Время на прочтение
6 мин
Количество просмотров 51K
Здравствуйте. Меня зовут Андрей, я frontend-разработчик и я хочу поговорить с вами на такую тему как нейросети. Дело в том, что ML технологии все глубже проникают в нашу жизнь, и о нейросетях сказано и написано уже очень много, но когда я захотел разобраться в этом вопросе, я понял что в интернете есть множество гайдов о том как создать нейросеть и выглядят они примерно следующим образом:
-
Берем Tensorflow
-
Создаем нейросеть
Более подробная информация разбросана кусками по всему интернету. Поэтому я постарался собрать ее воедино и изложить в этой статье. Сразу оговорюсь, что я не являюсь специалистом в области ML или биологии, поэтому местами могу быть не точным. В таком случае буду рад вашим комментариям.
Пока я писал эту статью я понял, что у меня получается довольно объемный лонгрид, поэтому решил разбить ее на несколько частей. В первой части мы поговорим о теории, во второй напишем собственную нейросеть с нуля без использования каких-либо библиотек, в третьей попробуем применить ее на практике.
Так как это моя первая публикация, появляться они будут по мере прохождения модерации, после чего я добавлю ссылки на все части. Итак, приступим.
Нейросеть с нуля своими руками. Часть 2. Реализация
Нейросеть с нуля своими руками. Часть 3. Sad Or Happy?
Для чего нужны нейросети
Нейросети встречаются везде. Основная их функция — это управление различными частями организма в зависимости от изменения окружающих условий. В качестве примера можно рассмотреть механизм сужения и расширения зрачка в зависимости от уровня освещения.
В нашем глазу есть сенсоры, которые улавливают количество света попадающего через зрачок на заднюю поверхность глаза. Они преобразуют эту информацию в электрические импульсы и передают на прикрепленные к ним нервные окончания. Далее это сигнал проходит по всей нейронной сети, которая принимает решение о том, не опасно ли такое количество света для глаза, достаточно ли оно для того, чтобы четко распознавать визуальную информацию, и нужно ли, исходя из этих факторов, уменьшить или увеличить количество света.
На выходе этой сети находятся мышцы, отвечающие за расширение или сужение зрачка, и приводят эти механизмы в действие в зависимости от сигнала, полученного из нейросети. И таких механизмов огромное количество в теле любого живого существа, обладающего нервной системой.
Устройство нейрона
Нейросети встречаются в природе в виде нервной системы того или иного существа. В зависимости от выполняемой функции и расположения, они делятся на различные отделы и органы, такие как головной мозг, спинной мозг, различные проводящие структуры. Но все их объединяет одно — они состоят из связанных между собой структурно-функциональных единиц — клеток нейронов.
Нейрон условно можно разделить на три части: тело нейрона, и его отростки — дендриты и аксон.
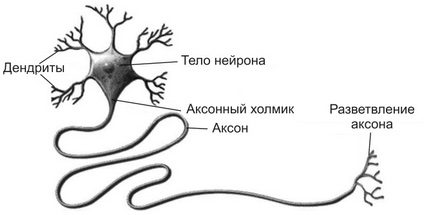
Дендриты нейрона создают дендритное дерево, размер которого зависит от числа контактов с другими нейронами. Это своего рода входные каналы нервной клетки. Именно с их помощью нейрон получает сигналы от других нейронов.
Тело нейрона в природе, достаточно сложная штука, но именно в нем все сигналы, поступившие через дендриты объединяются, обрабатываются, и принимается решение о том передавать ли сигнал далее, и какой силы он должен быть.
Аксон — это выходной интерфейс нейрона. Он крепится так называемыми синапсами к дендриту другого нейрона, и по нему сигнал, выходящий из тела нейрона, поступает к следующей клетке нашей нейросети.
Нейросети в IT
Что же, раз механизм нам понятен, почему бы нам не попробовать воспроизвести его с помощью информационных технологий?
Итак, у нас есть входной слои нейронов, которые, по сути, являются сенсорами нашей системы. Они нужны для того, чтобы получить информацию из окружающей среды и передать ее дальше в нейросеть.
Также у нас есть несколько слоев нейронов, каждый из которых получает информацию от всех нейронов предыдущего слоя, каким-то образом ее обрабатывают, и передают на следующий слой.
И, наконец, у нас есть выходные нейроны. Исходя из сигналов, поступающих от них, мы можем судить о принятом нейросетью решении.

Такой простейший вариант нейронной сети называется перцептрон, и именно его мы с вами и попробуем воссоздать.
Все нейроны по сути одинаковы, и принимают решение о том, какой силы сигнал передать далее с помощью одного и того же алгоритма. Это алгоритм называется активационной функцией. На вход она получает сумму значений входных сигналов, а на выход передает значение выходного сигнала.
Но в таком случае, получается, что все нейроны любого слоя будут получать одинаковый сигнал, и отдавать одинаковое значение. Таким образом мы могли бы заменить всю нашу сеть на один нейрон. Чтобы устранить эту проблему, мы присвоим входу каждого нейрона определенный вес. Этот вес будет обозначать насколько важен для каждого конкретного нейрона сигнал, получаемый от другого нейрона. И тут мы подходим к самому интересному.
Обучение нейронной сети — это процесс подбора входных весов для каждого нейрона таким образом, чтобы на выходе получить сигнал максимально соответствующий ожиданиям.
То есть мы подаем на вход нейросети определенные данные, для которых мы знаем, каким должен быть результат. Далее мы сравниваем результат, который нам выдала нейросеть с ожидаемым результатом, вычисляем ошибку, и корректируем веса нейронов таким образом, чтобы эту ошибку минимизировать. И повторяем это действие большое количество раз для большого количества наборов входных и выходных данных, чтобы сеть поняла какие сигналы на каком нейроне ей важны больше, а какие меньше. Чем больше и разнообразнее будет набор данных для обучения, тем лучше нейросеть сможет обучиться и впоследствии давать правильный результат. Этот процесс называется обучением с учителем.
Добавим немного математики.
В качестве активационной функции нейрона может выступать любая функция, существующая на всем отрезке значений, получающихся на выходе нейрона и входных данных. Для нашего примера мы возьмем сигмоиду. Она существует на отрезке от минус бесконечности до бесконечности, плавно меняется от 0 до 1 и имеет значение 0,5 в точке 0. Идеальный кандидат. Выглядит она следующим образом:
![]()
Таким образом наш нейрон сможет принимать любую сумму значений всех входящих сигналов и на выходе будет выдавать значение от 0 до 1. Это хорошо подходит для принятия бинарных решений, и мы условимся, что если число на выходе нейросети > 0.5, мы будем расценивать его как истину, иначе — как ложь.
Итак, давайте рассмотрим пример с топологией сети рассмотренной выше. У нас есть три входных нейрона со значениями ИСТИНА, ЛОЖЬ и ИСТИНА соответственно, два нейрона в среднем слое нейросети (эти слои также называют скрытыми), и один выходной нейрон, который сообщит нам о решении, принятом нейросетью. Так как наша сеть еще не обучена, поэтому значения весов на входах нейронов мы возьмем случайными в диапазоне от -0,5 до 0,5.
Таким образом сумма входных значений первого нейрона скрытого слоя будет равна
1 * 0,43 + 0 * 0,18 + 1 * -0,21 = 0,22
Передав это значение в активационную функцию, мы получим значение, которое наш нейрон передаст далее по сети в следующий слой.
sigmoid(0,22) = 1 / (1 + e^-0,22) = 0,55
Аналогичные операции произведём для второго нейрона скрытого слоя и получим значение 0,60.
И, наконец, повторим эти операции для единственного нейрона в выходном слое нашей нейросети и получим значение 0,60, что мы условились считать как истину.
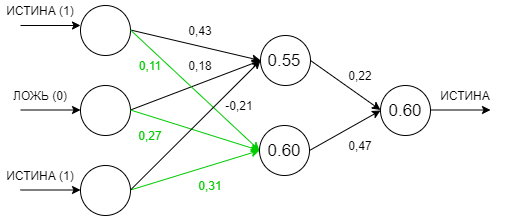
Пока что это абсолютно случайное значение, так как веса мы выбирали случайно. Но, предположим, что мы знаем ожидаемое значение для такого набора входных данных и наша сеть ошиблась. В таком случае нам нужно вычислить ошибку и изменить параметры весов, таким образом немного обучив нашу нейросеть.
Первым делом рассчитаем ошибку на выходе сети. Делается это довольно просто, нам просто нужно получить разницу полученного значения и ожидаемого.
error = 0.60 — 0 = 0.60
Чтобы узнать насколько нам надо изменить веса нашего нейрона, нам нужно величину ошибки умножить на производную от нашей активационной функции в этой точке. К счастью, производная от сигмоиды довольно проста.
![]()
Таким образом наша дельта весов будет равна
delta = 0.60 * (1 — 0.60) = 0.24
Новый вес для входа нейрона рассчитывается по формуле
weight = weight — output * delta * learning rate
Где weight — текущий вес, output — значение на выходе предыдущего нейрона, delta — дельта весов, которую мы рассчитали ранее и learning rate — значение, подбираемое экспериментально, от которого зависит скорость обучения нейросети. Если оно будет слишком маленьким — нейросеть будет более чувствительна к деталям, но будет обучаться слишком медленно и наоборот. Для примера возьмем learning rate равным 0,3. Итак новый вес для первого входа выходного нейрона будет равен:
w = 0,22 — 0,55 * 0,24 * 0,3 = 0,18
Аналогичным образом рассчитаем новый вес для второго входа выходного нейрона:
w = 0.47 — 0.60 * 0.24 * 0.3 = 0.43

Итак, мы скорректировали веса для входов выходного нейрона, но чтобы рассчитать остальные, нам нужно знать ошибку для каждого из нейронов нашей нейросети. Это делается не так очевидно как для выходного нейрона, но тоже довольно просто. Чтобы получить ошибку каждого нейрона нам нужно новый вес нейронной связи умножить на дельту. Таким образом ошибка первого нейрона скрытого слоя равна:
error = 0.18 * 0.24 = 0.04
Теперь, зная ошибку для нейрона, мы можем произвести все те же самые операции, что провели ранее, и скорректировать его веса. Этот процесс называется обратным распространением ошибки.
Итак, мы знаем как работает нейрон, что такое нейронные связи в нейросети и как происходит процесс обучения. Этих знаний достаточно чтобы применить их на практике и написать простейшую нейросеть, чем мы и займемся в следующей части статьи.
Рассказываем, как за несколько шагов создать простую нейронную сеть и научить её узнавать известных предпринимателей на фотографиях.
Шаг 0. Разбираемся, как устроены нейронные сети
Проще всего разобраться с принципами работы нейронных сетей можно на примере Teachable Machine — образовательного проекта Google.
В качестве входящих данных — то, что нужно обработать нейронной сети — в Teachable Machine используется изображение с камеры ноутбука. В качестве выходных данных — то, что должна сделать нейросеть после обработки входящих данных — можно использовать гифку или звук.
Например, можно научить Teachable Machine при поднятой вверх ладони говорить «Hi». При поднятом вверх большом пальце — «Cool», а при удивленном лице с открытым ртом — «Wow».
Для начала нужно обучить нейросеть. Для этого поднимаем ладонь и нажимаем на кнопку «Train Green» — сервис делает несколько десятков снимков, чтобы найти на изображениях закономерность. Набор таких снимков принято называть «датасетом».
Теперь остается выбрать действие, которое нужно вызывать при распознании образа — произнести фразу, показать GIF или проиграть звук. Аналогично обучаем нейронную сеть распознавать удивленное лицо и большой палец.
Как только нейросеть обучена, её можно использовать. Teachable Machine показывает коэффициент «уверенности» — насколько система «уверена», что ей показывают один из навыков.
Шаг 1. Готовим компьютер к работе с нейронной сетью
Теперь сделаем свою нейронную сеть, которая при отправке изображения будет сообщать о том, что изображено на картинке. Сначала научим нейронную сеть распознавать цветы на картинке: ромашку, подсолнух, одуванчик, тюльпан или розу.
Для создания собственной нейронной сети понадобится Python — один из наиболее минималистичных и распространенных языков программирования, и TensorFlow — открытая библиотека Google для создания и тренировки нейронных сетей.
Устанавливаем Python
Если у вас Windows: скачиваем установщик с официального сайта Python и запускаем его. При установке нужно поставить галочку «Add Python to PATH».
На macOS Python можно установить сразу через Terminal:
brew install python
Для работы с нейронной сетью подойдет Python 2.7 или более старшая версия.
Устанавливаем виртуальное окружение
Открываем командную строку на Windows или Terminal на macOS и последовательно вводим несколько команд:
pip install —upgrade virtualenv
virtualenv —system-site-packages Название
source Название/bin/activate
На компьютер будет установлен инструмент для запуска программ в виртуальном окружении. Он позволит устанавливать и запускать все библиотеки и приложения внутри одной папки — в команде она обозначена как «Название».
