорее всего игрок все еще нажимал предыдущие кнопки.
3. Уберите буфер в ваших сокетах (подключениях)
Дело в том, что по умолчанию сокеты отправляют данные (от клиента к серверу, или от сервера к клиенту), когда они достигают какого-то значения буфера. Для того, чтобы незамедлительно отсылать данные получателю, необходимо отключить алгоритм Nagle на сервере и клиенте:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)4. Используйте протокол TCP, а не UDP
Как известно, когда речь идет о стриминге данных, тут, как правило, на сцену выходит UDP, посколько он просто отправил данные и забыл, может дублировать какие-то пакеты, может и вовсе их не отправить, это делает его очень скоростным относительно TCP, который в свою очередь гарантирует, что все данные придут в целостности и по порядку. И TCP мог бы действительно внести много задержек при стриминге, если бы у нас была плохая сеть, но в сегодняшних реалиях почти все обеспечены более менее хорошим интернетом и TCP не приходится по несколько раз бегать с одним и тем же пакетом, зато он нам гарантирует целостность и порядок данных. Если же мы будет использовать UDP, то перед процессингом полученных данных нам придется несколько раз их провалидировать, чтобы убедиться, что мы получили то, что хотели, по итогу получаем некую надстройку над UDP, хотя всё это уже есть в TCP.
5. Добавляйте маркер начала и конца каждого сообщения
С TCP всё же есть небольшая проблема, хоть данный протокол и гарантирует порядок данных, он не гарантирует, что данные придут именно одним пакетом.
То есть хотим мы отправить “Hello world” и “Hi all”, прийти они могут следующим образом: “Hell”, “o wor”, “ldHi all”. Поэтому важно добавить разделители между сообщениями, пусть ‘?’ — начало сообщения, а ‘!’ — конец сообщения, тогда отправив “?Hello world!” и “?Hi all!”, мы получим “?Hell”, “o wor”, “ld!?Hi all!”, можем спокойно соединить эти пакеты и по разделителям увидеть наши сообщения — “Hello world” и “Hi all”.
Отпимизации на клиенте
Алгоритм предсказания
Порой бывают моменты, когда сеть всё-таки становится нестабильной, порой на полсекунды, а иногда на 1-2. В этот момент клиент не получает никаких данных от сервера, соответственно для него игра остановилась, а если такие сбои происходят довольно часто, то игрок видит дергающуюся картину. Как исправить такой момент? Как правило, в течении 0.5-2 секунд ничего особенного не происходит, объекты, которые двигались в каком-то направлении, так в нём и движутся, поэтому при отсутствии данных сервера можно просто продолжать движение всех игроков в зависимости от их последней скорости с сервера. Например для какого-то объекта:
Взять предыдущие координаты: (500, -403)
Взять текущие координаты: (503, -410)
Подсчитать теоретическую скорость:
speed_x = 503 – 500 = 3 pixels
speed_y = -410 + 403 = -7 pixels
Хочу обратить внимание, что данная скорость должна подсчитываться сервером, а не клиентом, так как клиент, в виду потерянных пакетов, может посчитать неверную скорость объекта.
Соответственно, пока сети нет, следующими теоретическими координатами будут: (506, -417), потом (509, -424), и т.д.
Динамическое автомасштабирование в AWS
Теперь, когда у нас есть работающая архитектура проекта с необходимой оптимизацией, можно поговорить о том, как мы будем это разворачивать.
Что такое динамическое автомасштабирование?
Динамическое автомасштабирование — это способ автоматически изменять количество ресурсов в зависимости от нагрузки на эти ресурсы.
В нашем случае это означает иметь столько виртуальных машин, сколько необходимо для обработки игровых сессий всех игроков и автоматически добавлять или удалять данные машины в зависимости от того, как изменяется спрос игроков.
Зачем маленькому инди-проекту инфраструктура с динамическим автомасштабированием?
Давайте посмотрим на простой способ развертывания нашего авторитарного сервера:
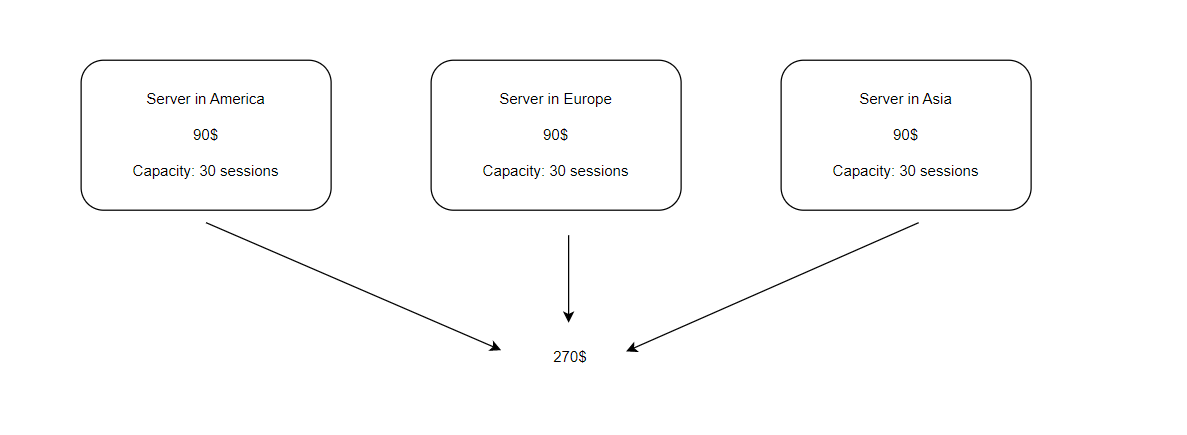
Чтобы покрыть большую часть планеты низким пингом, мы можем просто арендовать три более-менее мощные машины по одной в каждый регион, в моем случае сервер, оптимизированный на CPU, который может выдержать примерно 30 игровых сессий стоит 90 долларов в DigitalOcean.
Данный способ является очень простым, три машины, каждая в своем регионе, у каждой свои игровые сессии и за каждую ты платишь фиксированную сумму, как для инди-разработчика, это кажется вполне простым решением.
Однако данный способ всё-таки немного бьёт по карману, а игра никак не коммерческая. Соответственно было бы неплохо взять машины послабее, но тут сразу очень много “а что если?”: а что если игра выстрелит? А что если машина не выдержит и просто упадёт? А что если машины атакуют DDoS атакой? А что если и вправду все эти переживания зря, проект в-принципе будет никому не нужен и ресурсы машин за 300 долларов будут просто сгорать?
Вот бы был способ как-то динамически решить этот вопрос уже “в бою”, будут играть пару игроков, ну и будут машины крутиться за копейки, а придёт много — система сразу нарастит необходимые ресурсы и освободит их, когда они станут не нужны. С помощью крупных облачных поставщиков таких как AWS такие сценарии вполне можно реализовать:
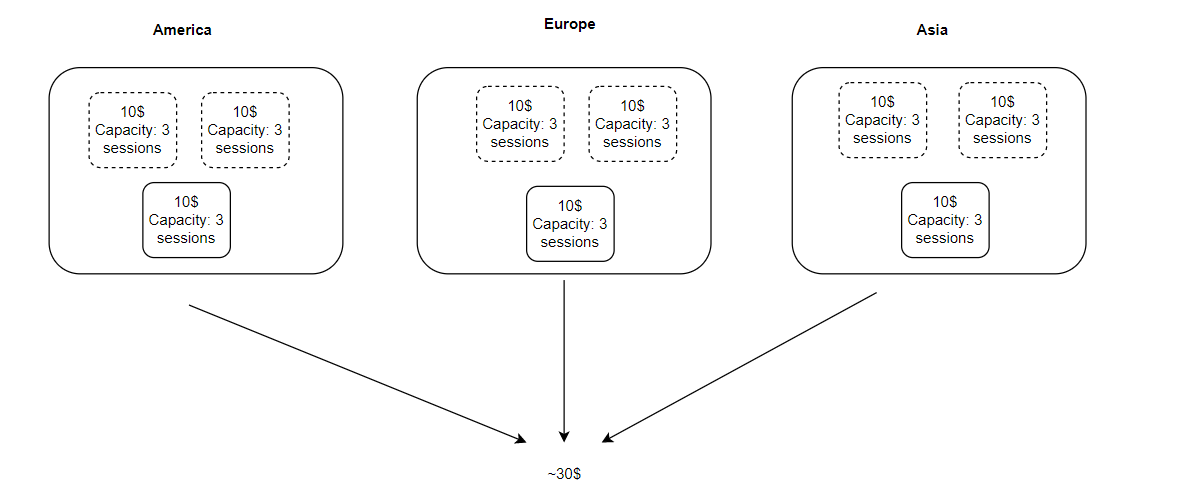
В данном случае у нас на каждый регион создается группа ресурсов, где всегда работает хотя бы одна виртуальная машина, в данном случае, это — машина, которая способна выдержать 3 игровые сессии и обходится она нам в 10 долларов в месяц каждая. Развернув такую группу в 3-х регионах мы получаем суммарно примерно 30 долларов в месяц, это при условии, что в игру почти никто не будет играть, что порой весьма реалистично для инди проектов, но в этом случае мы теряем всего 30 долларов, а не 300, как в случае описанном выше.
Почему AWS
У AWS есть всё необходимое для данной архитектуры, о чём будет написано ниже, само собой подобное можно сделать и в других крупных поставщиках, но у AWS огромное количество документации, коммьюнити, поэтому долго ломать голову над каждой мелочью не пришлось. Хотя если пренебречь данной динамической инфраструктурой и сделать всё по простому, то тут уже куда привлекательней смотрится DigitalOcean с его простой настройкой виртуальных машин и простой ценовой политикой.
Как это все выглядит в AWS
На каждый регион, в котором мы хотим развернуть нашу инфраструктуру, у нас получается следующая картина:

Что здесь для чего нужно и зачем:
Target group
Представляет из себя группу виртуальных машин, которые хостят игровой сервер, вот так это выглядит в AWS:
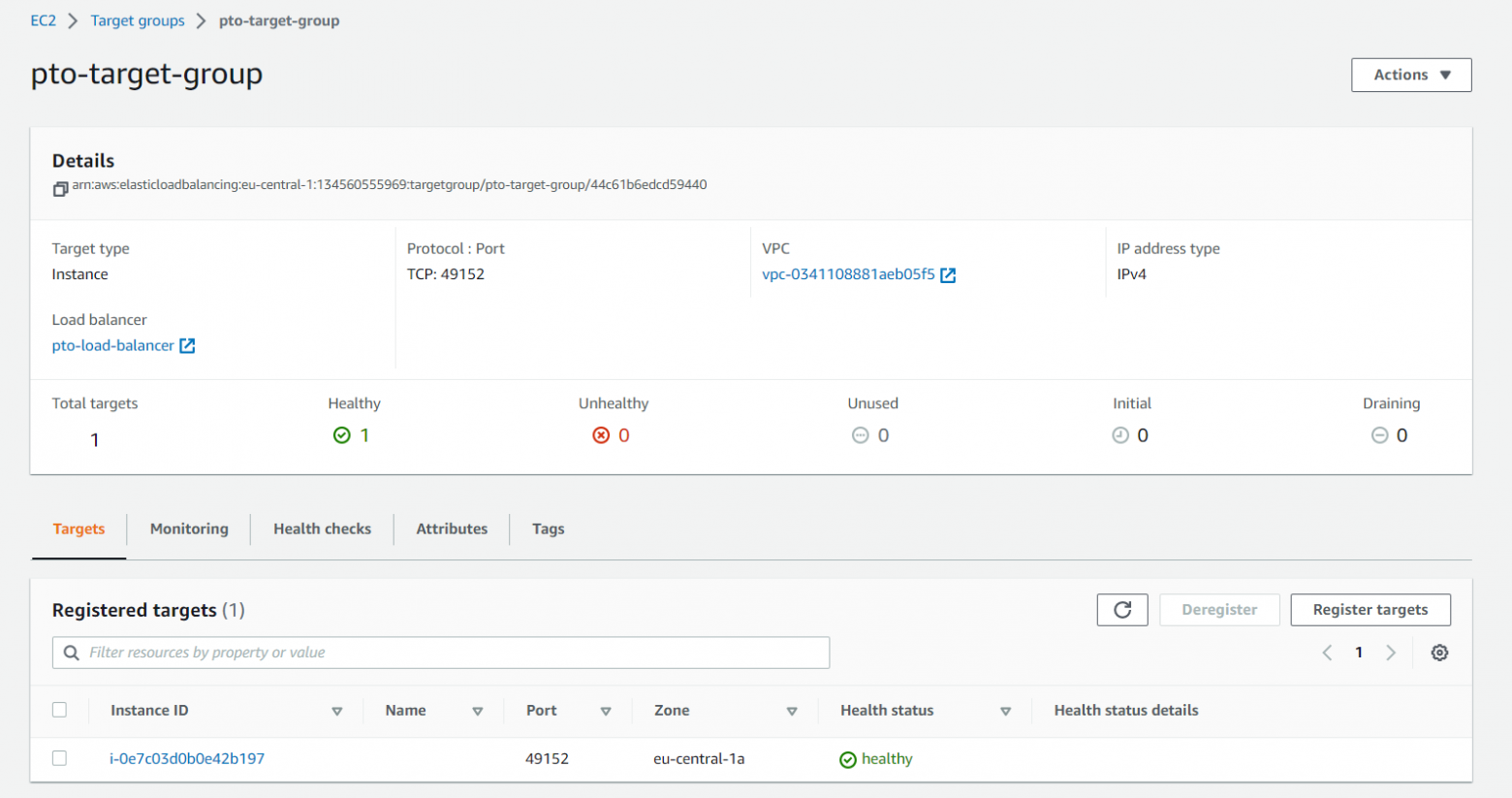
Видно, что в данной Target группе у нас только одна машина и она помечена как healthy. Как AWS это проверяет? Балансировщик нагрузки (о котором рассказано ниже) стучится на порт, на котором развернут сервер (раз в указанное количество секунд) и в случае хоть какого-то ответа помечает нашу машину живой и здоровой.