Устанавливаем TensorFlow
Вводим команду:
pip install tensorflow
Всё, библиотека TensorFlow установлена в выбранную папку. На macOS она находится по адресу Macintosh HD/Users/Имя_пользователя/, на Windows — в корне C://.
Можно проверить работоспособность библиотеки последовательно вводя команды:
python
import tensorflow as tf
hello = tf.constant(‘Hello, TensorFlow’)
sess = tf.Session()
print(sess.run(hello))
Если установка прошла успешно, то на экране появится фраза «Hello, Tensorflow».
Шаг 2. Добавляем классификатор
Классификатор — это инструмент, который позволяет методам машинного обучения понимать, к чему относится неизвестный объект. Например, классификатор поможет понять, где на картинке растение, и что это за цветок.
Открываем страницу «Tensorflow for poets» на Github, нажимаем на кнопку «Clone or download» и скачиваем классификатор в формате ZIP-файла.
Затем распаковываем архив в созданную на втором шаге папку.
Шаг 3. Добавляем набор данных
Набор данных нужен для обучения нейронной сети. Это входные данные, на основе которых нейронная сеть научится понимать, какой цветок расположен на картинке.
Сначала скачиваем набор данных (датасет) Google с цветами. В нашем примере — это набор небольших фотографий, отсортированный по папкам с их названиями.
Содержимое архива нужно распаковать в папку /tf_files классификатора.
Шаг 4. Переобучаем модель
Теперь нужно запустить обучение нейронной сети, чтобы она проанализировала картинки из датасета и поняла при помощи классификатора, как и какой тип цветка выглядит.
Переходим в папку с классификатором
Открываем командную строку и вводим команду, чтобы перейти в папку с классификатором.
Windows:
cd C://Название/
macOS:
cd Название
Запускаем процесс обучения
python scripts/retrain.py —output_graph=tf_files/retrained_graph.pb —output_labels=tf_files/retrained_labels.txt —image_dir=tf_files/flower_photos
Что указано в команде:
- retrain.py — название Python-скрипта, который отвечает за запуск процесса обучения нейронной сети.
- output_graph — создаёт новый файл с графом данных. Он и будет использоваться для определения того, что находится на картинке.
- output_labels — создание нового файла с метками. В нашем примере это ромашки, подсолнухи, одуванчики, тюльпаны или розы.
- image_dir — путь к папке, в которой находятся изображения с цветами.
Программа начнет создавать текстовые файлы bottleneck — это специальные текстовые файлы с компактной информацией об изображении. Они помогают классификатору быстрее определять подходящую картинку.
Весь ход обучения занимает около 4000 шагов. Время работы может занять несколько десятков минут — в зависимости от мощности процессора.
После завершения анализа нейросеть сможет распознавать на любой картинке ромашки, подсолнухи, одуванчики, тюльпаны и розы.
Перед тестированием нейросети нужно открыть файл label_image.py, находящийся в папке scripts в любом текстовом редакторе и заменить значения в строках:
input_height = 299
input_width = 299
input_mean = 0
input_std = 255
input_layer = «Mul»
Шаг 5. Тестирование
Выберите любое изображение цветка, которое нужно проанализировать, и поместите его в папку с нейронной сетью. Назовите файл image.jpg.
Для запуска анализа нужно ввести команду:
python scripts/label_image.py —image image.jpg
Нейросеть проверит картинку на соответствие одному из лейблов и выдаст результат.
Например:
Это значит, что с вероятностью 72% на картинке изображена роза.
Шаг 6. Учим нейронную сеть распознавать предпринимателей
Теперь можно расширить возможности нейронной сети — научить её распознавать на картинке не только цветы, но и известных предпринимателей. Например, Элона Маска и Марка Цукерберга.
Для этого нужно добавить новые изображения в датасет и переобучить нейросеть.
Собираем собственный датасет
Для создания датасета с фотографиями предпринимателей можно воспользоваться поиском по картинкам Google и расширением для Chrome, которое сохраняет все картинки на странице.
Папку с изображениями Элона Маска нужно поместить в tf_filesflower_photosmusk. Аналогично все изображения с основателем Facebook — в папку tf_filesflower_photoszuckerberg.
Чем больше фотографий будет в папках, тем точнее нейронная сеть распознает на ней предпринимателя.
Переобучаем и проверяем
Для переобучения и запуска нейронной сети используем те же команды, что и в шагах 4 и 5.
python scripts/retrain.py —output_graph=tf_files/retrained_graph.pb —output_labels=tf_files/retrained_labels.txt —image_dir=tf_files/flower_photos
python scripts/label_image.py —image image.jpg
Шаг 7. «Разгоняем» нейронную сеть
Чтобы процесс обучения не занимал каждый раз много времени, нейросеть лучше всего запускать на сервере с GPU — он спроектирован специально для таких задач.
Процесс запуска и обучения нейронной сети на сервере похож на аналогичный процесс на компьютере.
Создание сервера с Ubuntu
Нам понадобится сервер с операционной системой Ubuntu. Её можно установить самостоятельно, либо — если арендован сервер Selectel — через техподдержку компании.
Установка Python
sudo apt-get install python3-pip python3-dev
Установка TensorFlow
pip3 install tensorflow-gpu
Скачиваем классификатор и набор данных
Аналогично шагам 2 и 3 на компьютере, только архивы необходимо загрузить сразу на сервер.
Переобучаем модель
python3 scripts/retrain.py —output_graph=tf_files/retrained_graph.pb —output_labels=tf_files/retrained_labels.txt —image_dir=tf_files/flower_photos
Тестируем нейросеть
python scripts/label_image.py —image image.jpg
В этой статье поговорим о том, как создавать нейросети и в качестве примера рассмотрим, как сделать нейронную сеть прямого распространения с нуля. Для реализации поставленной задачи воспользуемся языком программирования C#.
Только ленивый не слышал сегодня о существовании и разработке нейронных сетей и такой сфере, как машинное обучение. Для некоторых создание нейросети кажется чем-то очень запутанным, однако на самом деле они создаются не так уж и сложно. Как же их делают? Давайте попробуем самостоятельно создать нейросеть прямого распространения, которую еще называют многослойным перцептроном. В процессе работы будем использовать лишь циклы, массивы и условные операторы. Что означает этот набор данных? Только то, что нам подойдет любой язык программирования, поддерживающий вышеперечисленные возможности. Если же у языка есть библиотеки для векторных и матричных вычислений (вспоминаем NumPy в Python), то реализация с их помощью займет совсем немного времени. Но мы не ищем легких путей и воспользуемся C#, причем полученный код по своей сути будет почти аналогичным и для прочих языков программирования.
Что же такое нейронная сеть?
Под искусственной нейронной сетью (ИНС) понимают математическую модель (включая ее программное либо аппаратное воплощение), которая построена и работает по принципу функционирования биологических нейросетей — речь идет о нейронных сетях нервных клеток живых организмов.
Говоря проще, ИНС можно назвать неким «черным ящиком», превращающим входные данные в выходные данные. Если же посмотреть на это с точки зрения математики, то речь идет о том, чтобы отобразить пространство входных X-признаков в пространство выходных Y-признаков: X → Y. Таким образом, нам надо найти некую F-функцию, которая сможет выполнить данное преобразование. На первом этапе этой информации достаточно в качестве основы.
Какую роль играет искусственный нейрон?
В нашей статье мы не будем вдаваться в лирику и рассказывать об устройстве биологического нейрона в контексте его связи с искусственной моделью. Лучше сразу перейдем к делу.
Искусственный нейрон представляет собой взвешенную сумму векторных значений входных элементов. Эта сумма передается на нелинейную функцию активации f:

Но об активации поговорим после, т. к. сейчас стоит задача узнать, каким образом вместо одного выходного значения можно получить n-значений.
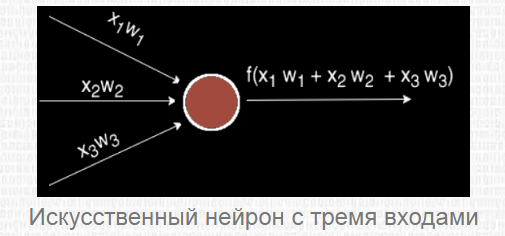
Нейрослой
Один нейрон может превратить в одну точку входной вектор, но по условию мы желаем получить несколько точек, т. к. выходное Y способно иметь произвольную размерность, которая определяется лишь ситуацией (один выход для XOR, десять выходов, чтобы определить принадлежность к одному из десяти классов, и так далее). Каким же образом получить n точек? На деле все просто: для получения n выходных значений, надо задействовать не один нейрон, а n. В результате для каждого элемента выходного Y будет использовано n разных взвешенных сумм от X. В итоге мы придем к следующему соотношению:
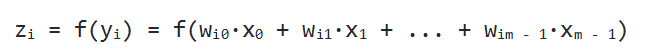
Давайте внимательно посмотрим на него. Вышенаписанная формула — это не что иное, как определение умножения матрицы на вектор. И в самом деле, если мы возьмем матрицу W размера n на m и выполним ее умножение на X размерности m, то мы получим другое векторное значение n-размерности, то есть как раз то, что надо.
Таким образом, мы можем записать похожее выражение в более удобной матричной форме:

Но полученный вектор представляет собой неактивированное состояние (промежуточное, невыходное) всех нейронов, а для того, чтобы нам получить выходное значение, нужно каждое неактивированное значение подать на вход вышеупомянутой функции активации. Итогом ее применения и станет выходное значение слоя.
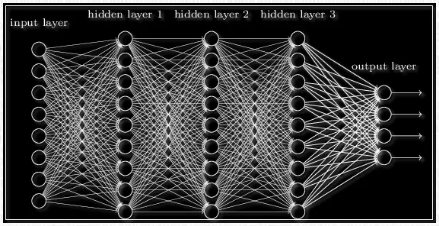
Ниже показан пример нейронной сети, имеющей 2 входа, 5 нейронов и 1 выход:

Последовательность нейрослоев часто применяют для более глубокого обучения нейронной сети и большей формализации имеющихся данных. Именно поэтому, чтобы получить итоговый выходной вектор, нужно проделать вышеописанную операцию пару раз подряд по направлению от одного слоя к другому. В результате для 1-го слоя входным вектором будет являться X, а для последующих входом будет выход предыдущего слоя. То есть нейронная сеть может выглядеть следующим образом:
Функция активации
Речь идет о функции, добавляющей в нейронную сеть нелинейность. В результате нейроны смогут относительно точно сымитировать любую функцию. Широко распространены следующие функции активации:

Каждая из них имеет свои особенности.
Пишем код
Теперь мы знаем достаточно, чтобы создать простую нейронную сеть. Чтобы сделать то, что задумали, нам потребуются:
- Вектор.
- Матрица (каждый слой включает в себя матрицу весовых коэффициентов).
- Нейронная сеть.
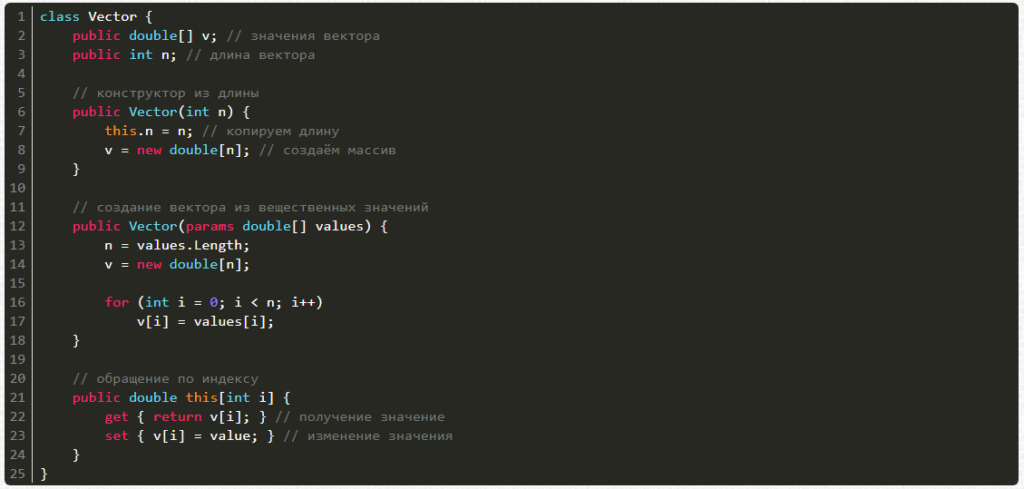
Начнем с вектора. Создавать его можно:
- из количества элементов;
- из перечисления вещественных чисел.
Также мы можем получать и менять значения по индексу i.