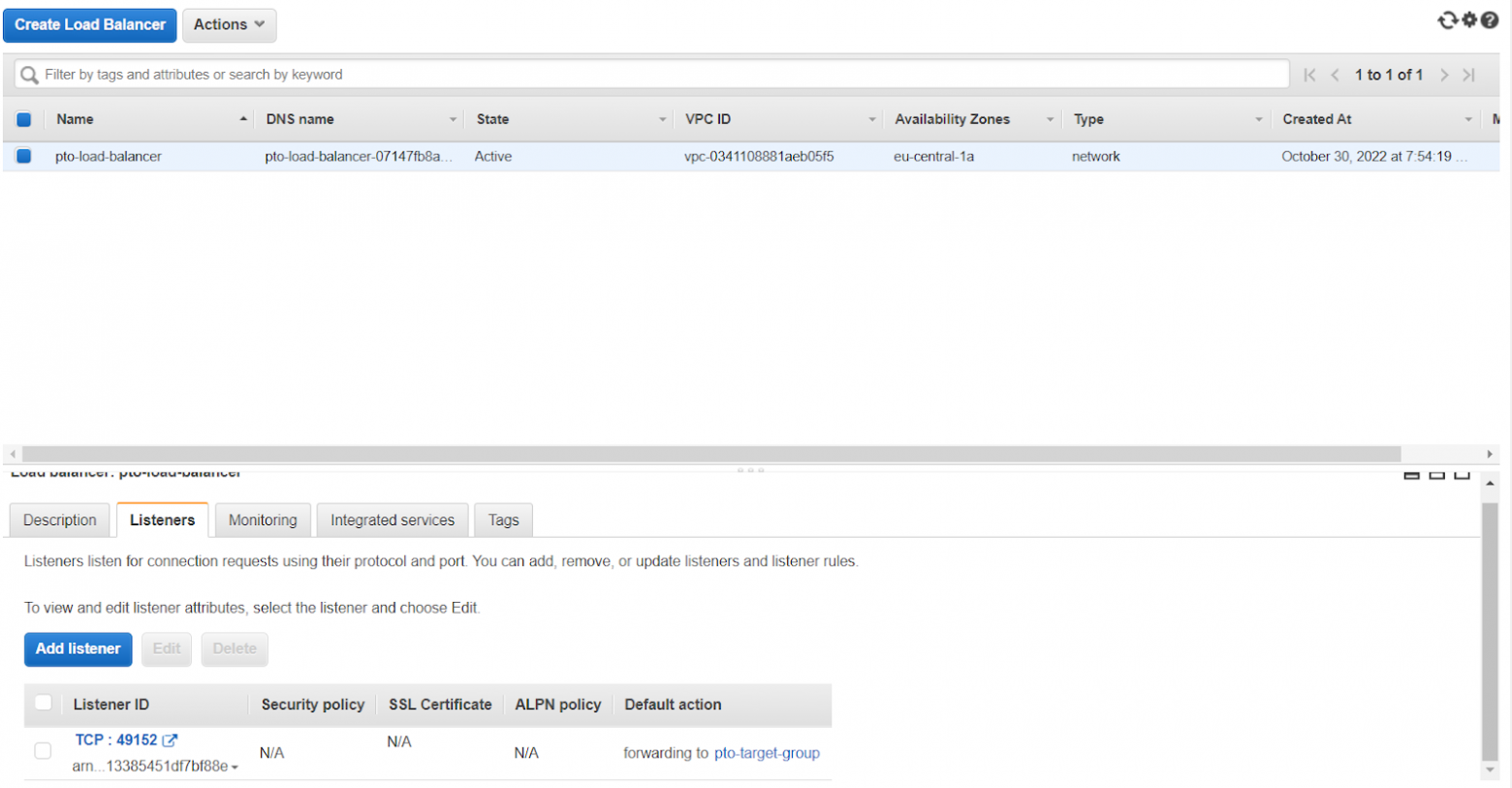
Elastic Load Balancer
Представляет из себя балансировщик нагрузки, который принимает подключение от игрока и перенаправляет его на одну из машин в Target группе по round robin схеме (круговому циклу), к сожалению, балансировщик в AWS не отслеживает такие характеристики как загруженность процессора, поэтому он не основывает свой выбор на том, какая машина загружена, а какая нет. На скриншоте вы можете видеть главный компонент балансировщика — Listener (на какому порту ждать запрос от игроков и в какую Target группу этот запрос потом перенаправить):
Auto Scaling
Занимается автомасштабированием. Следит за метриками машин в Target группе, а также устанавливает:
-
Минимальное кол-во машин в Target группе (Minimum capacity), это то кол-во машин, которое будет работать сразу со старта
-
Желаемое кол-во машин (Desired capacity), это кол-во будет изменяться в зависимости от нагрузки
-
Максимальное кол-во машин (Maximum capacity), это потолок, до которого мы разрешаем поднимать виртуальные машины (все-таки каждая машина стоит своих денег)

Также Auto Scaling содержит в себе Launch template, инструкция по тому, как поднимать машину, какое железо ей выбрать, какую ось ей поставить, что на ней запустить:
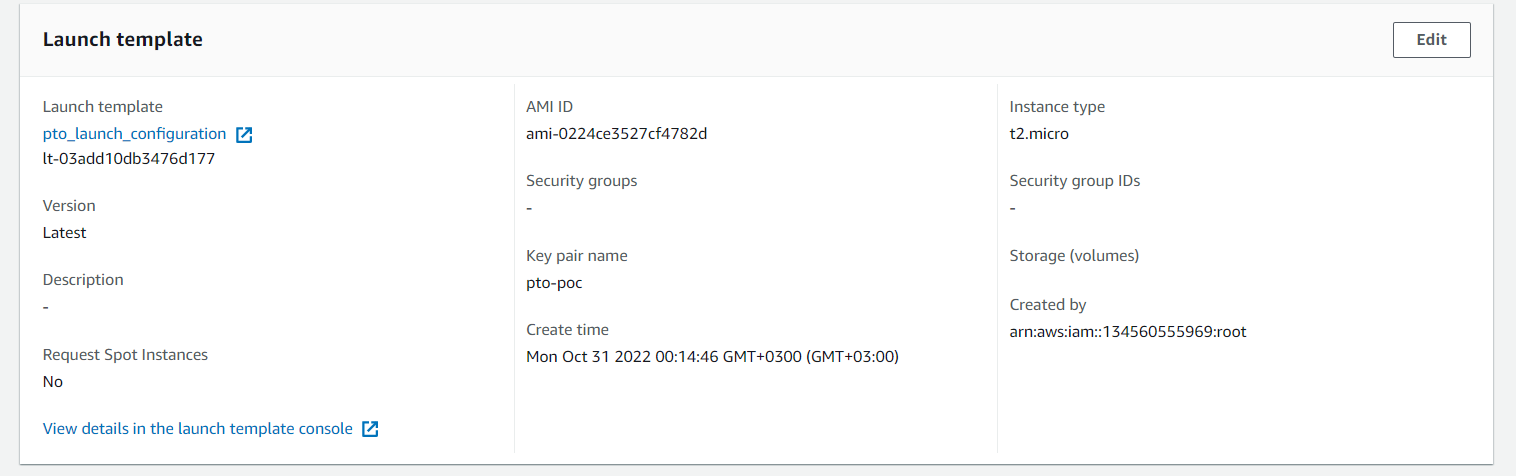
Также содержит в себе политику динамического масштабирования, в котором мы и говорим, когда нужно поднимать или удалять виртуальные машины:
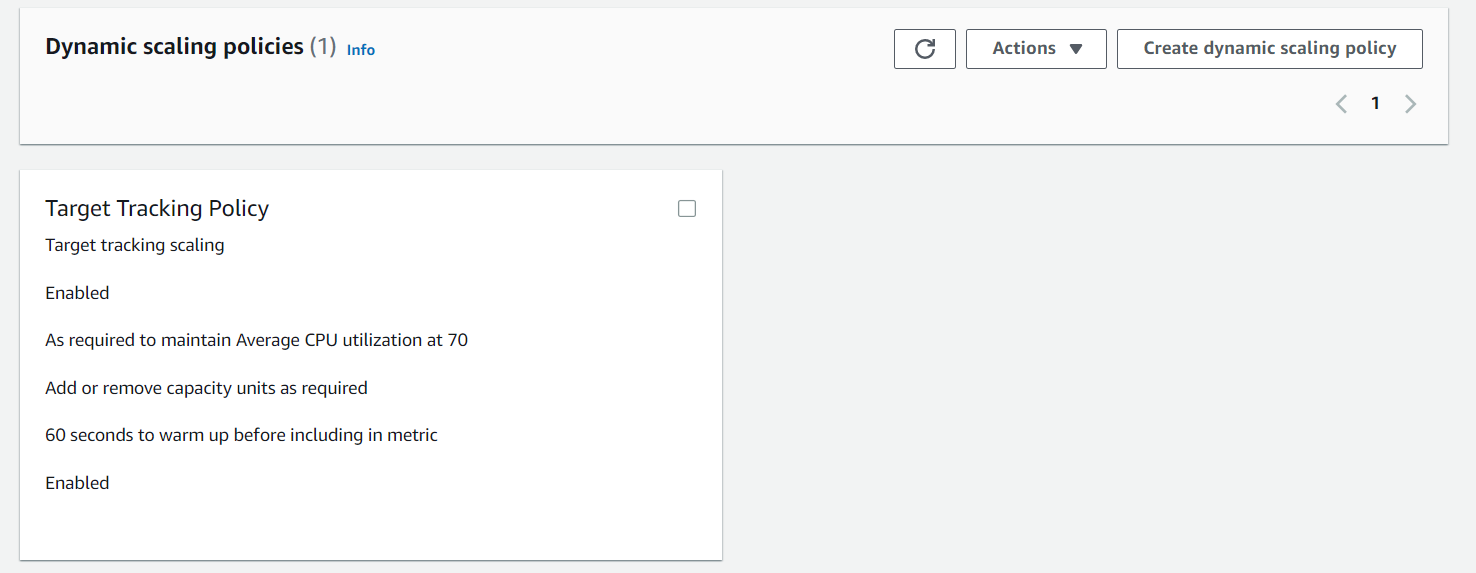
В данном случае на скриншоте сказано “Средний уровень загруженности процессора на каждой машине не должен превышать 70%, по необходимости добавлять/удалять машины, каждой машине дать 60 секунд на разогрев после старта прежде чем включать ее в подсчет метрик”.
DynamoDB
Данный сервис представляет из себя NoSQL базу данных и нужен только для одной цели — временное хранилище сессий. Для чего это нужно? Дело в том, что каждая виртуальная машина — это прежде всего отдельная машина и у каждой из них свой список игровых сессий. Допустим вы и ваш друг играете в одном регионе и вы хотите подключится к его сессии, но вот проблема, под капотом оказалось, что вы на самом деле сейчас на разных виртуальных машинах, соответственно, вам нужно как-то перепрыгнуть на его машину.
В этом нам и помогает данная БД, все сервера складывают туда информацию о своих сессиях (IP адрес + порт + другая полезная метаинформация) и любой сервер даст вам список всех сессий просто попросив их в данной БД. Соответственно клиент вашей игры получает информацию о сессии от любого сервера, видит, что она находится по другому адресу, на другом сервере и переподключается. Таким образом несколько машин могут работать как единый механизм.
Пример того, как выглядят сессии в данной БД:
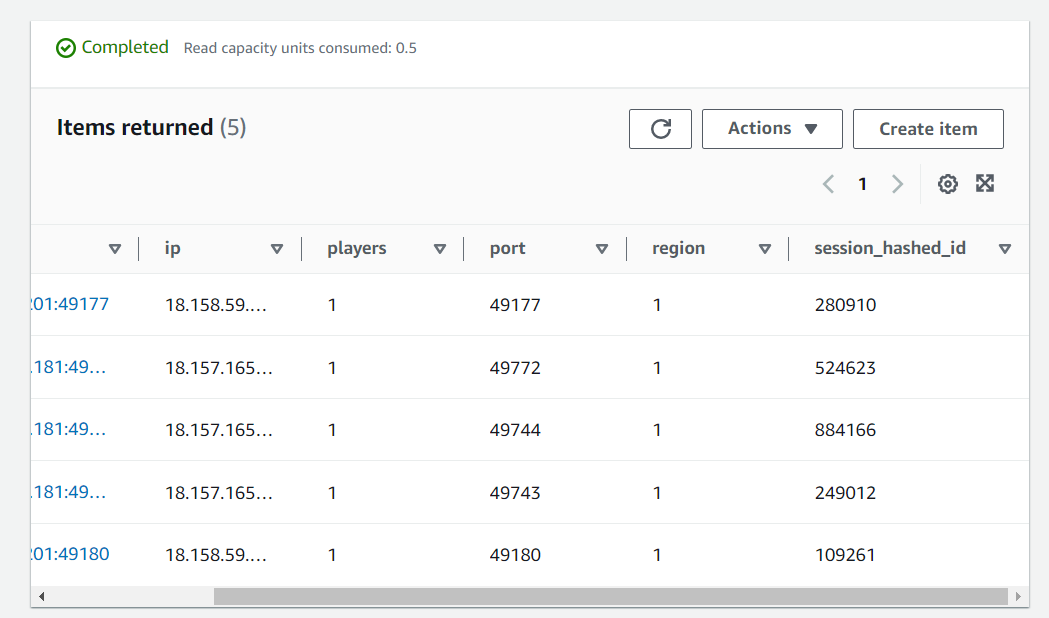
С кем теперь общается клиентская часть игры, с балансировщиком нагрузки или с самими серверами?