Пишем код:
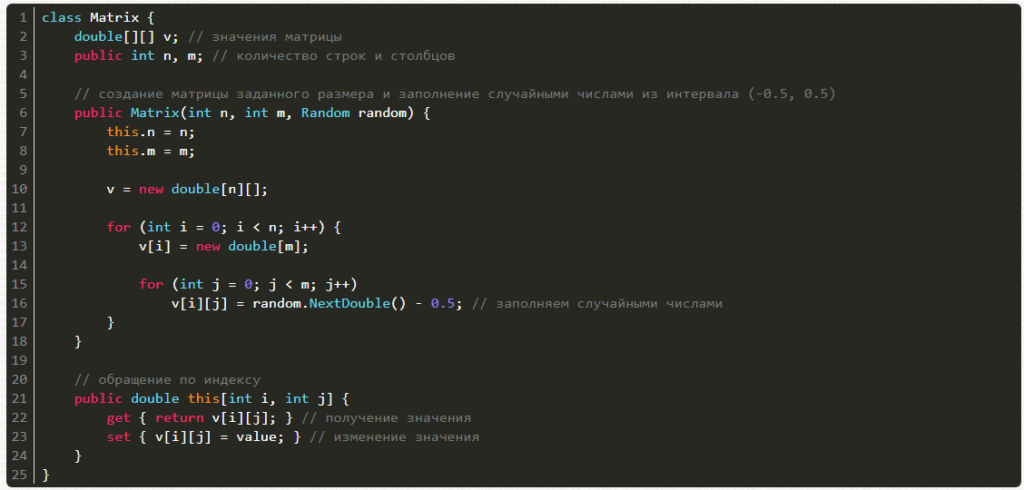
Теперь очередь матрицы. Ее можно создавать из числа строк и столбцов, а также генератора случайных чисел, причем есть возможность получать и менять значения по индексам i и j.
А вот и сама нейронная сеть:
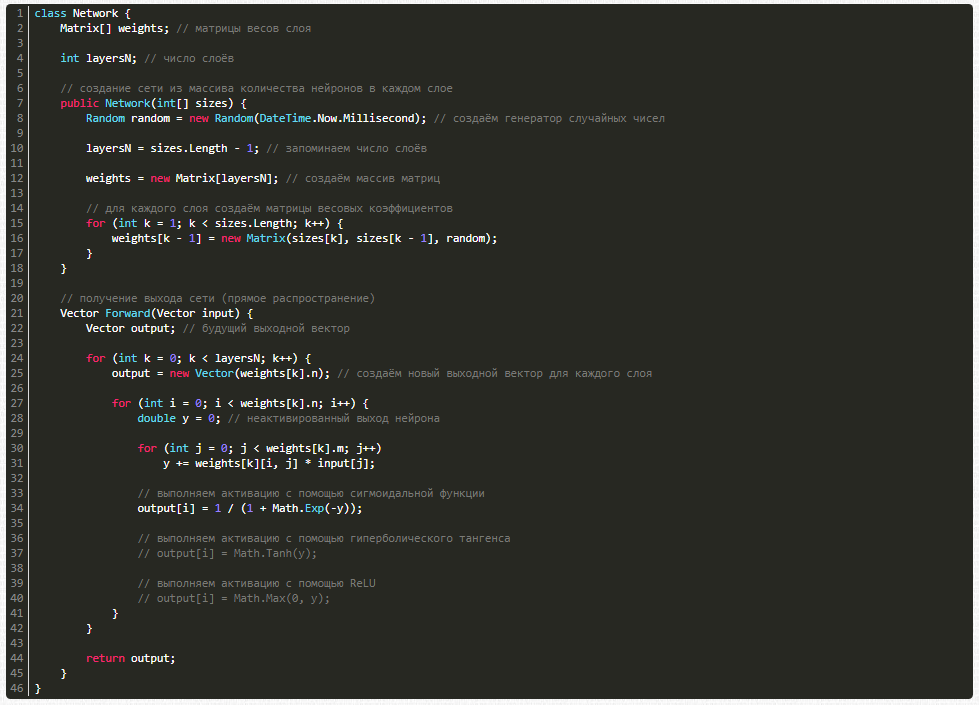
Как будем обучать?
Пусть у нас уже есть нейронная сеть, но ведь ее ответы являются случайными, то есть наша нейросеть не обучена. Сейчас она способна лишь по входному вектору input выдавать случайный ответ, но нам нужны ответы, которые удовлетворяют конкретной поставленной задаче. Дабы этого достичь, сеть надо обучить. Здесь потребуется база тренировочных примеров и множество пар X — Y, на которых и будет происходить обучение, причем с использованием известного алгоритма обратного распространения ошибки.
Некоторые особенности работы этого алгоритма:
- на вход сети подается обучающий пример (1 входной вектор);
- сигнал распространяется по нейросети вперед (получаем выход сети);
- вычисляется ошибка (это разница между получившимся и ожидаемым векторами);
- ошибка распространяется на предыдущие слои;
- происходит обновление весовых коэффициентов в целях уменьшения ошибки.
Вот как выглядит алгоритм обучения:

Переходим к обучению
Для обратного распространения ошибки нужно знать значения выходов и входов, а также значения производных функции активации нейросети, причем послойно, следовательно, нужно создать структуру LayerT, где будут три векторных значения:
- x — вход слоя,
- z — выход,
- df — производная функции активации.
Для каждого слоя нам потребуются векторы дельт, в результате чего надо будет добавить в класс еще и их. В итоге класс будет выглядеть следующим образом:
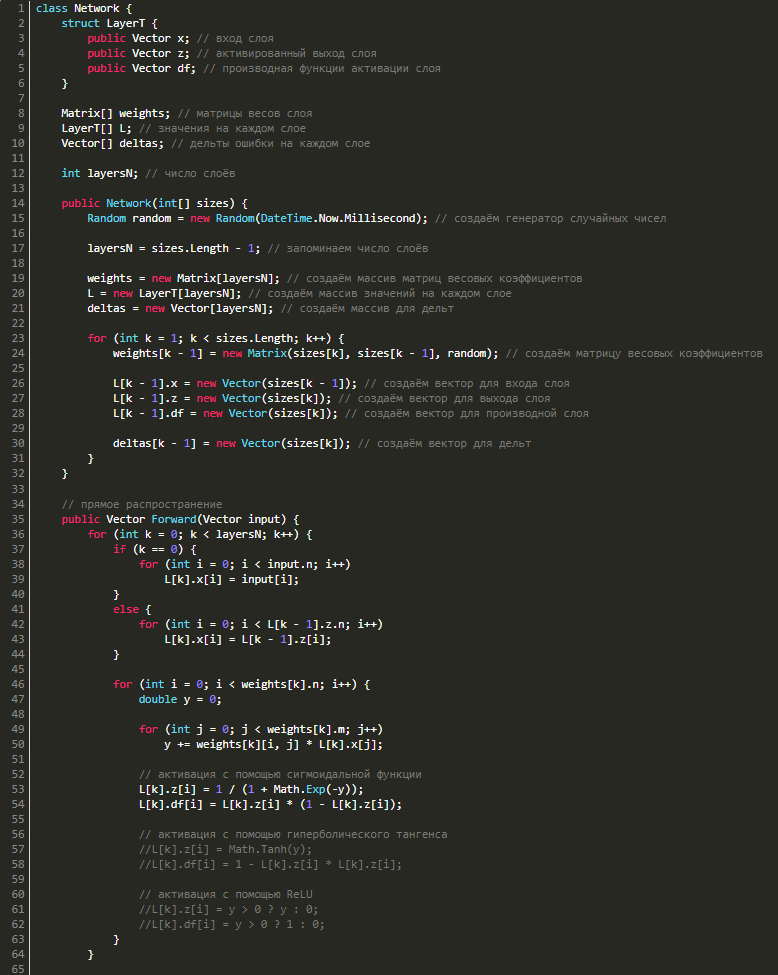
Несколько слов об обратном распространении ошибки
В качестве функции оценки нейросети E(W) мы берем среднее квадратичное отклонение:
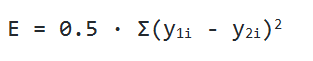
Дабы найти значение ошибки E, надо найти сумму квадратов разности векторных значений, которые были выданы нейронной сетью в виде ответа, а также вектора, который ожидается увидеть при обучении. Еще надо будет найти дельту каждого слоя и учесть, что для последнего слоя дельта будет равняться векторной разности фактического и ожидаемого результатов, покомпонентно умноженной на векторное значение производных последнего слоя:

Когда мы узнаем дельту последнего слоя, мы сможем найти дельты и всех предыдущих слоев. Чтобы это сделать, нужно будет лишь перемножить для текущего слоя транспонированную матрицу с дельтой, а потом перемножить результат с вектором производных функции активации предыдущего слоя:
![]()
Смотрим реализацию в коде:
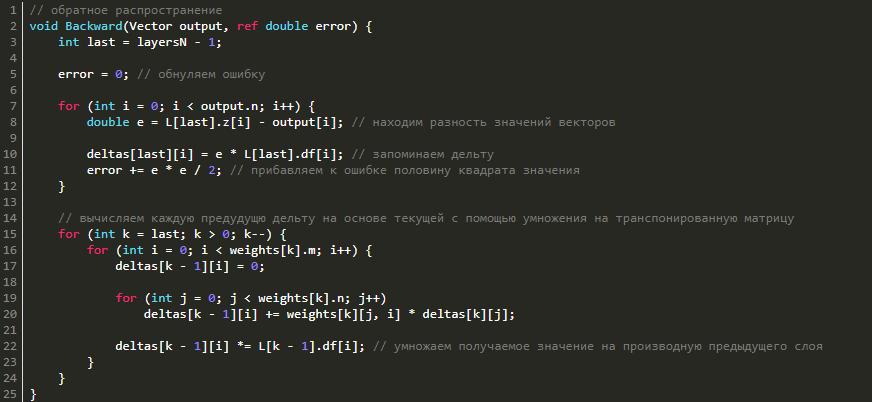
Обновление весовых коэффициентов
Для уменьшения ошибки нейронной сети надо поменять весовые коэффициенты, причем послойно. Каким же образом это осуществить? Ничего сложного в этом нет: надо воспользоваться методом градиентного спуска. То есть нам надо рассчитать градиент по весам и сделать шаг от полученного градиента в отрицательную сторону. Давайте вспомним, что на этапе прямого распространения мы запоминали входные сигналы, а во время обратного распространения ошибки вычисляли дельты, причем послойно. Как раз ими и надо воспользоваться в целях нахождения градиента. Градиент по весам будет равняться не по компонентному перемножению дельт и входного вектора. Дабы обновить весовые коэффициенты, снизив таким образом ошибку нейросети, нужно просто вычесть из матрицы весов итог перемножения входных векторов и дельт, помноженный на скорость обучения. Все вышеперечисленное можно записать в следующем виде:

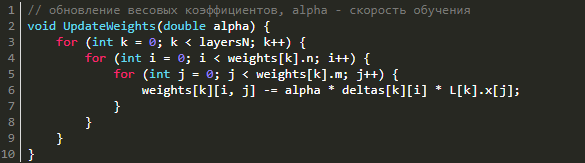
Вот оно, обучение!
Теперь мы имеем все нужные нам методы, поэтому остается лишь всё это вместе соединить, сформировав единый метод обучения.
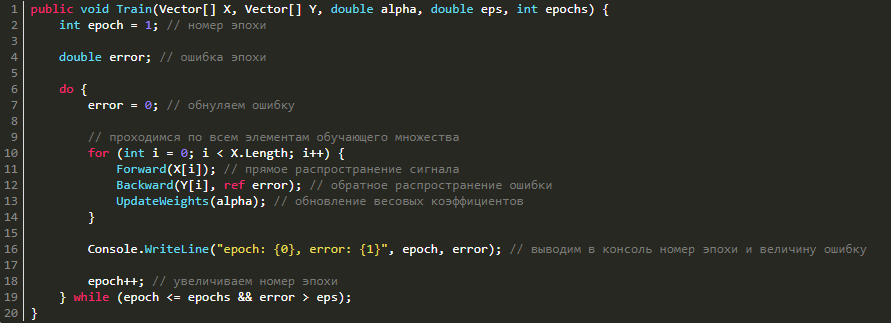
Наша сеть готова, но мы пока ее еще ничему не научили. Сейчас это исправим.
Тренировка нейронной сети. Функции XOR
Функция XOR интересна тем, что ее нельзя получить одним нейроном:
![]()
Но ее легко получить путем увеличения количества нейронов. Давайте попробуем реализовать обучение с тремя нейронами в скрытом слое и одним выходным (выход ведь у нас только один). Чтобы все получилось, создадим массив X и Y, имеющий обучающие данные и саму нейронную сеть:
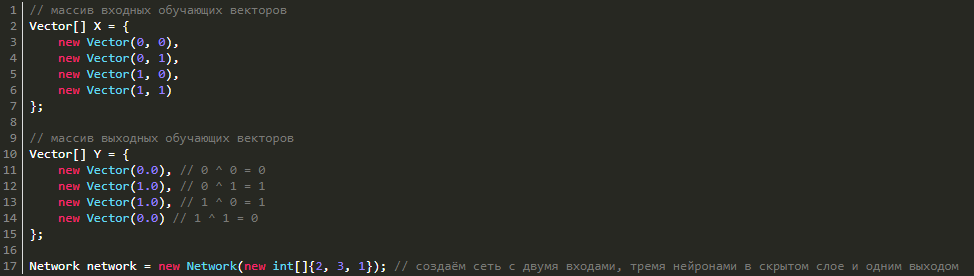
Теперь запускаем обучение с параметрами ниже:
- скорость обучения — 0.5,
- количество эпох — 100000,
- значение ошибки — 1e-7.