И то, и то. Можно попросить Auto Scaling, чтобы он каждой поднятой машине назначал свой публичный IP:

Таким образом через балансировщик нагрузки мы можем подключится к любому случайному серверу, чтобы попросить его дать нам список сессий, или создать для нас сессию, а когда мы уже получим в ответ IP адрес и порт этой сессии, мы напрямую подключимся к той машине, которая её хостит.
Эффективность данной инфраструктуры
AWS предоставляет две категории мониторинга виртуальных машин: базовую и детальную (за дополнительную плату). Базовый мониторинг (насколько загружен процессор, диск, сеть и т.д.) собирает метрики каждые 5 минут и соответственно это вносит свои задержки в работу Auto Scaling, который и принимает решения, основываясь на этих метриках. Тут могут быть два решения, либо подключить детальный мониторинг, который будет собирать метрики каждую минуту или уменьшить порог, когда нужно поднимать ещё одну машину (допустим вместо средней загруженности процессора в 70% поставить 50%, чтобы Auto Scaling мог среагировать заранее).
Посмотрим на примере, забьем процессор нашей текущей виртуальной машины в target группе:
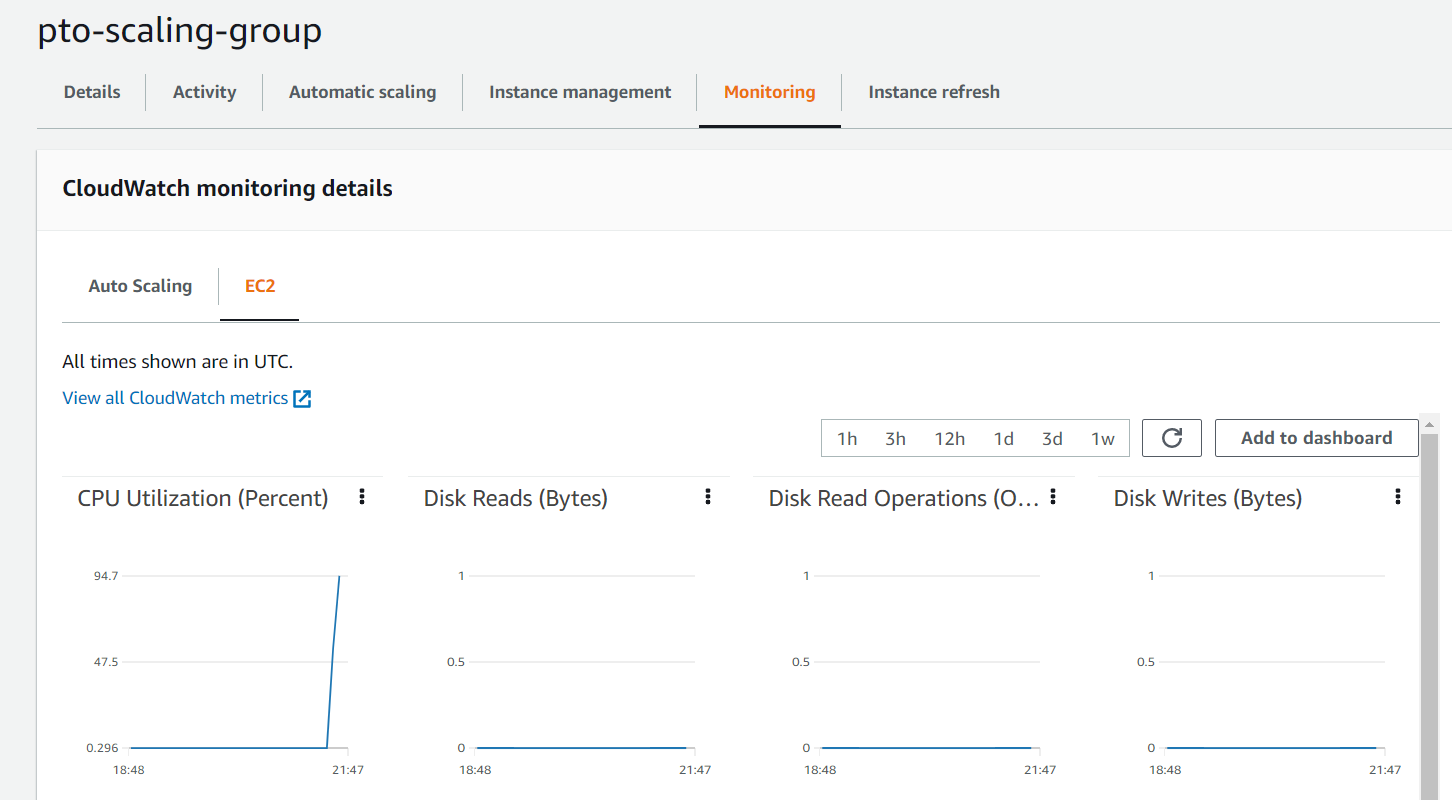
Auto Scaling устанавливает Desired Capacity (желаемое кол-во машин) с 1 на 2:
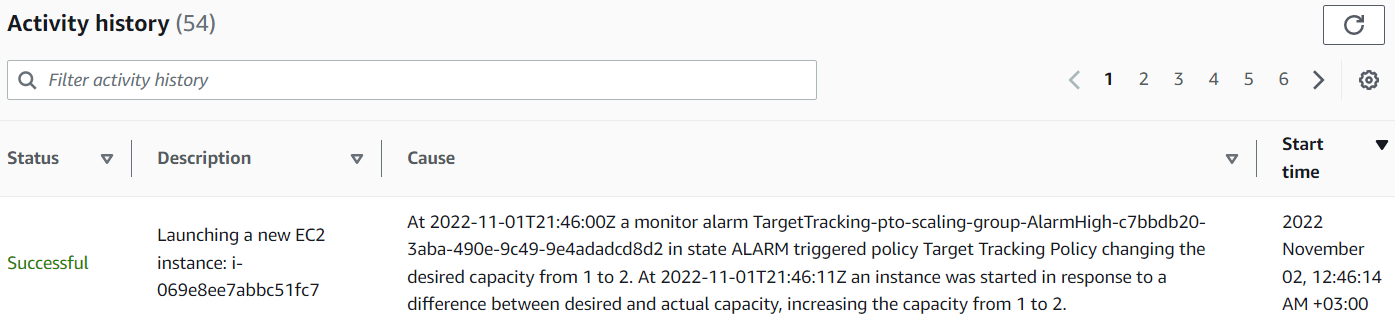
И мы видим её в Target группе:

Немного подождём и у нас две работающие виртуальные машины:
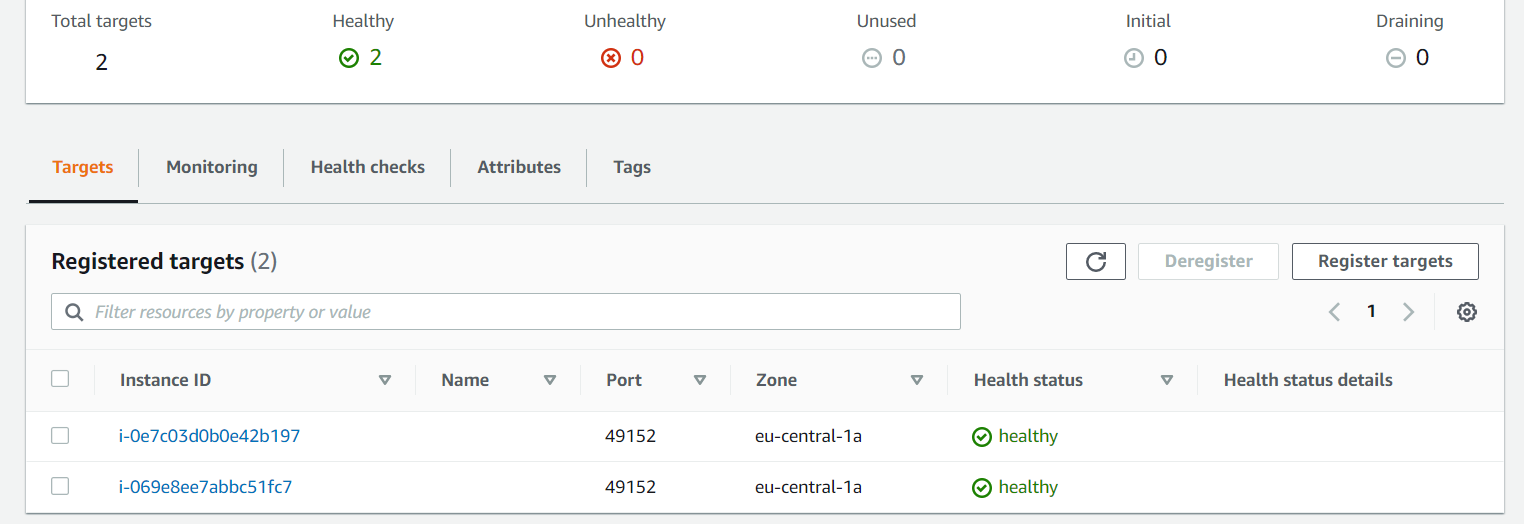
Отказоустойчивость (fault tolerance) при такой инфраструктуре
В случае если балансировщик нагрузки не смог достучаться до нашего сервера по указанному порту, машина данного сервера помечается как unhealthy, нездоровой. Auto Scaling это видит и спешит заменить эту машину на новую:

Защита от DDoS
Сервис AWS, представляющий защиту от DDoS, AWS Shield, доступен по подписке за 3000 долларов в месяц, такого увы, мы позволить себе не можем, но так или иначе, даже при DDoS атаке на сервера, даже в случае если они упадут, Auto Scaling через некоторое время их автоматически поднимет без нашего участия, так как балансировщик нагрузки просто не сможет достучаться до серверов на виртуальных машинах и пометит их нездоровыми. А новые сервера уже будут развернуты на новых IP адресах. То есть от самой атаки инфраструктура не защищена, но последствия более менее сглаживает, как минимум не придется бегать и руками что-то поднимать, разве что у игроков немного испортиться настроение из-за потерянной игровой сессии.
Подводные камни такой инфраструктуры
Они есть, когда Auto Scaling начинает уменьшать количество машин (нагрузка на сервера снизилась), то данному сервису все-равно, что игроки возможно все еще играют на удаляемой машине и у них там игровая сессия, соответственно, она просто теряется и у игроков портится впечатление.
Благо тут нашлось работающее решение, AWS позволяет заблокировать и разблокировать некоторые Auto Scaling процессы, нас интересует процесс Termination, который удаляет машины. Что мы делаем, мы при создании каждой машины даём ей разрешение (через роль в AWS) на выполнение командных строк в Auto Scaling сервисе:
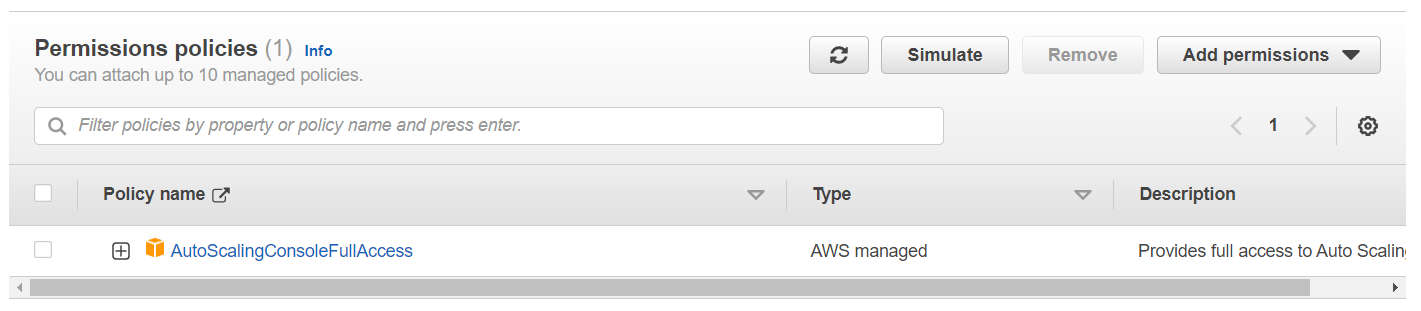
Каждая машина в Target группе периодически проверяет список сессий в DynamoDB и если она видит, что сейчас есть хотя бы одна сессия, то она блокирует Auto Scaling’у возможность удалять виртуальные машины, а если видит, что сессий нет, то наоборот разрешает:
# заблокировать возможность удаления машин
aws autoscaling suspend-processes --auto-scaling-group-name <scaling-group-name> --scaling-processes Terminate
# разблокировать возможность удаления машин
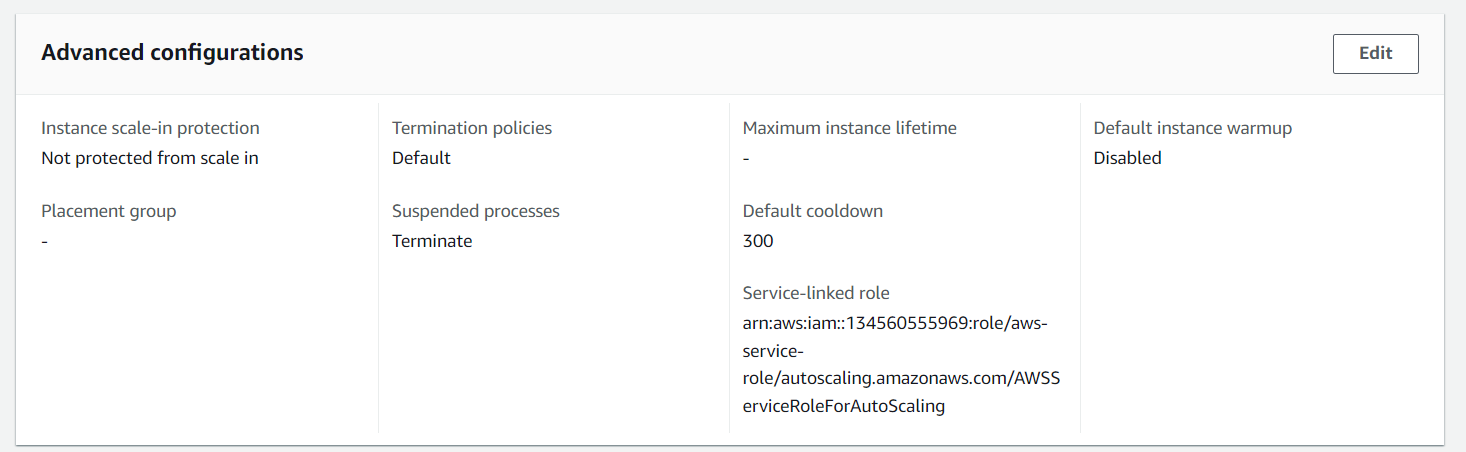
aws autoscaling resume-processes --auto-scaling-group-name <scaling-group-name> --scaling-processes TerminateПо итогу, если у нас есть хотя бы одна сессия, то процесс Terminate помечается как Suspended (Приостановленный) для Auto Scaling’а:
Сколько выходит по цене
Цена здесь будет варьироваться в зависимости от потребления игроков и от того, в скольких регионах вы выкладываете данную архитектуру. В моем случае, так как игра ещё не вышла, адекватной статистики у меня пока нет, но ситуация складывается следующая:
-
Виртуальные машины EC2 — по одной на каждый из 3-ёх регионов, t2.micro, стоят 10 долларов в месяц, однако AWS даёт одну t2.micro машину бесплатно на каждый месяц, поэтому в сумме выходит 20 долларов, это если Auto Scaling не будет поднимать больше никаких машин, т.е. если в игру никто не будет заходить
-
DynamoDB — бесплатно, AWS даёт 25 ГБ памяти для сервиса DynamoDB как free tier, а для нашего временного хранилища сессий — это более, чем достаточно
-
Балансировщик нагрузки — почасовая оплата за каждый гигабайт трафика, однако игроки не будут использовать его для прямого TCP подключения к игровой сессии, поэтому такой трафик вряд-ли удасться достичь
-
Auto Scaling сервис — бесплатный
-
Могут быть небольшие платежи за CloudWatch, которые собирает логи и метрики, а также за использование нескольких IP адресов поднятыми машинами
В целом, динамически масштабируемая архитектура позволила добиться отказоустойчивости и значительно снизить цену за аренду виртуальных ресурсов. Как для инди-разработчика, считаю это идеальным решением.
Заключение
Проникнуться тем, какие бывают игровые сервера, как устроена их архитектура, какие существуют приемы для их оптимизации, как их развертывать в облаке стали для меня настоящей страстью за эти полтора года. Я очень рад, что получилось довести серверную архитектуру проекта до такого состояния и надеюсь что начинающему интересоваться игровыми серверами разработчику поможет мой опыт изложенный в этих статьях. Всем спасибо, кто прочитал до конца!
Предисловие
Прошёл почти год с тех пор, как я написал техническую статью, потому что в этом году я инвестировал в разработку некоторых конкретных игровых проектов. Эти новые игровые проекты ближе к самостоятельной разработке игр. Я считаю, что технология серверного фреймворка «предка» компании не подходит, поэтому я написал серверный фреймворк игры с нуля, чтобы добиться большей эффективности и гибкости разработки. Теперь, когда проект вот-вот будет запущен, я хотел бы, когда у меня будет время, резюмировать процесс проектирования и реализации такой инфраструктуры игрового сервера.
Базовая операционная среда этого фреймворка — Linux, написанная на C ++. Чтобы иметь возможность запускать и использовать в различных средах, «старый» компилятор, gcc 4.8, адаптирован и разработан со спецификацией C99.
спрос
Поскольку «более общий код — более бесполезный», в начале разработки я думал, что для построения всей системы следует использовать многоуровневую модель. В соответствии с общими потребностями игровых серверов, самый простой можно разделить на два уровня:
- Базовые функции, лежащие в основе: в том числе связь, постоянство и другие очень общие части, с упором на производительность, простоту использования, масштабируемость и другие показатели.
- Функции логики высокого уровня: включая особую игровую логику, разные дизайны для разных игр.

Я надеюсь, что у меня будет практически полная структура «низкоуровневых базовых функций», которую можно будет повторно использовать в нескольких разных играх. Потому что цель — разработать среду игрового сервера, подходящую для независимой разработки игр. Итак, самый простой анализ спроса:
Функциональные требования
- Параллелизм: все серверные программы будут сталкиваться с этой основной проблемой: как справиться с параллельной обработкой. Вообще говоря, есть две технологии: многопоточность и асинхронность. Многопоточное программирование больше соответствует привычкам человеческого мышления при кодировании, но при этом возникает проблема «блокировки». В асинхронной неблокирующей модели выполнение программы относительно просто, и производительность оборудования может быть полностью использована, но проблема в том, что нужно писать много кода в форме «обратного вызова», что кажется сложным для бизнес-логики. Очень громоздко и плохо читается. Хотя у этих двух схем есть свои плюсы и минусы, и некоторые люди комбинируют эти две технологии, чтобы получить свои сильные стороны, но я предпочитаю использовать асинхронные, однопоточные, неблокирующие методы планирования, потому что эта схема является наиболее понятной и простой. , Чтобы решить проблему «обратного вызова», мы можем добавить поверх нее другие уровни абстракции, такие как сопрограммы или добавление пулов потоков и других технологий для ее улучшения.
- Связь: поддержка режима ответа на запрос и связь в режиме уведомления (широковещательная передача рассматривается как многоцелевое уведомление). В игре есть множество функций, таких как вход в систему, покупка и продажа и открытие рюкзаков, все из которых четко запрашиваются и получают ответ. В большом количестве онлайн-игр местоположение нескольких клиентов, HP и других устройств необходимо синхронизировать через сеть, что на самом деле является методом связи с «проактивным уведомлением».
- Постоянство: может получить доступ к объектам. Формат игрового архива очень сложен, но требования к индексации часто основываются на идентификаторе игрока для чтения и записи. На многих игровых консолях, таких как PlayStation, предыдущие архивы можно хранить на карте памяти аналогичным «файловым» способом. Итак, самым основным требованием для сохранения игры является модель доступа «ключ-значение». Конечно, в игре будут более сложные требования к постоянству, такие как рейтинги, аукционные дома и т. Д. Эти требования следует рассматривать дополнительно, и они не подходят для включения в самый базовый общий нижний уровень.
- Кеширование: поддержка удаленного кэширования распределенных объектов. Игровые сервисы в основном являются сервисами с отслеживанием состояния, потому что игры требуют очень значительных задержек ответа и в основном должны использовать память серверного процесса для хранения данных процесса. Однако игровые данные часто меняются быстрее и снижают свою ценность, например ценность опыта, золотые монеты, HP, и чем медленнее изменяется уровень, оборудование и т. Д., Тем выше значение.Эта функция очень подходит для модели кеширования. иметь дело с.
- Coroutine: вы можете использовать C ++ для написания кода сопрограммы, избегая большого количества функций обратного вызова для разделения кода. Это очень полезная функция для асинхронного кода, которая может значительно улучшить читаемость кода и эффективность разработки. В частности, многие базовые функции, связанные с вводом-выводом, предоставляются с сопрограммным API, который будет столь же простым и удобным в использовании, как и синхронный API.
- Скрипт: Первоначальная идея — поддержать Lua для написания бизнес-логики. Как известно, изменения спроса на игру происходят быстро, и написание бизнес-логики на языке сценариев может обеспечить эту поддержку. На самом деле скрипты широко используются в игровой индустрии. Следовательно, поддержка скриптов также является очень важной возможностью инфраструктуры игрового сервера.
- Другие функции: включая таймеры, управление объектами на стороне сервера и т. Д. Эти функции очень часто используются, поэтому их необходимо включить в структуру, но уже существует много зрелых решений, поэтому просто выберите общую и простую для понимания модель. Например, для управления объектами я буду использовать компонентную модель, аналогичную Unity для достижения.
Нефункциональные требования
- Гибкость: поддержка заменяемых протоколов связи; заменяемые постоянные устройства (например, базы данных); сменные устройства кэширования (например, memcached / redis); публикация в виде статических библиотек и файлов заголовков, а также недопущение перегрузки пользовательского кода Требования. Операционная среда игры более сложная, особенно между разными проектами, которые могут использовать разные базы данных и разные протоколы связи. Но большая часть бизнес-логики самой игры разработана на основе объектной модели, поэтому должна быть модель, которая может абстрагировать все эти базовые функции на основе «объектов». Только так можно разработать несколько разных игр на основе набора нижних слоев.
- Удобство развертывания: поддерживает файлы гибкой конфигурации, параметры командной строки и ссылки на переменные среды; поддерживает запуск отдельных процессов, не полагаясь на такие средства, как базы данных и промежуточное программное обеспечение очереди сообщений. Как правило, игры имеют по крайней мере три операционных среды, включая среду разработки, внутреннюю среду тестирования и внешнюю среду тестирования или операционную среду. Обновление версии игры часто требует обновления нескольких сред. Поэтому вопрос о том, как максимально упростить развертывание, стал очень важным. Я думаю, что хорошая серверная структура должна позволить запускать эту серверную программу независимо, без конфигурации и зависимости, чтобы обеспечить быстрое развертывание в средах разработки, тестирования и демонстрации. И его можно запустить во внешней тестовой или операционной среде в кластере, просто используя файлы конфигурации или параметры командной строки.
- Производительность: многие игровые серверы используют асинхронные и неблокирующие методы программирования. Поскольку асинхронная неблокировка может очень хорошо повысить пропускную способность сервера и может четко контролировать порядок выполнения кода для нескольких пользовательских задач одновременно, тем самым избегая сложных проблем, таких как многопоточные блокировки. Так что я также надеюсь, что эта структура основана на асинхронной неблокирующей системе в качестве базовой модели параллелизма. Это имеет еще одно преимущество, то есть вы можете вручную управлять определенными процессами и в полной мере использовать производительность многоядерных серверов ЦП. Конечно, читабельность асинхронного кода будет затруднена из-за большого количества функций обратного вызова.К счастью, мы можем использовать «сопрограммы» для решения этой проблемы.
- Масштабируемость: поддержка связи между серверами, управление состоянием процессов, управление кластером аналогично SOA. Автоматическое аварийное восстановление и автоматическое расширение, по сути, ключевым моментом является синхронизация и управление статусом процесса обслуживания. Я надеюсь, что общий нижний уровень может управлять всеми вызовами между серверами с помощью единой централизованной модели управления, так что каждый проект больше не заботится о межкластерной коммуникации, адресации и других проблемах.