![]()
Выполнив обучение, посмотрим итоги, для чего надо будет сделать прямой проход для всех элементов:

В итоге вывод будет следующим:

Результаты
Мы написали нейронную сеть прямого распространения и не только написали, но и обучили ее функции XOR. Также была обеспечена универсальность, поэтому эту нейросеть можно обучать на любых данных — потребуется лишь:
- подготовить 2 векторных обучающих массива векторов X и Y,
- подобрать параметры,
- запустить само обучение,
- наблюдать за процессом.
Однако помните, что если используется сигмоидальная функция активации, выходные числа не будут больше единицы, что означает, что для обучения данным, которые существенно больше единицы, нужно будет нормировать их, приводя к отрезку [0, 1].
Надеемся, что материал был вам полезен и теперь вы знаете, как сделать нейросеть, и какие нюансы разработки стоит учитывать. Если же интересуют более продвинутые знания, обратите внимание на курсы, которые разработала команда Otus:

По материалам: https://programforyou.ru/poleznoe/pishem-neuroset-pryamogo-rasprostraneniya.
2. Регрессия
Следующий тип задач — это регрессия.
Суть этой задачи — получить на выходе из нейронной сети не класс, а конкретное число, например:
— Определение возраста по фото
— Прогнозирование курса акций
— Оценка стоимости недвижимости
Например, у нас есть данные об объекте недвижимости, такие как: метраж, количество комнат, тип ремонта, развитость инфраструктуры в окрестностях этого объекта, удаленность от метро и т.д.
И нашей задачей является предсказать цену на этот объект, исходя из имеющихся данных. Задачи такого плана — это задачи регрессии, т.к. на выходе мы ожидаем получить стоимость — конкретное число.
3. Прогнозирование временных рядов
Прогнозирование временных рядов — это задача, во многом схожая с регрессией.
Суть её заключается в том, что у нас есть динамический временной ряд значений, и нам нужно понять, какие значения будут идти в нем дальше.
Например, это задачи по предсказанию:
— Курсов акций, нефти, золота, биткойна
— Изменению процессов в котлах (давление, концентрация тех или иных веществ и т.д.)
— Количества трафика на сайте
— Объемов потребления электроэнергии и т.д.
Даже автопилот Tesla отчасти тоже можно отнести к задаче этого типа, ведь видеоряд следует рассматривать как временной ряд из картинок.
Возвращаясь же к примеру с оценкой процессов, происходящих в котлах, задача, по сути, является двойной.
С одной стороны, мы предсказываем временной ряд давления и концентрации тех или иных веществ, а с другой — распознаем по этому временному ряду паттерны, чтобы оценить, критичная ситуация, или нет. И здесь уже идет распознавание образов.
Именно поэтому мы сразу отметили тот факт, что не всегда есть четкая граница между разными типами задач.
4. Кластеризация
Кластеризация — это обучение, когда нет учителя.
В этой ситуации у нас есть много данных и неизвестно, какие из них к какому классу относятся, при этом есть предположение, что там есть некоторое количество классов.
Например, это:
— Выявление классов читателей при email-рассылках
— Выявление классов изображений
Типичная маркетинговая задача — эффективно вести email-рассылку. Допустим, у нас есть миллион email-адресов, и мы ведем некую рассылку.
Разумеется, люди ведут себя совершенно по-разному: кто-то открывает почти все письма, кто-то не открывает почти ничего.
Кто-то постоянно кликает по ссылкам в письмах, а кто-то просто их читает и кликает крайне редко.
Кто-то открывает письма по вечерам в выходные, а кто-то — утром в будние, и так далее.
Задача кластеризации в этом случае — это анализ всего объема данных и выделение нескольких классов подписчиков, обладающих сходными поведенческими паттернами (в рамках, каждого класса, разумеется).
Другая задача этого типа — это, например, выявление классов для изображений. Один из проектов в нашей Лаборатории — это работа с фентези-картинками.
Если передать эти изображения нейронной сети, то, после их анализа, она, к примеру «скажет» нам, что обнаружила 17 различных классов.
Допустим, один класс — это изображение с замками. Другой — это картинки с изображением человека по центру. Третий класс — это когда на картинке дракон, четвертый — это много персонажей на фоне природного ландшафта, происходит какая-нибудь битва, и т.д.
Это примеры типичных задач кластеризации.
5. Генерация
Генеративные сети (GAN) — это самый новый, недавно появившийся тип сетей, который стремительно развивается.
Если говорить кратко, то их задача – машинное творчество. Под машинным творчеством подразумевается генерация любого контента:
— Текстов (стихи, тексты песен, рассказы)
— Изображений (в том числе фотореалистичных)
— Аудио (генерация голоса, музыкальных произведений) и т.д.
Кроме того, в этот список можно добавить и задачи трансформации контента:
— раскрашивание черно-белых фильмов в цветные
— изменение сезона в видеоролике (например, трансформация окружающей среды из зимы в лето) и др.
В случае с «переделкой» сезона изменения затрагивают все важные аспекты. Например, есть видео с регистратора, в котором машина зимой едет по улицам города, вокруг лежит снег, деревья стоят голые, люди в шапках и т.д.
Параллельно с этим роликом идет другой, переделанный в лето. Там уже вместо снега зеленые газоны, деревья с листвой, люди легко одеты и т.д.
Безусловно, есть и некоторые другие типы задач, которые решают нейронные сети, но все основные мы с вами рассмотрели.
1. Самообучение
Косвенно мы уже касались этой момента выше, поэтом сейчас раскроем его чуть больше.
Суть самообучения заключается в том, что мы задаем общий алгоритм, как она будет обучаться, а дальше она сама «понимает», как некое явление или процесс устроены изнутри.
Суть самообучения заключается в том, что нейронной сети для успешной работы нужно дать правильные, подготовленные данные и прописать алгоритм, по которому она будет обучаться.
В качестве иллюстрации для этой особенности можно привести генетический алгоритм, суть которого мы рассмотрим на примере программы с летающими по экрану монитора смайликами.
Одновременно перемещалось 50 смайликов, и они могли замедляться / ускоряться и менять направление своего движения.
В алгоритме мы заложили, что если они вылетают за край экрана или попадают под клик мыши, то «умирают».
После «смерти» тут же создавался новый смайлик, причем на основании того, кто «прожил» дольше всего.
Это была вероятностная функция, которая отдавала приоритет «рождения» новых смайликов тем, кто прожил дольше всех и минимизировала вероятность появления «потомства» у тех, кто быстро улетел за пределы экрана или попался под клик мыши.
Сразу после запуска программы все смайлики начинают летать хаотично и быстро «умирают», улетая за края экрана.
Проходит буквально 1 минута, и они научаются не «умирать», улетая за правый край экрана, но улетают вниз. Еще через минуту они перестают улетать вниз. Через 5 минут они уже вообще не умирают.
Смайлики разбились на несколько групп: кто-то летал вдоль периметра экрана, кто-то топтался в центре, кто-то нарезал восьмерки, и т.д. При этом мышкой мы их еще не кликали.
Теперь мы начали кликать по ним мышкой и, естественно, они тут же умирали, потом что еще не обучались избегать курсора.
Через 5 минут было невозможно поймать ни одного из них. Как только к ним приближался курсор, смайлики делали какой-нибудь кульбит и уходили от клика — поймать их было невозможно.
Самое важное и восхитительное во всем это то, что мы не закладывали в них алгоритм, как не улетать за края экрана и уворачиваться от мышки. И если первый момент реализовать несложно, то со вторым все на порядок сложнее.
Можно было бы потратить примерно неделю времени и создать нечто подобное, но прелесть в том, что мы добились такого же или даже лучшего результата, потратив на программирование пару часов и еще несколько минут на то, чтобы произошло обучение.
Вдобавок к этому, поменяв пару строчек кода, мы могли бы довнести в их алгоритм обучения любую другую функцию. Например, если это происходит на фоне рабочего стола — не залезать на иконки, которые на нем есть.
Или мы хотим, чтобы они не сталкивались друг с другом. Или мы хотим поделить их на 2 группы, раскрашенных в разные цвета и хотим, чтобы они не сталкивались со смайликами другого цвета. И так далее.
И они обучились бы этому за те же самые 5-10 минут по тем же принципам генетических алгоритмов.
Надеюсь, что этот пример показал вам потрясающую силу всего, что связано с искусственным интеллектом и нейронными сетями.
При всем при этом важно иметь компетенцию писать такие генетические алгоритмы и уметь подавать такой сети правильные входные данные.
Так, в рассмотренном выше примере сначала никак не удавалось добиться сколь-нибудь значимого прогресса в обучении смайликов по той причине, что в качестве входных данных им подавалось расстояние до краев экрана и расстояние до курсора мыши.
В результате этого нейронной сети не хватало мощности обучиться на таком типе данных, и прогресса практически не было.
После этого в качестве входных параметров стали передаваться другие значения — единица, деленная на расстояние до края экрана и единица, деленная на расстояние до курсора.
Результат — прекрасное обучение, о котором мы только что говорили. Почему? Потому что когда они подлетали к краю экрана, этот параметр начинал зашкаливать, его изменение происходило очень быстро, и в этой комбинации нейронная сеть смогла выявить важную закономерность и обучиться.
На этом с самообучением всё, двигаемся дальше.
2. Требуется обучающая выборка
Нейронным сетям для обучения требуется обучающая выборка. Это главный минус, т.к. обычно нужно собрать много данных.
К примеру, если мы пишем распознавание лиц в классическом машинном обучении, то нам не нужна база из фотографий – достаточно нескольких фото, по которым человек сам составит алгоритм определения лица, или даже сделает это по памяти, вообще без фото.
В случае с нейронными сетями ситуация иная – нужна большая база того, на чем мы хотим обучить нейронную сеть. При этом важно не только собрать базу, но и определенным образом её предобработать.
Поэтому очень часто сбор базы производится в том числе фрилансерами или крупными бизнесами (классический пример — сбор данных компанией Google для того, чтобы показывать нам капчи).
На своем курсе мы делаем на это упор — в том числе в Лабораториях и во время подготовки дипломных работ. Важно научиться собирать эти данные руками, получив ценный опыт, поняв, как это делается правильно, и на что нужно обратить внимание.
Если вы освоите это сами, то в будущем сможете писать в том числе и правильные ТЗ для подрядчиков, получая качественные, нужные вам результаты.
3. Не требуется понимания явления человеком
Третий пункт — это огромный плюс нейронных сетей.
Можно не быть экспертом в какой-либо предметной области, но, будучи экспертом в нейронных сетях решить практически любую задачу.
Да, экспертность, безусловно влияет в плюс, т.к. мы можем лучше предобработать данные и, возможно, быстрее решить задачу, но в целом это не является критическим фактором.
Если в классическом машинном обучении не являясь экспертом в предметной области (например, атомная энергетика, машиностроение, геологические процессы и т.п.) мы вообще не сможем решить задачу, то здесь это вполне реально.
4. Значительно точнее в большинстве задач
Следующее значимое преимущество нейронных сетей — их высокая точность.
Например, аварийность автопилотов Tesla на пробег в 1 млн. км. примерно в 10 раз ниже, чем аварийность обычного водителя.
Точность предсказания медицинских диагнозов по МРТ также выше, чем у специалистов-врачей.
Нейронные сети обыгрывают людей практически в любые игры: шахматы, покер, го, компьютерные игры и т.д.
Одним словом, их точность значительно выше практически во всех задачах, что и привело к их все более и более активному использованию в самых разных сферах жизни человека, начиная с маркетинга и финансов, и заканчивая медициной, промышленностью и искусством.
5. Непонятно, как работают внутри
Однако, при всех этих возможностях у нейронных сетей есть следующий минус — непонятно, как они работают «внутри».
Мы не можем туда влезть и понять, как там все устроено, как она «мыслит». Это все скрыто в весах, в цифрах.
Более или менее «увидеть» то, что происходит внутри возможно, разве что, в сверточных сетях при работе с изображениями, но даже это не позволяет нам получить полной картины.
Типичный пример того, что нейронная сеть в чем-то похожа на черный ящик — это ситуации, когда, например идет судебный процесс, в ходе которого какие-нибудь компании обращаются в Яндекс и спрашивают, почему именно этот сайт, а не какой-то другой выводится именно на этот позиции в выдаче.