После уточнения требований можно также разработать базовую иерархическую структуру:
|
уровень |
Характеристики |
ограничение |
|---|---|---|
|
Логический слой |
Реализуйте более конкретную бизнес-логику |
Может вызывать весь код нижнего уровня, но в основном должен полагаться на уровень интерфейса |
|
Уровень реализации |
Реализация различных специфических протоколов связи, запоминающих устройств и других функций |
Удовлетворить нижний уровень интерфейса для реализации и запретить взаимные вызовы между одними и теми же уровнями |
|
Слой интерфейса |
Определите базовое использование каждого модуля, чтобы изолировать конкретную реализацию и дизайн, тем самым обеспечивая возможность замены друг друга. |
Код между этим слоем может вызывать друг друга, но запрещено вызывать верхний код. |
|
Слой инструмента |
Предоставляет общие функции библиотеки инструментов C ++, такие как log / json / ini / date and time / string processing и т. Д. |
Не должен вызывать код другого уровня и не должен вызывать другие модули на том же уровне. |
|
Сторонняя библиотека |
Предоставляет такие функции, как redis / tcaplus или другие готовые функции, с тем же статусом, что и «уровень инструментов» |
Не следует вызывать другие слои кода или даже изменять его исходный код. |
Наконец, общий модуль архитектуры похож:
|
Описание |
связь |
процессор |
кэш |
Упорство |
|---|---|---|---|---|
|
Реализация функции |
TcpUdpKcpTlvLine |
JsonHandlerObjectProcessor |
SessionLocalCacheRedisMapRamMapZooKeeperMap |
FileDataStoreRedisDataStroe |
|
Определение интерфейса |
TransferProtocol |
ServerClientProcessor |
DataMapSerializable |
DataStore |
|
Библиотека инструментов |
ConfigLOGJSONCoroutine |
Коммуникационный модуль
Для коммуникационного модуля он должен иметь возможность гибких и заменяемых протоколов, и он должен быть дополнительно разделен в соответствии с определенным уровнем. Для игр самый низкий протокол связи обычно использует TCP и UDP. Между серверами также используется программное обеспечение для связи, такое как промежуточное ПО для очереди сообщений. Платформа должна иметь возможность поддерживать эти протоколы связи. Поэтому уровень оформлен как:Transport
На уровне протокола самые основные требования включают «субподряд», «распространение» и «сериализацию объекта». Если вы хотите поддерживать режим «запрос-ответ», вам также необходимо привести данные «серийного номера» в протокол, чтобы они соответствовали «запросу» и «ответу». Кроме того, игры обычно представляют собой своего рода «разговорные» приложения, то есть последовательность запросов будет рассматриваться как «беседа», что требует аналогичногоSession ID Такого рода данные. Чтобы удовлетворить эти потребности, уровень разработан как:Protocol
С помощью двух вышеупомянутых уровней можно реализовать самые основные возможности уровня протокола. Однако мы часто надеемся, что пакет протоколов бизнес-данных может автоматически стать объектом в программировании, поэтому при обработке тела сообщения требуется дополнительный дополнительный уровень для преобразования массива байтов в объект. Поэтому я разработал специальный процессор:ObjectProcessor , Стандартизировать интерфейс сериализации и десериализации объектов в коммуникационном модуле.
|
войти |
уровень |
Характеристики |
Вывод |
|---|---|---|---|
|
data |
Transport |
связь |
buffer |
|
buffer |
Protocol |
субподряд |
Message |
|
Message |
Processor |
распределение |
object |
|
object |
Модуль обработки |
иметь дело с |
Бизнес-логика |
Transport
Этот уровень настроен для унификации различных базовых протоколов передачи и на самом базовом уровне должен поддерживать TCP и UDP. Абстракция протокола связи на самом деле очень хорошо реализована во многих низкоуровневых библиотеках, таких как библиотека сокетов Linux, чей API чтения и записи может даже использоваться для чтения и записи файлов. Библиотека Socket в C # находится между TCP и UDP, и ее api почти такой же. Но из-за роли игрового сервера многие подходящие также будут иметь доступ к некоторому специальному «уровню доступа», например к некоторым прокси-серверам или некоторому промежуточному программному обеспечению сообщений, эти API-интерфейсы разнообразны. Кроме того, в играх html5 (например, мини-играх WeChat) и некоторых веб-играх существует традиция использования HTTP-серверов в качестве игровых серверов (например, с использованием протокола WebSocket), что требует совершенно другого транспортного уровня.
Базовая последовательность использования транспортного уровня сервера в асинхронной модели:
- В основном цикле продолжайте пытаться прочитать, какие данные доступны для чтения
- Если данные поступают с предыдущего шага, прочтите данные
- После чтения данных и обработки вам необходимо отправить данные, а затем записать данные в сеть.
В соответствии с тремя вышеупомянутыми характеристиками можно резюмировать базовый интерфейс:
class Transport {
public:
/**
* Инициализируйте транспортный объект, введите объект конфигурации, чтобы настроить максимальное количество соединений и другие параметры, которые могут быть новым объектом конфигурации.
*/
virtual int Init(Config* config) = 0;
/**
* Проверить, есть ли данные для чтения, и вернуть количество читаемых событий. Последующий код должен вызвать Read () для извлечения данных на основе этого возвращаемого значения.
* Параметр fds используется для возврата списка всех fd, в которых произошло событие, а len представляет максимальную длину этого списка. Если доступных событий больше, чем это число, это не влияет на количество последующих Read ().
* Если содержимое fds оказывается отрицательным, это означает, что есть новый терминал, ожидающий доступа.
*/
virtual int Peek(int* fds, int len) = 0;
/**
* Считайте данные в сетевом конвейере. Данные помещаются в буфер узла выходных параметров.
* Параметр @param peer - это коммуникационный одноранговый объект, сгенерировавший событие.
* @return Возвращаемое значение - длина читаемых данных. Если оно равно 0, данных для чтения нет, а возвращается -1, чтобы указать, что соединение необходимо закрыть.
*/
virtual int Read( Peer* peer) = 0;
/**
* Запись данных, output_buf, buf_len - это буферы данных для записи, а output_peer - конечная цель целевой группы,
* Возвращаемое значение указывает длину успешно записанных данных. -1 указывает на ошибку записи.
*/
virtual int Write(const char* output_buf, int buf_len, const Peer& output_peer) = 0;
/**
* Закройте соединение на противоположном конце
*/
virtual void ClosePeer(const Peer& peer) = 0;
/**
* Закройте транспортный объект.
*/
virtual void Close() = 0;
}
В приведенном выше определении вы можете видеть, что требуется тип однорангового узла. Этот тип предназначен для представления клиентского (однорангового) объекта связи. В общих системах Linux мы обычно используем fd (описание файла) для представления. Но поскольку во фреймворке нам также необходимо создать буферную область для приема данных для каждого клиента, а также для записи адресов связи и других функций, поэтому такой тип инкапсулируется на основе fd. Это также способствует инкапсуляции UDP-коммуникаций в различных клиентских моделях.
/// @ short Этот тип отвечает за хранение информации о подключенном клиенте и буфера данных
class Peer {
public:
int buf_size_; /// <длина буфера
char * const buffer _; /// <начальный адрес буфера
int producted_pos_; /// <заполненная длина данных
int Consmed_pos_; /// <Длина потребляемых данных
int GetFd() const;
void SetFd (int fd); /// Получить локальный адрес
const struct sockaddr_in& GetLocalAddr() const;
void SetLocalAddr (const struct sockaddr_in & localAddr); /// Получить удаленный адрес
const struct sockaddr_in& GetRemoteAddr() const;
void SetRemoteAddr(const struct sockaddr_in& remoteAddr);
private:
int fd_; /// <fd для отправки и получения данных
struct sockaddr_in remote_addr_; /// <удаленный адрес
struct sockaddr_in local_addr_; /// <локальный адрес
};
Особенности протокола UDP, используемого в игре: Вообще говоря, UDP не требует установления соединения, но для игр определенно необходим чистый клиент, поэтому вы не можете просто использовать fd сокета UDP для представления клиента, что делает верхний код не может быть простым. Между UDP и TCP существует согласованность. Поэтому здесь используется уровень абстракции Peer, который может решить эту проблему. Это также можно использовать в случае использования какого-либо промежуточного программного обеспечения очереди сообщений, потому что это промежуточное программное обеспечение может также мультиплексировать fd и может даже не разрабатываться с использованием fd API.
Для приведенного выше определения транспорта его очень легко выполнить для разработчиков TCP. Но разработчикам UDP необходимо подумать о том, как использовать Peer, особенно Peer.fd_. Когда я его реализовал, я использовал механизм виртуального fd, чтобы предоставить верхнему уровню функцию различения клиента через соответствующую карту от IPv4-адреса клиента до int. В Linux эти операции ввода-вывода могут быть реализованы с помощью библиотеки epoll. Прочтите события ввода-вывода в функции Peek () и заполните вызов сокета в Read () / Write ().
Кроме того, для обеспечения связи между серверами необходимо разработать тип, соответствующий Tansport: Connector. Этот абстрактный базовый класс используется для инициирования запросов к серверу в клиентской модели. Его конструкция похожа на Transport. В дополнение к Connecotr в среде Linux я также реализовал код на C #, чтобы можно было удобно использовать клиент, разработанный с помощью Unity. Поскольку сама .NET поддерживает асинхронную модель, ее реализация не требует больших усилий.
/**
* @brief Класс соединителя, используемый клиентом, представляющий протокол передачи, например TCP или UDP.
*/
class Connector {
public: virtual ~Connector() {}
/**
* @brief инициализировать установление соединения и т. д.
* @param config требуемая конфигурация
* @return 0 - успех
*/
virtual int Init(Config* config) = 0;
/**
* @brief close
*/
virtual void Close() = 0;
/**
* @ кратко читайте, идут ли сетевые данные
* Прочтите, поступают ли данные, возвращаемое значение - количество читаемых событий, обычно 1
* Если он равен 0, это означает, что данные не могут быть прочитаны.
* Если он возвращает -1, это означает, что произошла сетевая ошибка и необходимо закрыть соединение.
* Если возвращается -2, это означает, что соединение успешно установлено с противоположным концом.
* @ вернуть сетевые данные
*/
virtual int Peek() = 0;
/**
* @ краткое прочтение номера сети
* Прочитать данные в соединении и вернуть количество прочитанных байтов.Если он возвращает 0, это означает, что данных нет.
* Если buffer_length равно 0, он также вернет 0,
* @return возвращает -1, чтобы указать, что соединение необходимо закрыть (все виды ошибок также возвращают 0)
*/
virtual int Read(char* ouput_buffer, int buffer_length) = 0;
/**
* @brief записывает данные из input_buffer в сетевое соединение и возвращает количество записанных байтов.
* @return Если он возвращает -1, это означает, что произошла ошибка записи и соединение необходимо закрыть.
*/
virtual int Write(const char* input_buffer, int buffer_length) = 0;
protected:
Connector(){}
};
Protocol
Для коммуникационного «протокола» он действительно имеет много значений. Среди множества требований уровень протокола, который я определил, рассчитывает только на выполнение четырех основных возможностей:
- Субподряд: возможность отделить отдельные блоки данных от уровня потоковой передачи или объединить несколько «фрагментов» данных в единый блок данных. Как правило, чтобы решить эту проблему, вам нужно добавить поле «длина» в заголовок протокола.
- Соответствие запроса и ответа: это очень важная функция для асинхронного неблокирующего режима связи. Потому что в один момент может быть отправлено много запросов, и ответы будут приходить без разбора. Если в заголовке протокола есть неповторяющееся поле «серийный номер», оно может соответствовать тому, какой ответ принадлежит какому запросу.
- Сохранение сеанса: поскольку базовая сеть игры может использовать непостоянные методы передачи, такие как UDP или HTTP, для логического поддержания сеанса, вы не можете полагаться только на уровень передачи. Кроме того, мы все надеемся, что программа способна противостоять дрожанию в сети, отключению и повторному подключению, поэтому поддержание сеанса стало обычным требованием. Я имею в виду функцию сеанса в области веб-служб и разработал функцию сеанса.Путем добавления данных, таких как идентификатор сеанса, в протокол, сеанс можно поддерживать относительно просто.
- Распространение: игровой сервер должен содержать несколько различных бизнес-логик, поэтому для пересылки данных в соответствующем формате требуется множество пакетов протоколов с разными форматами данных.
В дополнение к трем вышеупомянутым функциям на самом деле есть много других возможностей, которые мы надеемся реализовать на уровне протокола. Наиболее типичной из них является функция сериализации объектов, а также функции сжатия и шифрования. Причина, по которой я не включил возможность сериализации объектов в протокол, заключается в том, что «объект» в сериализации объектов — это концепция с очень сильной корреляцией с бизнес-логикой. В C ++ нет полной «объектной» модели и встроенной поддержки отражения, поэтому уровень кода не может быть легко разделен абстрактным понятием «объект». Но я также разработал ObjectProcessor для интеграции поддержки сериализации объектов в структуру в форме более высокого уровня. Этот процессор может настраивать метод сериализации объектов, так что разработчики могут сами выбирать любые возможности «кодирования и декодирования», не полагаясь на базовую поддержку.
Что касается таких функций, как сжатие и шифрование, они действительно могут быть реализованы на уровне протокола или даже добавлены к протоколу в качестве уровня абстракции. Возможно, только одного уровня протокола недостаточно для поддержки таких разнообразных функций. Необходимо разработать «подобие Apache Mina». Цепочка звонков «модель. Но для простоты я думаю, что лучше добавить дополнительные классы реализации протокола там, где вам нужно его использовать, например, добавление «типа протокола TLV с функцией сжатия».