И Яндекс не может ответить на подобные вопросы, т.к. это решение принимается нейронной сетью, а не чётко прописанным алгоритмом, который можно полностью объяснить.
Ответить на такой вопрос — задача столь же нетривиальная, как, например, предсказать точную траекторию, по которой именно с этого стола скатится именно этот металлический шарик, положенный именно в это конкретное место.
Да, законы гравитации нам известны, однако предсказать в точности, как именно будет происходить его движение, практически невозможно.
То же самое с нейронной сетью. Принципы её работы ясны, однако понять, как она сработает в каждом конкретном случае не представляется возможным.
Строение биологического нейрона
Для того, чтобы понять, как устроен искусственный нейрон, начнем с того, что вспомним, как функционирует обычная нервная клетка.
Именно её строение и функционирование Уоррен Мак-Каллок (американский нейропсихолог, нейрофизиолог, теоретик искусственных нейронных сетей и один из основателей кибернетики) и Уолтер Питтс (американский нейролингвист, логик и математик) взяли как основу для модели искусственного нейрона еще в середине прошлого века.
Итак, как выглядит нейрон?
У нейрона есть тело, которое накапливает и некоторым образом преобразует сигнал, приходящий к нему через дендриты – короткие отростки, функция которых заключается в приеме сигналов от других нервных клеток.
Накопив сигнал, нейрон передает его по цепочке дальше, другим нейронам, но уже по длинному отростку – аксону, который, в свою очередь, связан с дендритами других нейронов, и так далее.
Конечно, это крайне примитивная модель, т.к. каждый нейрон в нашем мозге может быть связан с тысячами других нейронов.
Следующий момент, на который нам нужно обратить внимание — это то, каким образом сигнал передается от аксона к дендритам следующего нейрона.
Дендриты с аксонами связаны не напрямую, а через так называемые синапсы, и когда сигнал доходит до конца аксона, в синапсе происходит выброс нейромедиатора, определяющего, как именно сигнал будет передан дальше.
Нейромедиаторы — биологически активные химические вещества, посредством которых осуществляется передача электрохимического импульса от нервной клетки через синаптическое пространство между нейронами, а также, например, от нейронов к мышечной ткани или железистым клеткам.
Иными словами, нейромедиатор является неким мостиком между аксоном и множеством дендритов принимающей сигнал клетки.
Если нейромедиатора выбросится много, то сигнал передастся полностью или даже будет усилен. Если же его выбросится мало, то сигнал будет ослаблен, либо вовсе погашен и не передастся другим нейронам.
Таким образом, процесс формирования устойчивых нейронных дорожек (уникальных цепочек связей между нейронами), являющихся биологической основой процесса обучения, зависит от того, сколько будет выброшено нейромедиатора.
Все наше обучение с самого детства построено именно на этом и образование совсем новых связей происходит достаточно редко.
В основном, все наше обучение и освоение новых навыков связано с настройкой того, сколько выбрасывается нейромедиатора в местах контакта аксонов и дендритов.
Например, у нас в нервной системе может быть установлена связь между понятиями «яблоко» и «груша». Т.е. как только мы видим яблоко, слышим слово «яблоко» или просто думаем о нем, в нашем мозгу по механизму ассоциации возникает образ груши, т.к. между этими понятиями у нас установлена связь — сформирована нейронная дорожка.
При этом между понятиями «яблоко» и подушка такой связи, скорее всего нет, поэтому образ яблока не вызывает у нас ассоциаций с подушкой — соответствующая нейронная связь очень слаба или отсутствует.
Интересный момент, о котором также стоит упомянуть, заключается в том, что у насекомых аксон и дендрит связаны напрямую, без выделения нейромедиатора, поэтому у них не происходит обучения в том виде, как оно происходит у животных и человека.
В течение жизни они не обучаются. Они рождаются уже умея всё, что они будут уметь в течение жизни.
Например, каждая конкретная муха не способна научиться облетать стекла — она всегда будет в них биться, что мы с вами постоянно и наблюдаем.
Все нейронные связи у них уже существуют, а сила передачи каждого сигнала уже отрегулирована определенным образом для всех имеющихся связей.
С одной стороны, такая негибкость в плане обучения имеет свои минусы.
С другой стороны, у насекомых, как правило, очень высокая скорость реакции именно за счет другой организации нервных связей, за счет отсутствия веществ-медиаторов, которые, будучи своеобразными посредниками, естественным образом замедляют процесс передачи сигналов.
При всем при этом обучение у насекомых все же может происходить, но только эволюционно — от поколения к поколению.
Допустим, если способность облетать стекла станет важных фактором, способствующим выживанию вида как такового, то за некоторое количество поколений все мухи в мире научатся их облетать.
Пока этого не могло произойти, т.к. сами стекла существую относительно недавно, а для эволюционного обучения могут потребоваться десятки тысяч лет.
Если же это не играет важной роли для сохранения вида, то данная модель поведения так и не будет ими приобретена.
Обычно при работе математическими нейронами используются следующие обозначения:
X – входные данные
W – веса
H – тело нейрона
Y – выход нейронной сети
Входные данные — это сигналы, поступающие к нейрону.
Веса – это эквиваленты синаптической связи и выброса нейромедиатора, представленные в виде чисел, в том числе отрицательных.
Вес представлен действительным числом, на которое будет умножено значение входящего в нейрон сигнала.
Иными словами, вес показывает, насколько сильно между собой связаны те или иные нейроны — это коэффициент связи между ними.
В теле нейрона накапливается взвешенная сумма от перемножения значений входящих сигналов и весов.
Если говорить кратко, то процесс обучения нейронной сети — это процесс изменения весов, т.е. коэффициентов связи между имеющимися в ней нейронами.
В процессе обучения веса меняются, и, если вес положительный, то идет усиление сигнала в нейроне, к которому он приходит.
Если вес нулевой, то влияние одного нейрона на другой отсутствует. Если же вес отрицательный, то идет погашение сигнала в принимающего нейроне.
И, наконец, выход нейронной сети — это то, что мы получаем в результате обработки нейроном поданного на него сигнала. Это некая функция от накопившейся в теле нейрона взвешенной суммы.
Эти функции бывают разные, например, если мы имеем дело с функцией Хевисайда, то если в теле нейрона накопилась сумма больше определенного порога, то на выходе будет единица. Если же меньше порога — ноль.
На выходе из нейрона возможны разные значения, однако чаще всего их стараются приводить к диапазону от -1 до 1 или, что бывает еще чаще — от 0 до 1.
Еще один пример — это функция ReLU (на иллюстрации не представлена), которая работает иначе: если значение взвешенной суммы в теле нейрона отрицательно, то идет преобразование в 0, а если положительно, то в X.
Так, если значение на нейроне было -100 то после обработки функцией ReLU оно станет равным 0. Если же это значение равно, например, 15,7, то на выходе будут те же 15,7.
Также для обработки сигнала с тела нейрона применяются сигмоидальные функции (логистическая и гиперболический тангенс) и некоторые другие. Обычно они используются для «сглаживания» значений некоторой величины.
К счастью, для написания кода необязательно понимать различные формулы и графики этих функций, т.к. они уже заложены в библиотеках, используемых для работы с нейронными сетями.
Простейший пример классификации 2 объектов
Теперь, когда мы разобрались с общим принципом работы, давайте посмотрим на простейший пример, иллюстрирующий процесс классификации 2 объектов с помощью нейронной сети.
Представим, что нам нужно отличить входной вектор (1,0) от вектора (0,1). Допустим, черное от белого, или белое от черного.
При этом, в нашем распоряжении есть простейшая сеть из 2 нейронов.
Допустим, что мы зададим верхней связи вес «+1», а нижней – «-1». Теперь, если мы подадим на вход вектор (1,0), то на выходе мы получим 1.
Если же мы подадим на вход вектор (0,1), то на выходе получим уже -1.
Для упрощения примера будем считать, что у нас здесь используется тождественная активационная функция, при которой f(x) равно самому x, т.е. функция никак не преобразует аргумент.
Таким образом, наша нейронная сеть может классифицировать 2 разных объекта. Это совсем-совсем примитивный пример.
Обратите внимание на то, что в данном примере мы сами назначаем веса «+1» и «-1», что не совсем неправильно. В действительности они подбираются автоматически в процессе обучения сети.
Обучение нейронной сети – это подбор весов.
Любая нейронная сеть состоит из 2 составляющих:
- Архитектура
- Веса
Архитектура — это её структура и то, как она устроена изнутри (об этом мы поговорим чуть позже).
И когда мы подаем на вход нейронной сети данные, нам нужно её обучить, т.е. подобрать веса между нейронами так, чтобы она действительно выполняла то, что мы от неё ожидаем, допустим, умела отличать фото кошек от фото собак.
На самом деле, обучением нейронной сети можно назвать также и подбор архитектуры в процессе исследования.
Так, например, если мы работаем с генетическими алгоритмами, то в процессе обучения нейронная сеть может менять не только веса, но еще и свою структуру.
Но это скорее исключение, чем правило, поэтому в общем случае под обучением нейронной сети мы будем понимать именно процесс подбора весов.
1. С учителем
Обучение с учителем — это одна из самых частых задач. В этом случае у нас есть выборка, и мы знаем по ней правильные ответы.
Мы точно заранее знаем, что на этих 10 тыс. фото — собаки, а на этих 10 тыс. фото — кошки.
Или мы точно знаем курс каких-нибудь акций на протяжении длительного времени.
Допустим, 5 дней до этого дня были такие цены, а на следующий день цена стала такой-то. Затем смещаемся на день вперед, и мы снова знаем: 5 дней цены были такие, а на следующий день цена стала такой-то, и так далее.
Или мы знаем характеристики домов и их реальные цены, если мы говорим про прогнозирование цен на недвижимость.
Все это — примеры обучения с учителем.
2. Без учителя
Второй тип обучения — это обучение без учителя (кластеризация).
В этом случае мы подаем на вход сети некие данные и предполагаем, что в них можно выделить несколько классов.
Пример: у нас есть большая база email-адресов людей, с которыми мы взаимодействуем.
Они открывают наши письма, читают их, переходят или не переходят по ссылкам. Они делают это в то или иное время суток и т.д.
Обладая этой информацией (например, благодаря статистике почтового рассыльщика), мы можем передать нейронной сети эти данные с «просьбой» выделить несколько классов читателей, которые по тем или иным критериям будут схожи между собой.
Используя эти данные, мы смогли бы выстраивать более эффективную маркетинговую стратегию взаимодействия с каждой из таких групп людей.
Обучение без учителя используется в тех случаях, когда требуется обнаружить внутренние взаимосвязи, зависимости и закономерности, существующие между объектами, но заранее мы не знаем, в чем именно заключаются эти закономерности.
3. С подкреплением
Третий тип обучения — это обучение с подкреплением. Оно немного похоже на обучение с учителем, когда есть готовая база верных ответов. Отличие заключается в том, что в этом случае у нейронной сети нет всей базы сразу, а дополнительные данные приходят в процессе обучения и дают сети обратную связь о том, достигнута цель или нет.
Простой пример: бот проходит некий лабиринт и на 59 шаге получает информацию о том, что он «упал в яму» или после 100 шагов, выделенных на выход из лабиринта, он узнает, что «не дошел до выхода».
Таким образом нейронная сеть понимает, что последовательность её действий не привела к нужному результату и обучается, корректируя свои действия.
Т.е. заранее сеть не знает, что верно, а что – нет, но получает обратную связь, когда происходит некое событие. По этому принципу строятся практически все игры, а также различные агенты и боты.
Кстати, пример с умирающими смайликами, который мы рассматривали выше — это также обучение с подкреплением.
Кроме того, это автопилоты, подбор стиля под пожелания конкретного человека, исходя из его предыдущих выборов и т.д.
Например, нейронная сеть генерирует 20 картинок и человек выбирает из них 3, которые ему больше всего нравятся. Затем нейронная сеть создает еще 20 картинок и человек снова выбирает то, что ему нравится больше всего и т.д.
Таким образом, сеть выявляет предпочтения человека по стилю изображения, цветовой гамме и другим характеристикам, и может создавать изображения под вкусы каждого конкретного человека.
Одной из ключевых задач при создании нейронных сетей является выбор её архитектуры. Он производится разработчиком, исходя из стоящей перед ним задачи и, в общем случае, нейронная сеть обучается только за счет изменения весов.
Исключение – генетические алгоритмы, когда популяция нейронных сетей в процессе обучения самостоятельно пересобирает саму себя и свою архитектуру в том числе.
Однако в подавляющем большинстве случаев в процессе обучения архитектура нейронной сети самопроизвольно не меняется.
Все изменения в нее вносит сам разработчик через добавление или удаление слоев, увеличение или уменьшение количества нейронов на каждом слое и т.д.