Само сообщение преобразуется в тип, называемый Message, который имеет два поля заголовка сообщения: «имя службы» и «идентификатор сеанса» для выполнения функций «распространения» и «сохранения сеанса». Тело сообщения помещается в байтовый массив, и длина байтового массива записывается.
enum MessageType {
TypeError, /// <Неверное соглашение
TypeRequest, /// <Тип запроса, отправляемого от клиента к серверу
TypeResponse, /// <Тип ответа, сервер вернется после получения запроса
TypeNotice /// <Тип уведомления, сервер активно уведомляет клиента
};
/// @ short Базовый класс тела коммуникационного сообщения
/// В основном это буфер char []
struct Message {
public:
static int MAX_MAESSAGE_LENGTH;
static int MAX_HEADER_LENGTH;
MessageType type; /// <Информация о типе тела сообщения (MessageType)
virtual ~Message(); virtual Message& operator=(const Message& right);
/**
* @brief копирует данные в этот буфер тела пакета
*/
void SetData(const char* input_ptr, int input_length);
/// @ краткий указатель на получение данных
inline char* GetData() const{
return data_;
}
/// @ short Получить длину данных
inline int GetDataLen() const{
return data_len_;
}
char* GetHeader() const;
int GetHeaderLen() const;
protected:
Message();
Message(const Message& message);
private:
char * data_; // буфер содержимого тела пакета
int data_len_; // длина тела пакета
};
В соответствии с двумя ранее разработанными режимами связи «запрос-ответ» и «уведомление», три типа сообщений должны быть разработаны для наследования от Message. Это:
- Запросить пакет запроса
- Ответный пакет ответа
- Пакет уведомлений
Оба класса Request и Response имеют поле seq_id, в котором записан серийный номер, а Notice — нет. Класс Protocol отвечает за преобразование массива байтов буфера в объект подкласса Message. Следовательно, соответствующие методы Encode () / Decode () должны быть реализованы для всех трех подтипов сообщений.
class Protocol {
public:
virtual ~Protocol() {
}
/**
* @brief кодирует сообщение запроса в двоичные данные
* Кодирование, кодирование сообщения в buf, возврат времени записи данных, если оно превышает len, возврат -1, чтобы указать на ошибку.
* Если он возвращает 0, это означает, что кодирование не требуется, и фреймворк будет читать данные непосредственно из буфера сообщений и отправлять их.
* @param buf целевой буфер данных
* @param offset целевое смещение
* @param len длина целевых данных
* @param msg объект входного сообщения
* @return Количество байтов, использованных для завершения кодирования, если <0 означает ошибку
*/
virtual int Encode(char* buf, int offset, int len, const Request& msg) = 0;
/**
* Кодирование, кодирование сообщения в buf, возврат времени записи данных, если оно превышает len, возврат -1, чтобы указать на ошибку.
* Если он возвращает 0, это означает, что кодирование не требуется, и фреймворк будет читать данные непосредственно из буфера сообщений и отправлять их.
* @param buf целевой буфер данных
* @param offset целевое смещение
* @param len длина целевых данных
* @param msg объект входного сообщения
* @return Количество байтов, использованных для завершения кодирования, если <0 означает ошибку
*/
virtual int Encode(char* buf, int offset, int len, const Response& msg) = 0;
/**
* Кодирование, кодирование сообщения в buf, возврат времени записи данных, если оно превышает len, возврат -1, чтобы указать на ошибку.
* Если он возвращает 0, это означает, что кодирование не требуется, и фреймворк будет читать данные непосредственно из буфера сообщений и отправлять их.
* @param buf целевой буфер данных
* @param offset целевое смещение
* @param len длина целевых данных
* @param msg объект входного сообщения
* @return Количество байтов, использованных для завершения кодирования, если <0 означает ошибку
*/
virtual int Encode(char* buf, int offset, int len, const Notice& msg) = 0;
/**
* Начать кодирование и вернуть тип сообщения для декодирования, чтобы пользователь мог построить подходящий объект.
* Фактическая операция - это операция «субподряд».
* @param buf входной буфер
* @param offset входное смещение
* @param len длина буфера
* @param msg_type выходной параметр, который указывает тип следующего сообщения. Он действителен только тогда, когда возвращаемое значение> 0, в противном случае это TypeError.
* @return Если возвращается 0, субподряд не был завершен, и субподряд нужно продолжить. Если он возвращает -1, это означает, что произошла ошибка синтаксического анализа заголовка протокола. Другие возвращаемые значения указывают длину этого пакета сообщения.
*/
virtual int DecodeBegin(const char* buf, int offset, int len,
MessageType* msg_type) = 0;
/**
* Декодировать, декодировать данные buf из DecodeBegin () в определенный объект сообщения.
* параметр вывода запроса @param, объект декодирования запишет этот указатель
* @return возвращает 0 в случае успеха, -1 в случае неудачи.
*/
virtual int Decode(Request* request) = 0;
/**
* Декодировать, декодировать данные buf из DecodeBegin () в определенный объект сообщения.
* параметр вывода запроса @param, объект декодирования запишет этот указатель
* @return возвращает 0 в случае успеха, -1 в случае неудачи.
*/
virtual int Decode(Response* response) = 0;
/**
* Декодировать, декодировать данные buf из DecodeBegin () в определенный объект сообщения.
* параметр вывода запроса @param, объект декодирования запишет этот указатель
* @return возвращает 0 в случае успеха, -1 в случае неудачи.
*/
virtual int Decode(Notice* notice) = 0;protected:
Protocol() {
}
};
Здесь следует отметить, что, поскольку C ++ не имеет возможности собирать мусор памяти и отражать, при интерпретации данных char [] не может быть преобразован в объект подкласса за один шаг, но должен быть обработан за два шага.
- Сначала вернитесь через DecodeBegin (), подтип которого принадлежит данным, которые нужно декодировать. В то же время работа по субподряду завершена, и вызывающая сторона получает информацию о том, был ли получен пакет полностью.
- Вызовите Decode () с соответствующим типом в качестве параметра, чтобы записать данные в соответствующую выходную переменную.
Для конкретного подкласса реализации протокола я сначала реализовал LineProtocol, который представляет собой очень свободный протокол, основанный на текстовой кодировке ASCII, разделенных полями пробелами и подпакетом с возвратом каретки. Используется для проверки возможности реализации этой структуры. Потому что таким образом вы можете напрямую использовать инструмент telnet для тестирования кодека протокола. Затем я разработал двоичный протокол в соответствии с методом TLV (значение длины типа). Примерное определение выглядит следующим образом:
Заключение субподряда на протокол: [тип сообщения: int: 2] [длина сообщения: int: 4] [содержание сообщения: байты: длина сообщения]
Значение типа сообщения:
- 0x00 Error
- 0x01 Request
- 0x02 Response
- 0x03 Notice
|
Тип упаковки |
поле |
Детали кодирования |
|---|---|---|
|
Request |
наименование услуги |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
|
серийный номер |
[Поле: int: 2] [Целочисленное содержание: int: 4] |
|
|
Идентификатор сессии |
[Поле: int: 2] [Целочисленное содержание: int: 4] |
|
|
Тело сообщения |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
|
|
Response |
наименование услуги |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
|
серийный номер |
[Поле: int: 2] [Целочисленное содержание: int: 4] |
|
|
Идентификатор сессии |
[Поле: int: 2] [Целочисленное содержание: int: 4] |
|
|
Тело сообщения |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
|
|
Notice |
наименование услуги |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
|
Тело сообщения |
[Поле: int: 2] [длина: int: 2] [содержимое строки: символы: длина сообщения] |
Тип с именем TlvProtocol завершает реализацию этого протокола.
Processor
Уровень процессора — это абстрактный уровень, который я разработал для взаимодействия с конкретной бизнес-логикой. Он в основном получает входные данные клиента через входные параметры Request и Peer, а затем возвращает сообщения Response и Notice через Reply () / Inform () класса Server. Фактически, подклассы транспорта и протокола принадлежатnet Модули и различные типы функций процессора и сервера / клиента принадлежат другомуprocessor Модуль. Причина такого дизайна в том, что всеprocessor Односторонняя зависимость кода модуляnet Код модуля, но обратное неверно.
Базовый класс процессора очень прост, это запись функции обратного вызова функции обработки.Process():
/// @ short базовый класс процессора, обеспечивающий интерфейс обратного вызова бизнес-логики
class Processor {
public:
Processor();
virtual ~Processor();
/**
* Инициализировать процессор, сервер параметров предоставляет базовый интерфейс для бизнес-логики.
*/
virtual int Init(Server* server, Config* config = NULL);
/**
* Пакет типа «запрос-ответ» реализует этот метод, возвращаемое значение - 0, что указывает на успех, в противном случае он будет записан в журнал ошибок.
* Параметр peer указывает на ситуацию однорангового узла, отправившего запрос. Указатель объекта Server можно использовать для вызова Reply (),
* Inform () и другие методы. Если вы отслеживаете несколько серверов, параметр server будет другим объектом.
*/
virtual int Process(const Request& request, const Peer& peer,
Server* server);
/**
* Close для очистки ресурсов, занятых процессором
*/
virtual int Close();
};
После разработки трех уровней обработки связи Транспорт / Протокол / Процессор необходим код, объединяющий эти три уровня, то есть класс Сервер. Когда этот класс находится в Init (), ему требуются три вышеуказанных типа подклассов в качестве параметров для объединения в серверы с различными функциями, такими как:
TlvProtocol tlv_protocol; // Тип Длина Значение Формат пакета протокола, который должен согласовываться с клиентом TcpTransport tcp_transport; // Используем протокол связи TCP, по умолчанию прослушивание 0.0.0.0:6666 EchoProcessor echo_processor; // процессор бизнес-логики Server server; // главный объект веб-сервера DenOS server.Init (& tcp_transport, & tlv_protocol, & echo_processor); // Собираем объект игрового сервера: кодирование TLV, связь TCP и эхо-сервис
Тип Server также нуждается в функции Update (), которая позволяет непрерывно вызывать «основной цикл» пользовательского процесса для управления всей программой. Содержание этой функции Update () очень ясное:
- Проверить, есть ли данные для обработки в сети (через транспортный объект)
- Если есть данные, декодируйте их (через объект протокола)
- После успешного декодирования вызывается бизнес-логика (через объект Processor)
Кроме того, серверу также необходимо обрабатывать некоторые дополнительные функции, такие как поддержание пула буферов сеанса (Session) и предоставление интерфейса для отправки сообщений Response и Notice. Когда все эти задачи будут выполнены, всю систему можно будет использовать как более «универсальную» структуру сервера сетевых сообщений. Остается только добавить работу различных подклассов транспорта / протокола / процессора.
class Server {
public:
Server();
virtual ~Server();
/**
* Для инициализации сервера вам необходимо выбрать сборку цепочки коммуникационных протоколов.
*/
int Init(Transport* transport, Protocol* protocol, Processor* processor, Config* config = NULL);
/**
* Метод блокировки, войдите в основной цикл.
*/
void Start();
/**
* Необходимо циклически вызывать метод вождения. Если возвращаемое значение - 0, это означает бездействие. Другие возвращаемые значения указывают количество обработанных задач.
*/
virtual int Update();
void ClosePeer (Peer * peer, bool is_clear = false); // Закрываем текущее соединение, is_clear указывает, окончательно ли оно очищено
/**
* Выключите сервер
*/
void Close();
/**
* Отправить уведомление определенному клиенту,
* Параметр peer представляет однорангового узла, который должен быть уведомлен.
*/
int Inform(const Notice& notice, const Peer& peer);
/**
* Отправить клиенту уведомление, соответствующее идентификатору сеанса, вернуть 0, чтобы указать, что его можно отправить, а другие значения отправить не удалось.
* Этот интерфейс может поддерживать отключенное повторное подключение, если клиент успешно подключился и использует старый идентификатор сеанса, он также действителен.
*/
int Inform(const Notice& notice, const std::string& session_id);
/**
* Отправить ответное сообщение на запрос, отправленный клиентом.
* Seqid элемента ответа параметра должен быть правильно заполнен для правильного ответа.
* Возвращает 0 в случае успеха, другие значения (-1) указывают на неудачу.
*/
int Reply(Response* response, const Peer& peer);
/**
* Отправить ответное сообщение клиенту, соответствующее идентификатору сеанса.
* Система-член seqid ответа с параметром автоматически подставит значение, записанное в сеансе.
* Этот интерфейс может поддерживать отключенное повторное подключение, если клиент успешно подключился и использует старый идентификатор сеанса, он также действителен.
* Возвращает 0 в случае успеха, другие значения (-1) указывают на неудачу.
*/
int Reply(Response* response, const std::string& session_id);
/**
* Функция разговора
*/
Session* GetSession(const std::string& session_id = "", bool use_this_id = false);
Session* GetSessionByNumId(int session_id = 0);
bool IsExist(const std::string& session_id);
};
С типом сервера также должен быть тип клиента. Тип Client по конструкции аналогичен серверу, но вместо транспортного интерфейса в качестве транспортного уровня он использует интерфейс коннектора. Однако уровень абстракции протокола можно полностью повторно использовать. Клиент не нуждается в обратном вызове в форме процессора, но напрямую передает объект интерфейса ClientCallback, который инициирует обратный вызов после получения сообщения с данными.
class ClientCallback {
public:
ClientCallback() {
}
virtual ~ClientCallback() {
// Do nothing
}
/**
* Обратный вызов этого метода после успешного установления соединения.
* @return возвращает -1, чтобы указать, что это соединение не принято, и это соединение необходимо закрыть.
*/
virtual int OnConnected() {
return 0;
}
/**
* Когда сетевое соединение закрыто, вызовите этот метод
*/
virtual void OnDisconnected() { // Do nothing
}
/**
* Этот метод будет вызываться при получении ответа или при истечении времени ожидания запроса.
* @param response Ответ, отправленный с сервера
* @return Если возвращается ненулевое значение, сервер распечатывает журнал ошибок.
*/
virtual int Callback(const Response& response) {
return 0;
}
/**
* Когда в запросе возникает ошибка, например тайм-аут, вернуть эту ошибку
* @param код ошибки err_code
*/
virtual void OnError(int err_code){
WARN_LOG("The request is timeout, err_code: %d", err_code);
}
/**
* Этот метод будет вызываться при получении уведомления
*/
virtual int Callback(const Notice& notice) {
return 0;
}
/**
* Возвращает, следует ли удалить этот объект. Этот метод будет вызываться перед вызовом Callback ().
* @return Если он вернет true, будет вызван указатель удаления этого объекта.
*/
virtual bool ShouldBeRemoved() {
return false;
}
};
class Client : public Updateable {
public:
Client(); virtual ~Client();
/**
* подключиться к серверу
* @param connector Протокол передачи, такой как TCP, UDP ...
* @param protocol Протокол субподряда, такой как TLV, Line, TDR ...
* @param notice_callback Объект обратного вызова, запускаемый после получения уведомления.Если протокол передачи имеет «концепцию соединения» (например, TCP / TCONND), он также будет вызываться при установке или закрытии соединения.
* @param config объект файла конфигурации, будет читать следующие элементы конфигурации: MAX_TRANSACTIONS_OF_CLIENT максимальное количество одновременных подключений клиента; BUFFER_LENGTH_OF_CLIENT кэш приема клиентских пакетов; CLIENT_RESPONSE_TIMEOUT время ожидания ответа клиента.
* @return возвращает 0, чтобы указать успех, другие указывают на неудачу
*/
int Init(Connector* connector, Protocol* protocol,
ClientCallback* notice_callback = NULL, Config* config = NULL);
/**
* Параметр обратного вызова может иметь значение NULL, что означает, что ответа не требуется, просто отправьте пакет.
*/
virtual int SendRequest(Request* request, ClientCallback* callback = NULL);
/**
* Возвращаемое значение указывает, сколько данных необходимо обработать. Возврат -1 означает ошибку и соединение необходимо закрыть. Возвращение 0 означает, что нет данных для обработки.
*/
virtual int Update();
virtual void OnExit();
void Close();
Connector* connector() ;
ClientCallback* notice_callback() ;
Protocol* protocol() ;
};
На этом базовая конструкция клиента и сервера завершена, и вы можете напрямую проверить, нормально ли они работают, написав тестовый код.
Многие разработчики начинают разработку многопользовательского онлайн сервера на основе библиотеки socket.io. Эта библиотека позволяет очень просто реализовать обмен данными между клиетом и сервером в реальном времени, но продумать и реализовать всю логику и интерфейс взаимодействия сервера с клиентами, а также архитектуру масштабирования и оптимизацию трафика все равно придется.
Я хочу рассказать про библиотеку magx, используя которую можно не задумываться о сетевой составляющей (коммуникации сервера и клиентов), a сразу сконцентрироваться на разработке логики игры и клиентского UI.
При разработке архитектуры многопользовательсой игры обычно рассматриваются 2 подхода: с авторитарным сервером и не-авторитарным (авторитарным клиентом). Оба эти подхода поддерживаются библиотекой magx. Начнем с более простого подхода — не-авторитарного.
Не-авторитарный сервер
Суть его в том, что сервер не контролирует результаты ввода каждого игрока. Клиенты самостоятельно отслеживают введенные игроком действия и игровую логику локально, после чего высылают результат определенного действия на сервер. После этого сервер синхронизирует все совершенные действия с игровым состоянием других клиентов.
Это легче реализовать с точки зрения архитектуры, так как сервер отвечает только лишь за коммуникацию между клиентами, не делая никаких дополнительных вычислений, которые делают клиенты.
С помощью библиотеки magx такой сервер можно реализовать всего в несколько строк кода:
import * as http from "http"
import { Server, RelayRoom } from "magx"
const server = http.createServer()
const magx = new Server(server)
magx.define("relay", RelayRoom)
// start server
const port = process.env.PORT || 3001
server.listen(port, () => {
console.info(`Server started on http://localhost:${port}`)
})Теперь, чтобы подключить клиентов к этому серверу и начать их взаимодействие, достаточно установить js библиотеку:
npm install --save magx-client
и подключить ее к проекту:
import { Client } from "magx-client"Также можно воспользовать прямой ссылкой для использования в HTML:
<script src="https://cdn.jsdelivr.net/npm/magx-client@0.7.1/dist/magx.js"></script>После подключиеня, всего несколько строк позволят настроить соединение и взаимодействие с сервером:
// authenticate to server
await client.authenticate()
// create or join room
const rooms = await client.getRooms("relay")
room = rooms.length
? await client.joinRoom(rooms[0].id)
: await client.createRoom("relay")
console.log("you joined room", name)
// handle state patches
room.onPatch((patch) => updateState(patch))
// handle state snapshot
room.onSnapshot((snapshot) => setState(snapshot))
// handle joined players
room.onMessage("player_join", (id) => console.log("player join", id))
// handle left players
room.onMessage("player_leave", (id) => console.log("player leave", id))Детальный пример как построить взаимодействие между клиентами и не-авторитарным сервером описано в соответствующем примере в проекте magx-examples.
Авторитарный сервер
В авторитарном сервере обработка и выполнение всех действий, затрагивающих игровой процесс, применение правил игры и обработки ввода от игроков-клиентов осуществляется на стороне сервера.
Клиент не может самостоятельно вносить какие-либо изменения в состояние игры. Вместо этого, он отправляет серверу, что конкретно он хочет сделать, сервер обрабатывает этот запрос, вносит изменения в состояние игры и отправляет обновленное состояние клиентам.
При таком подходе логика на клиенте сводится к минимуму, клиент начинает отвечать только за отрисовку состояния игры и обработку действий игрока. Преимущество такого подхода в том, что он значительно усложняет клиентам возможность использования нечестных приёмов (cheating).
Разработка авторитарного сервера требует описания состояния игры и правил взаимодействия игрока с этим состоянием на стороне сервера. В архитектуре сервере magx предполагается, что вся логика реализуется комнате (worker). Каждая комната фактически является отдельным сервером, к которому подключаются клиенты.
Данные/состояние каждой комнаты изолировано и синхронизируется только с клиентам комнаты. Одним из важнейших элементов авторитарного сервера — это система управления состоянием. Mosx — рекомендованная система управления состоянием, но архитектуре magx нет зависимости на какую-либо систему, поэтому выбор всегда остается за вами.
Описание игрового состояния
Так как вся логика игры должна строиться на основе состояния, то первым делом необходимо его описать. С помощью mosx это сделать достаточно просто — необходимо создать классы для каждого типа объектов состояния и обернуть его декоратором @mx.Object, а перед каждым свойством, по которому необходимо отслеживать изменение состояния для синхронизации с клиентами необходимо поставить декоратор @mx. Давайте рассмотрим пример состояния с коллекцией игроков:
@mx.Object
export class Player {
@mx public x = Math.floor(Math.random() * 400)
@mx public y = Math.floor(Math.random() * 400)
}
@mx.Object
export class State {
@mx public players = new Map<string, Player>()
public createPlayer(id: string) {
this.players.set(id, new Player())
}
public removePlayer(id: string) {
this.players.delete(id)
}
public movePlayer(id: string, movement: any) {
const player = this.players.get(id)
if (!player) { return }
player.x += movement.x ? movement.x * 10 : 0
player.y += movement.y ? movement.y * 10 : 0
}
}Единственное ограничение, которое необходимо учесть при проектировании состояния — необходимость использования Map() вместо вложенных объектов. Массивы (Array) и все примитивные типы (number, string, boolean) могут быть использованы без ограничений.
Описание игровой комнаты
После описания состояния и логики его изменения необходимо описать логику взаимодействия с клиентами. Для этого необходимо создать класс комнаты и описать необходимые обработчики событий:
export class MosxStateRoom extends Room<State> {
public createState(): any {
// create state
return new State()
}
public createPatchTracker(state: State) {
// create state change tracker
return Mosx.createTracker(state)
}
public onCreate(params: any) {
console.log("MosxStateRoom created!", params)
}
public onMessage(client: Client, type: string, data: any) {
if (type === "move") {
console.log(`MosxStateRoom received message from ${client.id}`, data)
this.state.movePlayer(client.id, data)
}
}
public onJoin(client: Client, params: any) {
console.log(`Player ${client.id} joined MosxStateRoom`, params)
client.send("hello", "world")
this.state.createPlayer(client.id)
}
public onLeave(client: Client) {
this.state.removePlayer(client.id)
}
public onClose() {
console.log("MosxStateRoom closed!")
}
}Регистрация комнаты на сервере
Последний шаг — зарегистрировать комнату и сервер готов.
const magx = new Server(server, params)
magx.define("mosx-state", MosxStateRoom)Полный исходный код рассмотренного примера доступен в репозитарии magx-examples.
Почему стоит обратить внимание на этот проект?
В заключение хотел бы упомянуть о преимуществах используемых библиотек:
Mosx
- Простой и удобный способ описания состояния через декораторы @mx
- Возможность применять декоратор @mx к вычисляемым свойствам.
- Возможность создавать приватные объекты @mx.Object.private и приватные свойства @mx.private, с различным уровнем доступа для разных игроков.
- Динамически изменять доступ игроков к приватным объектам.
- Встроенный механизм объединения объектов в группы для удобного управления правами доступа к приватным данным
- Возможность делать копию состояния для каждого игрока
- Полная поддержка Typescript
- Минимум зависимостей (на библиотеки MobX и patchpack — для сжатия пакетов)
Magx
- Простой и понятный API.
- Широкие возможности по кастомизации компонент сервера:
- Механизм коммуникации клиента с сервером (по умолчанию используется webockets)
- База данных для хранения данных комнат и сессий пользователей (по умолчанию используется локальное хранилище)
- Механизм коммуникации серверов при масштабировании (из коробки реализован механизм коммуникации в кластере)
- Способ авторизации и верификации пользователей (по умолчанию используются локальный сессии)
- Возможность работать в кластере из коробки
- Встроенные комнаты: лобби и relay (для не авторитарного сервера)
- JS Библиотека Magx-client для работы с сервером
- Мониторинговая консоль magx-monitor для управления комнатами сервера, их клиентами и просмотр состояния
- Полная поддержка Typescript
- Минимум зависимостей (на библиотеку notepack.io — для уменьшения сетевого трафика)
Данный проект достаточно молодой и надеюсь внимание комьюнити поможет ему развиваться на много быстрее.
Рассказывает Алвин Лин, разработчик программного обеспечения из Нью-Йорка
В 2014 году я впервые побывал на CodeDay в Нью-Йорке. И хотя CodeDay не совсем хакатон, это было моё первое знакомство с подобными мероприятиями. Там мы с моим другом Кеннетом Ли написали многопользовательскую игру в танчики. Так как несколько моих друзей спрашивали меня о том, как я её написал, я решил описать процесс её создания.
В этом посте я вкратце опишу ход своих рассуждений и покажу, как воссоздать архитектуру, а также дам некоторые советы, если вы захотите сделать игру сами. Этот пост рассчитан на тех, кто владеет основами JavaScript и Node.js. Если вы с ними не знакомы, то есть много замечательных онлайн-ресурсов, где можно их изучить.
Прим. перев. На нашем сайте есть много познавательных материалов как по JavaScript, так и по Node.js — обязательно найдёте что-нибудь подходящее.
Бэкенд игры написан на Node.js с использованием веб-сокетов, которые позволяют серверу и клиенту общаться в режиме реального времени. Со стороны клиента игра отображается в HTML5-элементе Canvas. Для начала нам, конечно же, понадобится Node.js. В этой статье описана работа с версией 6.3.1, но вы можете использовать любую версию выше 0.12.
Прим. перев. Если вы не знакомы с веб-сокетами, рекомендуем прочитать наш вводный материал.
Создание проекта
Для начала установите зависимости. Создайте папку проекта, перейдите в неё и запустите следующий код:
npm init
npm install --save express socket.ioДля быстрой настройки сервера целесообразно использовать фреймворк Express, а для обработки веб-сокетов на сервере — пакет socket.io. В файл server.js поместите следующий код:
// Зависимости
var express = require('express');
var http = require('http');
var path = require('path');
var socketIO = require('socket.io');
var app = express();
var server = http.Server(app);
var io = socketIO(server);
app.set('port', 5000);
app.use('/static', express.static(__dirname + '/static'));
// Маршруты
app.get('/', function(request, response) {
response.sendFile(path.join(__dirname, 'index.html'));
});
// Запуск сервера
server.listen(5000, function() {
console.log('Запускаю сервер на порте 5000');
});Это довольно типичный код для сервера на связке Node.js + Express. Он устанавливает зависимости и основные маршруты сервера. Для этого демонстрационного приложения используется только один файл index.html и папка static. Создайте их в корневой папке проекта. Файл index.html довольно простой:
<html>
<head>
<title>Наша многопользовательская игра</title>
<style>
canvas {
width: 800px;
height: 600px;
border: 5px solid black;
}
</style>
<script src="/socket.io/socket.io.x16217.js"></script>
</head>
<body>
<canvas id="canvas"></canvas>
</body>
<script src="/static/game.x16217.js"></script>
</html>Ваш пользовательский интерфейс может содержать куда больше элементов, поэтому для более крупных проектов CSS-стили лучше помещать в отдельный файл. Для простоты я оставлю CSS в коде HTML. Обратите внимание, что я включил в код скрипт socket.io.js. Он автоматически заработает в рамках пакета socket.io при запуске сервера.