Давайте посмотрим на основные архитектуры и начнем с классического примера — полносвязной нейронной сети прямого распространения.
Полносвязная нейронная сеть прямого распространения — это сеть, в которой каждый нейрон связан со всеми остальными нейронами, находящимися в соседних слоях, и в которой все связи направлены строго от входных нейронов к выходным.
Слева на рисунке мы видим входной слой, на который приходит сигнал. Правее находятся два скрытых слоя, и самый правый слой из двух нейронов – выходной слой.
Эта сеть может решить задачу классификации, если нам нужно выделить два любых класса – допустим, кошек и собак.
Например, верхний из этих двух нейронов отвечает за класс «собаки» и может иметь значения 0 или 1. Нижний – за класс «кошки», и имеет возможность принимать те же самые значения – 0 или 1.
Другой вариант — она может, к примеру, прогнозировать 2 параметра — давление и температуру в котле на основании 3 неких входных данных.
Чтобы лучше понять, как это работает, давайте посмотрим, как такая полносвязная сеть может использоваться, допустим, для прогнозирования погоды.
В этом примере мы подаем на вход температурные данные по трем последним дням, а на выходе хотим получить предсказания на два следующих дня.
Между входным и выходным слоями у нас есть 2 скрытых слоя, в которых нейронная сеть будет обобщать данные.
Например, в первом скрытом слое один нейрон будет отвечать за такое простое понятие, как «температура растет».
Другой нейрон будет отвечать за понятие «температура падает».
Третий – за понятие «температура неизменна».
Четвертый – «температура очень высокая».
Пятый – «температура высокая».
Шестой – «температура нормальная».
Седьмой – «температура низкая».
Восьмой – «совсем низкая».
Девятый – «температура скакнула вниз и вернулась».
И так далее.
Мы, разумеется, называет все это словами, понятными нам, в то время как сеть сама в процессе обучения сделает так, что каждый из нейронов будет за что-то отвечать, чтобы эффективно обобщать данные.
И каждый из нейронов первого скрытого слоя (в т.ч. обведенный на картинке) будет отвечать за выделение определенного признака в поступивших данных.
Например, если он отвечает за понятие «температура растет», то нейрон с температурой +17 со входного слоя будет входить в него с положительным весом.
Нейрон с температурой +15 – с нулевым весом, а нейрон с температурой +12 – с отрицательным весом.
Если этот так, т.е. температура реально росла и подавались такие данные, обведенный на рисунке нейрон будет активироваться. Если же температура падала, он останется неактивированным.
Нейроны второго скрытого слоя (например, обведенный на картинке ниже), будут отвечать за более высокоуровневые признаки, например, за то, что это осень. Или за то, что это любое другое время года.
На активацию данного нейрона будет положительно влиять падение температуры, свойственное осени.
Если наблюдается постепенный рост температуры, то, скорее всего, это статистически будет влиять в минус, т.е. не будет активировать данный нейрон.
Понятно, что бывают ситуации, когда осенью температура растет, но, скорее всего, статистически рост температуры в течение 3 дней будет отрицательно влиять на этот нейрон.
То, что температура слишком высокая, точно будет отрицательно влиять на нейрон, отвечающий за осень, т.к. не бывает очень высоких температур в это время года, и так далее.
И, наконец, нейроны 2 скрытого слоя соединяются с двумя выходными нейронами, которые выдают предсказание по температуре.
При этом обратите внимание, что сами мы не задаем, за что будет отвечать каждый из нейронов (это было бы примером классического машинного обучения). Нейронная сеть сама сделает нейроны «ответственными» за те или иные понятия.
Более того, в рамках нейронной сети привычные нам понятия, такие как «весна», «осень», «температура падает» и т.д. не существуют. Мы просто обозначили их так для своего удобства, чтобы нам было понятнее, что примерно происходит внутри во время обучения.
В действительности же нейронная сеть сама в процессе обучения выделит именно те свойства, которые нужны для решения данной конкретной задачи.
Важно понимать, что нейронная сеть именно с такой архитектурой не будет правильно прогнозировать температуру – это упрощенный пример, показывающий, как внутри сети может происходить выделение различных признаков (так называемый процесс feature extraction).
Процесс выделения признаков хорошо иллюстрирует работа свёрточных нейронных сетей.
Допустим, на вход сети мы подаем фото кошек и собак, и сеть начинает их анализировать.
На первых слоях сеть определяет наиболее общие признаки: линия, круг, темное пятно, угол, близкий к прямому, яркое пятно на фоне темного и т.д.
На следующем слое сеть сможет извлечь уже иные признаки: ухо, лапа, голова, нос, хвост и т.д.
Еще дальше, на следующем слое будет идет анализ уже такого плана:
— здесь хвост загнут вверх, это коррелирует с лайкой, значит собака;
— а тут короткие лапы, а у кошек нет коротких лап, поэтому, скорее всего, собака, такса;
— а вот здесь треугольное ухо с белым кончиком, похоже на такую-то породу кошки, и т.д.
Примерно таким образом происходит процесс feature extraction.
Безусловно, чем больше нейронов в сети, тем более детальные, специфические свойства она может выделить.
Если же нейронов немного, она сможет работать только «крупными мазками», т.к. у нее не хватит мощности проанализировать все возможные комбинации признаков.
Таким образом, общий принцип выделения свойств — это все большее обобщение при переходе с одного слоя на другой, от низкого уровня ко все более высокому.
Итак, давайте снова вспомним, что из себя представляет нейронная сеть.
Во-первых, это архитектура.
Она задается разработчиком, т.е. мы сами определяем, сколько у сети слоев, как они связаны, сколько нейронов на каждом слое, есть ли у этой сети память (об этом чуть позже), какие у нее активационные функции и т.д.
Архитектуру сети можно представить, например, как обычный JSON, YAML или XML-файл (текстовые файлы, в которых можно полностью отразить её структуру).
Во-вторых, это обученные веса.
Веса нейронной сети хранятся в совокупности матриц в виде действительных чисел, количество которых (чисел) равно общему количеству связей между нейронами в самой сети.
Количество самих матриц зависит от количества слоев и того, как нейроны разных слоев связаны друг с другом.
Веса задаются в начале обучения (обычно случайным образом) и подбираются в процессе обучения.
Таким образом, сеть можно легко сохранить через сохранение её архитектуры и весов, а в дальнейшем снова использовать её, обратившись к файлам с архитектурой и весами.
Обучение полносвязной сети методом обратного распространения ошибки (градиентного спуска)
Как же обучается полносвязная нейронная сеть прямого распространения? Давайте рассмотрим этот вопрос на примере метода обратного распространения ошибки, являющегося модификацией метода классического градиентного спуска.
Это метод обновления весов нейронной сети, при котором распространение сигналов ошибки происходит от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы.
Сразу отметим, что это не самый продвинутый алгоритм, и при работе с библиотекой Keras мы будем использовать более эффективные решения.
Также важно понимать, что в других типах сетей обучение происходит по другим алгоритмам, однако сейчас нам важно понять общий принцип.
Вернемся к примеру про прогнозирование температуры и допустим, что в качестве выходного сигнала у нас есть 2 вещественных числа т.е. значения температуры в градусах по 2 дням.
Таким образом, мы знаем правильные ответы, т.е. какая температура была на самом деле, и знаем те ответы, которые дала нам нейронная сеть.
В качестве способа измерения величины ошибки при обучении сети мы будем использовать так называемую функцию среднеквадратичной ошибки.
Например, в первый день сеть предсказала нам 10 градусов, а реально было 12. Про второй день она сказала, что будет 11 градусов, и реально также было 11.
Среднеквадратичная ошибка в этом случае составит сумму квадратов разностей предсказанной и реальной температур: ((10-12)² + (11-11)²)/2 = 2.
В процессе обучения нейронной сети алгоритмы (в т.ч. Back Propagation – алгоритм обратного распространения ошибки) ориентированы на то, чтобы менять веса так, чтобы уменьшать эту среднеквадратичную ошибку.
Если она будет равна нулю, это значит, что нейронная сеть гарантированно точно распознает, например, все образы в обучающей выборке.
Понятно, что на практике в ноль она никогда не сходится, но близко к нулю — вполне возможно, и точность в этом случае будет очень высокая.
Метод градиентного спуска
Представим теперь, что у нас есть некоторая поверхность ошибки. Допустим, у нас есть нейронная сеть, в которой 2 веса, и мы можем эти веса менять.
Понятно, что разным значениям этих весов будет соответствовать разная ошибка нейронной сети.
Таким образом, взяв эти значения, мы можем создать двухмерную поверхность, на которой видны соотношения значений весов W₁ и W₂ и значений ошибок X₀-X₄ (см. иллюстрацию).
Теперь представим, что у нас в нейронной сети не два, а тысяча весов, и разные комбинации этих тысяч весов соответствуют разным ошибкам при одной и той же обучающей выборке. В этом случае у нас получается уже тысячемерная поверхность.
Мы можем менять тысячу действительных чисел и каждый раз получать новое значение ошибки.
И эту тысячемерную поверхность можно сравнить с поверхностью измятого одеяла со своими локальными максимумами и минимумами (соответственно максимальными и минимальными значениями функции на заданном множестве). Это и будет называться поверхностью ошибки.
Так вот, обучение нейронной сети – это продвижение по этой тысячемерной поверхности разных весов и получение разных ошибок. И где-то на этой поверхности есть глобальный минимум – такая комбинация этой тысячи весов, при которой ошибка минимальна.
Локальных же минимумов может быть много, и в них значение ошибки достаточно низкое.
Поэтому обучение нейронной сети можно представить как это осмысленное перемещение по этой тысячемерной поверхности с целью добиться минимальной ошибки в некоторой точке.
При этом глобальный минимум, как правило, никто не ищет – он один, а пространство для поиска огромное. Именно поэтому нашей целью обычно являются как раз локальные минимумы. При всем при этом стоит отметить, что заранее мы не можем знать, какой именно минимум мы нашли – один из локальных, либо глобальный.
Но как именно происходит перемещение по поверхности ошибки? Давайте разберемся.
Важный момент заключается в том, что мы можем посчитать производную ошибки по весам. Иными словами, мы можем математически просчитать, как изменится ошибка, если мы чуть-чуть изменим в какую-то сторону веса.
Таким образом, мы можем вычислить, куда нам нужно сместить веса, чтобы ошибка у нас гарантированно уменьшилась при следующем шаге обучения.
Именно таким образом мы пошагово ищем необходимое направление спуска по поверхности ошибки.
Если мы шагнем слишком широко, то можем перескочить локальный минимум и подняться выше по поверхности ошибки, что для нас нежелательно.
Если же шаг будет небольшим, то мы шагнем вниз, ближе к локальному минимуму, затем снова пересчитаем направление движения и снова сделаем небольшой шаг.
Да, продвинутые алгоритмы могут, например, «перелезть через горку» и найти более глубокий локальный минимум и т.д., но в целом алгоритм обучения построен именно так.
Мы работаем с многомерной поверхностью ошибки в рамках наших весов и ищем, куда нам двигаться, чтобы прийти в локальный минимум, по возможности, максимально глубокий.
Такая архитектура позволяет поэтапно выделять разные признаки на разных слоях. Первые слои при этом выделяют самые простые признаки, например:
— справа – белое, слева – черное
— по центру – яркое, по краям – тусклое
— линия под 45 градусов
— и т.д.
На иллюстрации ниже изображена одномерная свёрточная сеть, в которой не все нейроны связаны со всеми, а каждый нейрон последующего слоя «смотрит» на два нейрона предыдущего слоя (за исключением входного слоя слева).
При этом вы можете обратить внимание, что в правой части свёрточная сеть переходит в полносвязную, т.е. идет объединение двух архитектур. Для чего это нужно вы узнаете буквально несколькими предложениями ниже.
Выделение признаков происходит постепенно, слой за слоем, например: линия – овал – лапа, что отражено на трех иллюстрациях ниже.
В генеративной сети у нас две нейронных сети: одна генерирует образы, а вторая пытается отличить эти образы от некоторых эталонных.
Например, одна сеть-детектор смотрит на фентези-картинки, а другая пытается создавать новые картинки и говорит: «А попробуй отличить фентези-картинки от моих».
Сначала она генерирует картинки, которые сеть-детектор легко отличает, потому что они не очень похожи на фентези-картинки.
Но потом та сеть, которая создает картинки, обучается все больше, и сеть-детектор уже едва может отличить фентези-картинки, которые мы подали ей на вход сами от тех, что сгенерировала вторая сеть.
И сейчас, когда мы рассмотрели основные архитектуры, давайте вспомним типы задач, которые решаются нейронными сетями и сопоставим их с архитектурами, которые для подходят для их решения.
1. Распознавание образов производится средствами полносвязных, свёрточных, рекуррентных сетей.
2. Языковые задачи чаще всего решаются с помощью рекуррентных сетей с памятью, и иногда — с помощью одномерных свёрточных.