Теперь нужно настроить веб-сокеты на сервере. В конец файла server.js добавьте:
// Обработчик веб-сокетов
io.on('connection', function(socket) {
});Пока что в игре нет никаких функций, поэтому в обработчик веб-сокетов ничего добавлять не нужно. Для тестирования допишите следующие строки в конец файла server.js:
setInterval(function() {
io.sockets.emit('message', 'hi!');
}, 1000);Эта функция будет отправлять сообщение с именем message и содержимым hi всем подключенным веб-сокетам. Позже не забудьте удалить эту часть кода, так как она предназначена только для тестирования.
В папке static создайте файл с именем game.js. Вы можете написать короткую функцию для регистрации сообщений от сервера, чтобы убедиться в том, что вы их получаете. В файле static/game.js пропишите следующее:
var socket = io();
socket.on('message', function(data) {
console.log(data);
});Запустите сервер командой node server.js и в любом браузере перейдите по ссылке http://localhost:5000. Если вы откроете окно разработчика (нажать правую кнопку мыши → Проверить (Inspect)), то увидите, как каждую секунду приходит новое сообщение:
Как правило, socket.emit(name, data) отправляет сообщение с заданным именем и данными серверу, если запрос идет от клиента, и наоборот, если запрос идет от сервера. Для получения сообщений по конкретному имени используется следующая команда:
socket.on('name', function(data) {
// аргумент data может содержать любые отправляемые данные
});С помощью socket.emit() вы можете отправить любое сообщение. Можно также передавать объекты JSON, что для нас очень удобно. Это позволяет мгновенно передавать информацию в игре от сервера к клиенту и обратно, что является основой многопользовательской игры.
Теперь пусть клиент отправляет некоторые состояния клавиатуры. Поместите следующий код в конец файла static/game.js:
var movement = {
up: false,
down: false,
left: false,
right: false
}
document.addEventListener('keydown', function(event) {
switch (event.keyCode) {
case 65: // A
movement.left = true;
break;
case 87: // W
movement.up = true;
break;
case 68: // D
movement.right = true;
break;
case 83: // S
movement.down = true;
break;
}
});
document.addEventListener('keyup', function(event) {
switch (event.keyCode) {
case 65: // A
movement.left = false;
break;
case 87: // W
movement.up = false;
break;
case 68: // D
movement.right = false;
break;
case 83: // S
movement.down = false;
break;
}
});Это стандартный код, который позволяет отслеживать нажатие клавиш W, A, S, D. После этого добавьте сообщение, которое оповестит сервер о том, что в игре появился новый участник, и создайте цикл, который будет сообщать серверу о нажатии клавиш.
socket.emit('new player');
setInterval(function() {
socket.emit('movement', movement);
}, 1000 / 60);Эта часть кода позволит отправлять на сервер информацию о состоянии клавиатуры клиента 60 раз в секунду. Теперь необходимо прописать эту ситуацию со стороны сервера. В конец файла server.js добавьте следующие строки:
var players = {};
io.on('connection', function(socket) {
socket.on('new player', function() {
players[socket.id] = {
x: 300,
y: 300
};
});
socket.on('movement', function(data) {
var player = players[socket.id] || {};
if (data.left) {
player.x -= 5;
}
if (data.up) {
player.y -= 5;
}
if (data.right) {
player.x += 5;
}
if (data.down) {
player.y += 5;
}
});
});
setInterval(function() {
io.sockets.emit('state', players);
}, 1000 / 60);Давайте разберёмся с этим кодом. Вы будете хранить информацию о всех подключенных пользователях в виде объектов JSON. Так как у каждого подключённого к серверу сокета есть уникальный id, клавиша будет представлять собой id сокета подключённого игрока. Значение же будет другим объектом JSON, содержащим координаты x и y.
Когда сервер получит сообщение о том, что присоединился новый игрок, он добавит новый вход в объект игроков при помощи id сокета, который будет в этом сообщении. Когда сервер получит сообщение о движении, то обновит информацию об игроке, который связан с этим сокетом, если он существует.
io.sockets.emit() — это запрос, который будет отправлять сообщение и данные ВСЕМ подключённым сокетам. Сервер будет отправлять это состояние всем подключённым клиентам 60 раз в секунду.
На данном этапе клиент ещё ничего не делает с этой информацией, поэтому добавьте со стороны клиента обработчик, который будет отображать данные от сервера в Canvas.
var canvas = document.getElementById('canvas');
canvas.width = 800;
canvas.height = 600;
var context = canvas.getContext('2d');
socket.on('state', function(players) {
context.clearRect(0, 0, 800, 600);
context.fillStyle = 'green';
for (var id in players) {
var player = players[id];
context.beginPath();
context.arc(player.x, player.y, 10, 0, 2 * Math.PI);
context.fill();
}
});Этот код обращается к id Canvas (#canvas) и рисует там. Каждый раз, когда от сервера будет поступать сообщение о состоянии, данные в Canvas будут обнуляться, и на нём в виде зеленых кружков будут заново отображаться все игроки.
Теперь каждый новый игрок сможет видеть состояние всех подключенных игроков на Canvas. Запустите сервер командой node server.js и откройте в браузере два окна. При переходе по ссылке http://localhost:5000 вы должны будете увидеть нечто похожее:

Вот и всё! Если у вас возникли проблемы, посмотрите архив с исходным кодом.
Некоторые тонкости
Когда будете разрабатывать более функциональную игру, целесообразно разделить код на несколько файлов.
Такие многопользовательские игры — отличный пример архитектуры MVC (модель-представление-контроллер). Вся логическая часть должна обрабатываться на сервере, а всё, что должен делать клиент — это отправлять входные пользовательские данные на сервер и отображать информацию, которую получает от сервера.
Однако в этом демо-проекте есть несколько недостатков. Обновление игры связано со слушателем сокета. Если бы я хотел повлиять на ход игры, то мог бы написать в консоли браузера следующее:
while (true) {
socket.emit('movement', { left: true });
}Теперь данные о движении будут отправляться на сервер в зависимости от характеристик компьютера более 60 раз в секунду. Это приведёт к тому, что игрок будет передвигаться невероятно быстро. Так мы переходим к концепции определения полномочного сервера.
Ни на каком этапе клиент не должен контролировать какие-либо данные на сервере. Например, никогда не нужно размещать на сервере код, который позволит клиенту определять своё положение/здоровье на основе данных, которые передаются через сокет, так как пользователь сможет легко подделать сообщение, исходящее из сокета, как показано выше.
Когда я создавал свою первую многопользовательскую игру, я написал код так, что игрок мог стрелять тогда, когда отправлялось сообщение о стрельбе, которое со стороны клиента было связано с нажатием кнопки мыши. Умелый игрок мог воспользоваться этим, вставив строчку на JavaScript, очень похожую на ту, что упоминалась выше, чтобы заполучить почти неограниченную скорость стрельбы.
Лучшая аналогия, которую я могу привести, заключается в том, что клиенты должны посылать на сервер только информацию о своих намерениях, которые затем будут обрабатываться и использоваться для изменения состояния игроков, если они валидны.
В идеале циклы обновлений как у клиента, так и на сервере не должны зависеть от сокетов. Попытайтесь сделать так, чтобы обновления игры находились за пределами блока socket.on(). В противном случае вы можете получить много странных нелогичных действий из-за того, что обновление игры будет связано с обновлением сокета.
Кроме того, старайтесь избегать такого кода:
setInterval(function() {
// код ...
player.x += 5;
// код ...
}, 1000 / 60);В этом отрезке кода обновление координаты х для игрока связано с частотой смены кадров в игре. SetInterval() не всегда гарантирует соблюдение интервала, вместо этого напишите нечто подобное:
var lastUpdateTime = (new Date()).getTime();
setInterval(function() {
// код ...
var currentTime = (new Date()).getTime();
var timeDifference = currentTime - lastUpdateTime;
player.x += 5 * timeDifference;
lastUpdateTime = currentTime;
}, 1000 / 60);Это не так изящно, зато обеспечит более плавную и последовательную работу. Усложните демо-проект и попробуйте сделать так, чтобы обновление осуществлялось согласно времени, а не частоте смены кадров. Если не захотите на этом останавливаться, попытайтесь создать на сервере физический движок, который будет управлять движениями игроков.
Также можно сделать так, чтобы из игры удалялись отключенные игроки. Когда сокет отключается, автоматически отправляется сообщение о разъединении. Это можно прописать так:
io.on('connection', function(socket) {
// обработчик событий ...
socket.on('disconnect', function() {
// удаляем отключившегося игрока
});
});Также попытайтесь создать собственный физический движок. Это сложно, но весело. Если захотите попробовать, то рекомендую прочитать книгу «The Nature of Code», в которой есть много полезных идей.
Если хотите посмотреть на гораздо более продвинутый пример, вот игра, которую я сделал, а также исходный код, если вы хотите узнать, как это было написано. На этом всё. Спасибо, что прочитали!
Перевод статьи «How To Build A Multiplayer Browser Game (Part 1)»
И так, здравствуй!
Ты читаешь эту статью потому как решил запустить сервер своей любимой игрушки, но пока не знаешь с чего начать. Постараюсь описать весь процесс в нескольких статьях и как можно доходчевее без использования «научных» терминов, а если что-то и забуду, ты напишешь мне об этом в комментарии и я дополню статью или нет =)
Для начала необходимо определиться с железом на котором сервер будет работать. У каждого игрового сервера свои требования к мощности установленного железа, поэтому рассмотрим какой-нибудь усредненный вариант, который подойдет для большинства игр, а также не стоит забывать, что требования к железу увеличиваются с ростом количества игроков на сервере. Поэтому, чтобы в дальнейшем твои игроки не сталкивались с «лагами», «фризами» и долгими загрузками во время игры, стоит предусмотреть все заранее. Игровой сервер желательно развертывать на отдельной машине, а не на своей основной за которой ты и так играешь и нагружаешь посторонними процессами.
Рекомендуемые характеристики:
 Процессор: Подойдет что-нибудь из ряда 4х и более ядерных вариантов, с частотой работы 3+ GHz. И чтобы случайно не начать «холивар», выбор производителя процессора оставляю за тобой, будь то решение от AMD или Intel.
Процессор: Подойдет что-нибудь из ряда 4х и более ядерных вариантов, с частотой работы 3+ GHz. И чтобы случайно не начать «холивар», выбор производителя процессора оставляю за тобой, будь то решение от AMD или Intel.
 Оперативная память: Чем больше — тем лучше, но начинать стоит не менее чем с 4 Гб, иначе даже самый захудалый «сервачок» «контры» может вести себя не так хорошо как хотелось бы.
Оперативная память: Чем больше — тем лучше, но начинать стоит не менее чем с 4 Гб, иначе даже самый захудалый «сервачок» «контры» может вести себя не так хорошо как хотелось бы.
 Видеокарта: Мощность видеокарты для игровых серверов значения не имеет, потому как серверная часть это исключительно математические расчеты, которые не используют графику, а больше нагружают процессор, поэтому подойдут даже встроенные в материнскую плату варианты видеокарт.
Видеокарта: Мощность видеокарты для игровых серверов значения не имеет, потому как серверная часть это исключительно математические расчеты, которые не используют графику, а больше нагружают процессор, поэтому подойдут даже встроенные в материнскую плату варианты видеокарт.
 Материнская плата: Подойдет любая, которая сможет связать остальные компоненты воедино и заставить их работать.
Материнская плата: Подойдет любая, которая сможет связать остальные компоненты воедино и заставить их работать.
 Блок питания: Стоит выбирать исходя из того, какое железо установлено, но здесь главное не переборщить, потому как серверная машина работает круглосуточно и соответственно потребляет электроэнергию, а она нынче дорогая =) 450 — 500 Вт обычно достаточно.
Блок питания: Стоит выбирать исходя из того, какое железо установлено, но здесь главное не переборщить, потому как серверная машина работает круглосуточно и соответственно потребляет электроэнергию, а она нынче дорогая =) 450 — 500 Вт обычно достаточно.
 Накопитель: В идеале конечно использовать SSD накопитель потому как его скорость работы в разы превышает скорость работы обычного HDD, но для захудалого сервачка контры сойдет и обычный HDD.
Накопитель: В идеале конечно использовать SSD накопитель потому как его скорость работы в разы превышает скорость работы обычного HDD, но для захудалого сервачка контры сойдет и обычный HDD.
 Источник бесперебойного питания: Полезная штука, чтобы защитить сервер и свои нервы от перепадов напряжения.
Источник бесперебойного питания: Полезная штука, чтобы защитить сервер и свои нервы от перепадов напряжения.
Ну вот кажется основные моменты в выборе железа расписал, в следующих статьях рассмотрим выбор и настройку ПО для сервера, и вопросы связанные с выбором Интернет канала и «белого» IP адреса.