3. Обработка аудио и голоса — это полносвязные, одномерные свёрточные, иногда рекуррентные сети.
4. Задачи регрессии и прогнозирования временных рядов решаются с помощью полносвязных и рекуррентных сетей.
5. Наконец, машинное творчество — это генеративные свёрточные и генеративные полносвязные сети.
Таким образом, мы видим, что стандартные архитектуры пересекаются и используются в задачах разного типа.
Мы будем проходить все эти архитектуры: сначала полносвязные, потом свёрточные, рекуррентные и генеративные. После чего уже будем изучать сложные комбинации архитектур.
На этом шаге мы берем какую-нибудь архитектуру исходя из имеющейся задачи и получаем первичные результаты на обучающей и тестовой выборках.
Допустим, у нас задача распознавания кошек и собак. Значит берем сверточную сеть.
Попробуем простую сеть на 5 слоев по 20 нейронов в каждой, а в конце — 2 слоя полносвязной, и обучим.
В результате мы получаем какие-то базовые результаты, некую первичную точность. И уже после этого начинаем думать, как можно её повысить, например:
— создаем различные варианты архитектур (допустим, несколько десятков вариантов) и собираем статистику по ошибке и точности для каждого из вариантов
— пробуем разные активационные функции
— повышаем качество данных (избавление от зашумленных данных)
— и так далее…
В итоге, путем экспериментов и проверки своих предположений мы доводим качество работы сети до желаемого уровня.
И, наконец, наша production-часть обращается к сервису и производит распознавание.
После вывода в production, разумеется, можно продолжить исследования и постепенно улучшать работу сети и подменять её по мере доработки — либо архитектуру, либо веса, либо и то, и другое.
Скажем, вы обучили сеть на относительно небольшом объеме данных, а через некоторое время вам пришло данных в 10 раз больше. Безусловно, стоит переобучить сеть на большем объеме данных и, вполне возможно, повысить качество её работы.
Для этого мы постоянно сравниваем результаты работы нашей сети по точности распознавания на тестовой выборке.
При этом важно постоянно помнить о том, что в области нейронных сетей даже близко нет детерминированных ответов — это всегда исследование и изобретение.
Итак, мы дошли с вами до нашего главного инструмента в создании нейронных сетей — библиотек.
Что такое библиотека? Это набор функций, которые позволяют нам собрать и обучить нейронную сеть без необходимости глубоко понимать математическую базу, лежащую в основе этих процессов.
Совсем недавно библиотек еще не было, но сейчас уже есть достаточно хороший выбор, существенно облегчающий жизнь разработчика и экономящий его время.
Мы не будем останавливаться на каждой библиотеке отдельно — это, скорее, мини-обзор существующих решений, чтобы вы могли в целом в них ориентироваться.
Так, на настоящее время наиболее известными являются следующие библиотеки:
- TensorFlow (Google)
- CNTK (Microsoft)
- Theano (Монреальский институт алгоритмов обучения (MILA))
- Pytorch (Facebook)
- и так далее
- Сама видеокарта (GPU)
- CUDA (программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia)
- cuDNN (библиотека, содержащая оптимизированные для GPU реализации сверточных и рекуррентных сетей, различных функций активации, алгоритма обратного распространения ошибки и т.п., что позволяет обучать нейронные сети на GPU в несколько раз быстрее, чем просто CUDA)
- TensorFlow, CNTK, Theano (надстройки над cuDNN)
Keras же, в свою очередь, использует в качестве бэкенда TensorFlow и некоторые другие библиотеками, позволяя нам пользоваться уже готовым кодом, написанными именно для создания нейронных сетей.
Еще один важный момент, который нужно отметить — это вопрос о том, как со всем этим работает Python. Многие говорят, что он работает медленно.
Да, это так, но Keras генерирует не код Python, Keras генерирует код С++, и именно он уже используется непосредственно для работы нейронной сети, поэтому все работает быстро.
Наш учебный процесс будет построен именно вокруг Google Colaboratory (демонстрации кода, домашние задания и т.д.), и в целом это очень удобно, однако, если вы хотите, то можете работать и в своей, привычной вам среде.
Запускать Google Colaboratory рекомендуется под Google Chrome, и при первой попытке открыть ноутбук (так называется любой документ в Google Colaboratory) вам будет предложено установить в браузер приложение Colaboratory, чтобы в будущем оно автоматически «подхватывало» файлы такого типа.
Теперь, после установки Colaboratory мы можем перейти уже непосредственно к практической части.
В первой строке мы импортируем предустановленный датасет MNIST с изображениями рукописных цифр, которые мы будем распознавать.
Затем мы подключаем библиотеки Sequential и Dense т.к. работаем с полносвязной сетью прямого распространения.
Наконец, мы импортируем дополнительные библиотеки, позволяющие нам работать с данными (NumPy, Matplotlib и др.).
Сразу обратите внимание на модульную структуру ноутбука, благодаря которой вы можете в любом порядке чередовать блоки кода и текстовые поля.
Для того, чтобы добавить новую ячейку кода, текстовое поле или поменять порядок их следования воспользуйтесь, кнопками CODE, TEXT и CELL прямо под основным меню.
Ну и, наконец, для запуска фрагмента кода нам нужно просто нажать на значок play слева вверху от кода. Он появляется при выделении блока с кодом, либо при наведении мышки на пустые квадратные скобки, если блок не выделен.
Следующим шагом с помощью функции load_data мы подгружаем данные, необходимые для обучения сети, где x_train_org и y_train_org – данные обучающей выборки, а x_test_org и y_test_org – данные тестовой выборки.
Их названий выборок понятно, что обучающую выборку мы используем для того, чтобы обучить сеть, в то время как тестовая используется для того, чтобы проверить, насколько качественно произошло это обучение.
Смысл тестовой выборки в том, чтобы проверить, насколько точно отработает наша сеть с данными, с которыми она не сталкивалась ранее. Именно это является самой важной метрикой оценки сети.
В x_train_org находятся сами изображения цифр, на которых обучается сеть, а y_train_org – правильные ответы, какая именно цифра изображена на том или ином изображении.
Сразу важно отметить, что формат представления правильных ответов на выходе из сети — one hot encoding. Это одномерный массив (вектор), хранящий 10 цифр – 0 или 1. При этом положение единицы в этом векторе и говорит нам о верном ответе.
Например, если цифра на картинке изображен 0, то вектор будет выглядеть как в первой строке на картинке ниже.
Если на изображении цифра 2, то единица в векторе будет стоять в 3 позиции (как в строке 2).
Если же на изображении цифра 9, то единица в векторе будет стоять в последней, десятой позиции.
Это объясняется тем, что нумерация в массивах по умолчанию начинается с нуля.
Изначально на вход сети в обучающей выборке подается 60 тыс. изображений размером 28 на 28 пикселей. В тестовой выборке таких изображений 10 тыс. штук.
Наша задача — привести их к одномерному массиву (вектору), размерность которого будет не 28 на 28, а 1 на 784, что мы и делаем в коде выше.
Следующий наш шаг – это так называемая нормализация данных, их «выравнивание» с целью привести их значения к диапазону от 0 до 1.
Дело в том, что до нормализации изображение каждой рукописной цифры (все они представлены в градациях серого) представлено числами от 0 до 255, где 0 представляет собой чёрный цвет, а 255 — белый).
Однако для эффективной работы сети нам необходимо привести их к другому диапазону, что мы и делаем, разделив каждое значение на 255.
В данном случае количество нейронов (800) уже подобрано эмпирически. При таком количестве нейронная сеть обучается лучше всего (безусловно, на старте своих исследований мы можем пробовать самые разные варианты, постепенно приходя к оптимальному).
В качестве выходного слоя у нас будет полносвязный слой из 10 нейронов – по количеству рукописных цифр, которые мы распознаём.
И наконец, функция softmax будет преобразовывать вектор из 10 значений в другой вектор, в котором каждая координата представлена вещественным числом в интервале [0,1] и сумма этих координат равна 1.
Эта функция применяется в машинном обучении для задач классификации, когда количество классов больше двух, при этом полученные координаты трактуются как вероятности того, что объект принадлежит к определенному классу.
После этого мы компилируем сеть и выходим на экран ее архитектуру.
Сначала мы записываем сеть в файл, затем можем проверить, что он сохранился, после чего сохраняем файл на компьютер с помощью метода download.
Ну что ж, теперь настало время проверить, как наша сеть распознает рукописные цифры, которые она еще не видела. Для этого нам понадобится тестовая выборка, которая, наряду с обучающей, также входит в датасет MNIST.
Для начала выберем произвольную цифру из набора тестовых данных и выведем её на экран:
Теперь, когда мы получили некие первичные результаты, мы можем продолжить процесс исследования, меняя различные параметры нашей нейронной сети.
Например, мы можем поменять количество нейронов во входном слое и уменьшить их количество с 800, например, до 10.
Для того, чтобы запустить сеть обучаться повторно после внесенных изменений с нуля, нам необходимо заново пересобрать модель, запустить код с измененными параметрами сети и снова её скомпилировать (в противном случае сеть будет дообучаться, что требуется далеко не всегда).
Для этого мы просто заново нажимаем на play последовательно во всех трех блоках кода (см. ниже).
В результате этих действий вы увидите, что исходные данные изменились, и сеть теперь имеет 2 слоя по 10 нейронов, вместо 800 и 10, которые были ранее.
Как мы видим, даже при одном нейроне в скрытом слое сеть достигла точности почти в 38%. Понятно, что с таким результатом она едва ли найдет практическое применение, однако мы делаем это просто для понимания того, как могут разниться результаты при изменении архитектуры.
Итак, завершая разбор кода, следует сделать важную оговорку: то, что мы смотрим точность на обучающей выборке – это просто пример для понимания того, как это работает.
В действительности, качество работы сети нужно замерять исключительно на тестовой выборке с данными, с которыми нейронная сеть еще не сталкивалась ранее.
И теперь, когда мы немного поэкспериментировали, давайте подведем небольшой итог и посмотрим, как подойти к проведению экспериментов с нейронными сетями системно, чтобы получать действительно статистически значимые результаты.
Итак, мы берем одну модель сети, и в цикле формируем из имеющихся данных 100 разных обучающих и тестовых выборок в пропорции 80% — обучающая выборка, и 20% — тестовая.
Далее на всех этих данных мы проводим 100 обучений нейронной сети со случайной точки (каждый раз сеть стартует со случайными весами) и получаем некую ошибку на тестовой выборке — среднюю за эти 100 обучений на данной конкретной архитектуре (но с разными комбинациями обучающей и тестовой выборок).
Потом берется другая архитектура и делается то же самое. Таким образом мы можем проверить, например несколько десятков вариантов архитектур по 100 обучений на каждой, в результате чего получим статистически значимые результаты своих экспериментов и сможем выбрать самую точную сеть.
Ну что ж, на этом мы завершаем данный обзор и надеемся, что он помог вам лучше понять как работают нейронные сети, и как можно быстро написать свою первую нейронную сеть на Python.
Сегодня мы разберём, зачем нужна библиотека TensorFlow и как её установить, что такое машинное обучение и как научить компьютер решать уравнения. Всё это — в одной статье.
Фреймворк TensorFlow — это относительно простой инструмент, который позволяет быстро создавать нейросети любой сложности. Он очень дружелюбен для начинающих, потому что содержит много примеров и уже готовых моделей машинного обучения, которые можно встроить в любое приложение. А продвинутым разработчикам TensorFlow предоставляет тонкие настройки и API для ускоренного обучения.
TensorFlow поддерживает несколько языков программирования. Главный из них — это Python. Кроме того, есть отдельные пакеты для C/C++, Golang и Java. А ещё — форк TensorFlow.js для исполнения кода на стороне клиента, в браузере, на JavaScript.
Этим возможности фреймворка TensorFlow не ограничиваются. Библиотеку также можно использовать для обучения моделей на смартфонах и умных устройствах (TensorFlow Lite) и создания корпоративных нейросетей (TensorFlow Extended).
Чтобы создать простую нейросеть на TensorFlow, достаточно понимать несколько основных принципов:
- что такое машинное обучение;
- как обучаются нейросети и какие методы для этого используются;
- как весь процесс обучения выглядит в TensorFlow.
О каждом из этих пунктов мы расскажем подробнее ниже.
В обычном программировании всё работает по заранее заданным инструкциям. Разработчики их прописывают с помощью выражений, а компьютер строго им подчиняется. В конце выполнения компьютер выдаёт результат.
Например, если описать в обычной программе, как вычисляется площадь квадрата, компьютер будет строго следовать инструкции и всегда выдавать стабильный результат. Он не начнёт придумывать новые методы вычисления и не будет пытаться оптимизировать сам процесс вычисления. Он будет всегда следовать правилам — тому самому алгоритму, выраженному с помощью языка программирования.
Иллюстрация: Оля Ежак для Skillbox Media
Машинное обучение работает по-другому. Нам нужно отдать компьютеру уже готовые результаты и входные данные и сказать: «Найди алгоритм, который сможет сделать из этих входных данных вот эти результаты». Нам неважно, как он будет это делать. Для нас важнее, чтобы результаты были точными.
Ещё мы должны говорить компьютеру, когда он ответил правильно, а когда — неправильно. Это сделает обучение эффективным и позволит нейросети постепенно двигаться в сторону более точных результатов.
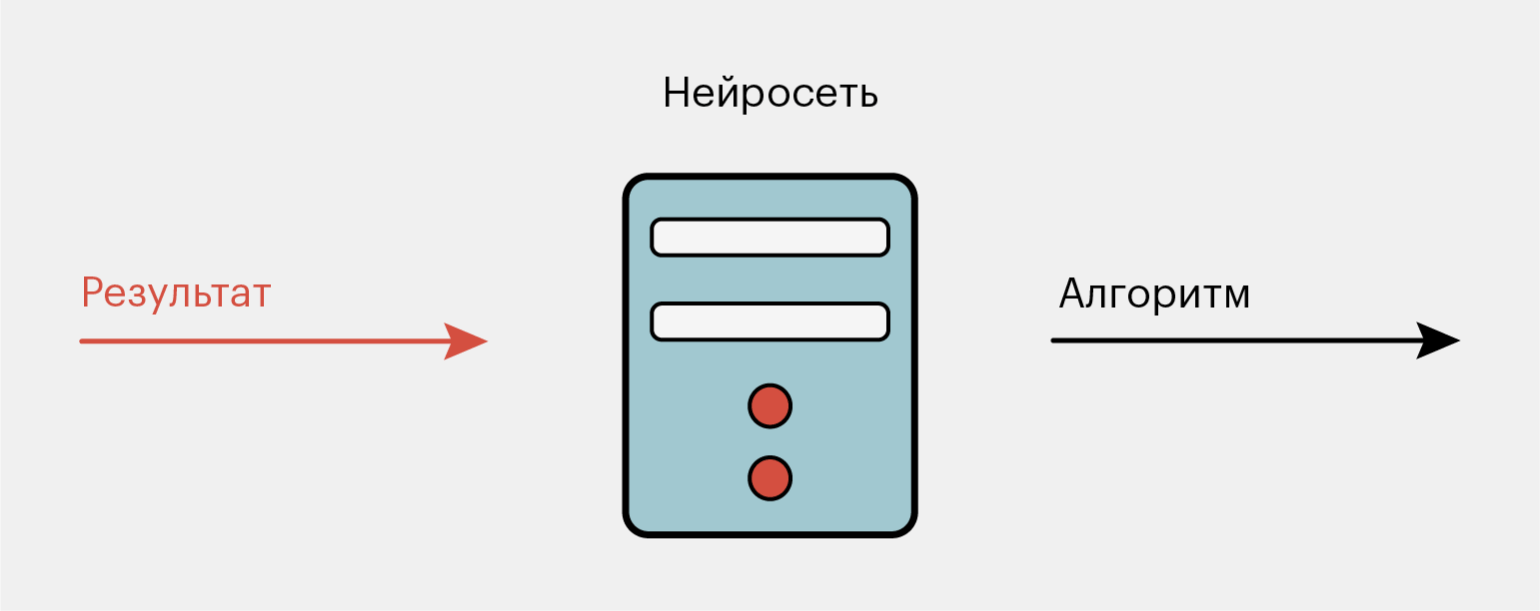
Иллюстрация: Оля Ежак для Skillbox Media
В целом машинное обучение похоже на обучение обычного человека. Например, чтобы различать обувь и одежду, нам нужно посмотреть на какое-то количество экземпляров обуви и одежды, высказать свои предположения относительно того, что именно сейчас находится перед нами, получить обратную связь от кого-то, кто уже умеет их различать, — и тогда у нас появится алгоритм, как отличать одно от другого. Увидев туфли после успешного обучения, мы сразу сможем сказать, что это обувь, потому что по всем признакам они соответствуют этой категории.
Чтобы начать пользоваться фреймворком TensorFlow, можно выбрать один из вариантов:
- установить его на компьютер;
- воспользоваться облачным сервисом Google Colab.
В начале можно попробовать второй вариант, потому что для него не нужно ничего скачивать — всё хранится и работает в облаке. К тому же вычисления не нуждаются в мощностях вашего компьютера, вместо этого используются серверы Google.
Заходим на сайт Google Colab и создаём новый notebook:
Скриншот: Skillbox Media
У нас появится новое пространство, в котором мы и будем писать весь код. Сверху слева можно изменить название документа:
Скриншот: Skillbox Media
Google Colab состоит из ячеек с кодом или текстом. Чтобы создать ячейку с кодом, нужно нажать на кнопку + Code. Ниже появится ячейка, где можно писать Python‑код:
Скриншот: Skillbox Media
Теперь нам нужно проверить, что всё работает. Для этого попробуем экспортировать библиотеку в Google Colab. Делается это через команду import tensorflow as tf:
Скриншот: Skillbox Media
Всё готово. Рассмотрим второй способ, как можно подключить TensorFlow прямо на компьютере.
Чтобы использовать библиотеку TensorFlow на компьютере, её нужно установить через пакетный менеджер PIP.
Открываем терминал и вводим следующую команду:
pip install --upgrade pip
Мы обновили PIP до последней версии. Теперь скачиваем сам TensorFlow:
pip install tensorflow
Если всё прошло успешно, теперь вы можете подключать TensorFlow в Python-коде у вас на компьютере с помощью команды:
import tensorflow as tf
Но если возникли какие-то ошибки, можете прочитать более подробный гайд на официальном сайте TensorFlow и убедиться, что у вас скачаны все нужные пакеты.
Ниже мы будем использовать Google Colab для примеров, но код должен работать одинаково и корректно где угодно.
Допустим, у нас есть два набора чисел X и Y:
X: -1 0 1 2 3 4 Y: -4 1 6 11 16 21
Мы видим, что их значения связаны по какому-то правилу. Это правило: Y = 5X + 1. Но чтобы компьютер это понял, ему нужно научиться сопоставлять входные данные — X — с результатом — Y. У него сначала могут получаться странные уравнения типа: 2X — 5, 8X + 1, 4X + 2, 5X — 1. Но, обучившись немного, он найдёт наиболее близкую к исходной формулу.
Обучается нейросеть итеративно — или поэтапно. На каждой итерации она будет предлагать алгоритм, по которому входные значения сопоставляются с результатом. Затем она проверит свои предположения, вычислив все входные данные по формуле и сравнив с настоящими результатами. Так она узнает, насколько сильно ошиблась. И уже на основе этих ошибок скорректирует формулу на следующей итерации.
Количество итераций ограничено разве что временем разработчика. Главное — чтобы нейросеть на каждом шаге улучшала свои предположения, иначе весь процесс обучения будет бессмысленным.
Теперь давайте создадим модель, которая научится решать поставленную выше задачу. Сперва подключим необходимые зависимости:
import tensorflow as tf import numpy as np from tensorflow import keras
Первая зависимость — это наша библиотека TensorFlow, название которой мы сокращаем до tf, чтобы было удобнее её вызывать в программе. NumPy — это библиотека для эффективной работы с массивами чисел. Можно было, конечно, использовать и обычные списки, но NumPy будет работать намного быстрее, поэтому мы берём его. И последнее — Keras, встроенная в Tensorflow библиотека, которая умеет обучать нейросети.
Теперь создадим самую простую модель:
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
Разберём код подробнее. Sequential — это тип нейросети, означающий, что процесс обучения будет последовательным. Это стандартный процесс обучения для простых нейросетей: в нём она сначала делает предсказания, затем тестирует их и сравнивает с результатом, а в конце — корректирует ошибки.
keras.layers.Dense — указывает на то, что мы хотим создать слой в нашей модели. Слой — это место, куда мы будем складывать нейроны, которые запоминают информацию об ошибках и которые отвечают за «умственные способности» нейросети. Dense — это тип слоя, который использует специальные алгоритмы для обучения.
В качестве аргумента нашей нейросети мы передали указания, какой именно она должна быть:
- units=1 означает, что модель состоит из одного нейрона, который будет запоминать информацию о предыдущих предположениях;
- input_shape=[1] говорит о том, что на вход будет подаваться одно число, по которому нейросеть будет строить зависимости двух рядов чисел: X и Y.
Модель мы создали, теперь давайте её скомпилируем:
model.compile(optimizer='sgd', loss='mean_squared_error')
Здесь появляются два важных для машинного обучения элемента: функция оптимизации и функция потерь. Обе они нужны, чтобы постепенно стремиться к более точным результатам.
Функция потерь анализирует, насколько правильно нейросеть дала предсказание. А функция оптимизации исправляет эти предсказания в сторону более корректных результатов.
Мы использовали стандартные функции для большинства моделей — sgd и mean_squared_error. sgd — это метод оптимизации, который работает на формулах математического анализа. Он помогает скорректировать формулу, чтобы прийти к правильной. mean_squared_error — это функция, которая вычисляет, насколько сильно отличаются полученные результаты по формуле, предложенной нейросетью, от настоящих результатов. Эта функция тоже участвует в корректировке формулы.
Теперь давайте зададим наборы данных:
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float) ys = np.array([-4.0, 1.0, 6.0, 11.0, 16.0, 21.0], dtype=float)
Как видно, это обычные массивы чисел, которые мы передадим модели на обучение:
model.fit(xs, ys, epochs=500)
Функция fit как раз занимается обучением. Она берёт набор входных данных — xs — и сопоставляет с набором правильных результатов — ys. И так нейросеть обучается в течение 500 итераций — epochs=500. Мы использовали 500 итераций, чтобы наверняка прийти к правильному результату. Суть простая: чем больше итераций обучения, тем точнее будут результаты (однако улучшение точности с каждым повтором будет всё меньше и меньше).
На каждой итерации модель проходит следующие шаги:
- берёт весь наш набор входных данных;
- пытается сделать предсказание для каждого элемента;
- сравнивает результат с корректным результатом;
- оптимизирует модель, чтобы давать более точные прогнозы.
Скриншот: Skillbox Media
Можно заметить, что на каждой итерации TensorFlow выводит, насколько нейросеть сильно ошиблась — loss. Если это число уменьшается, то есть стремится к нулю, значит, она действительно обучается и с каждым шагом улучшает свои прогнозы.
Теперь давайте что-нибудь предскажем и поймём, насколько точно наша нейросеть обучилась:
print(model.predict([10.0]))
Мы вызываем у модели метод predict, который получает на вход элемент для предсказания. Результат будет таким:
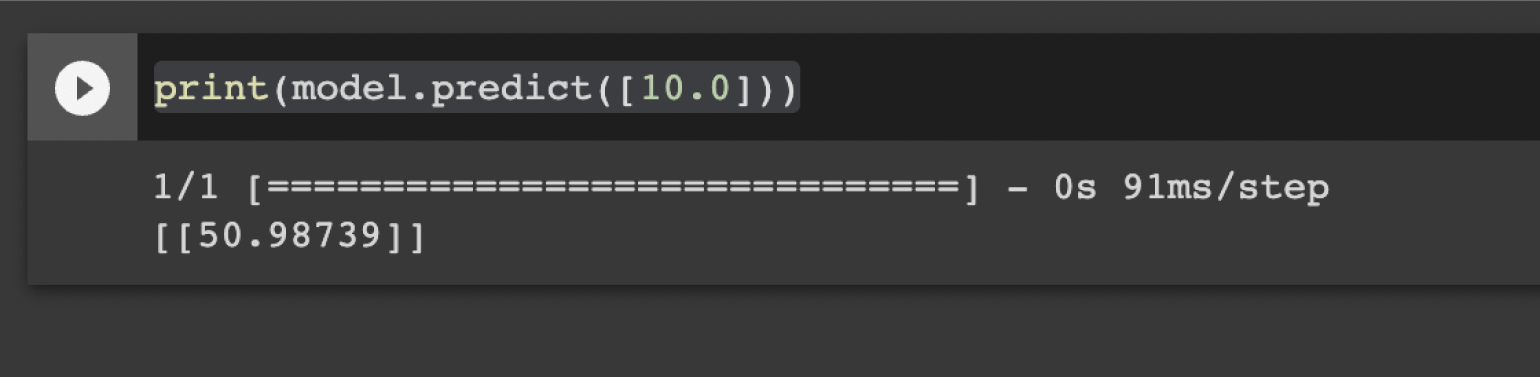
Скриншот: Skillbox Media
Получилось странно — мы ожидали, что будет число 51 (потому что подставили 10 в выражение 5X + 1) — но на выходе нейросеть выдала число 50.98739. А всё потому, что модель нашла очень близкую, но не до конца точную формулу — например, 4.891X + 0.993. Это одна из особенностей машинного обучения.
А ещё многое зависит от выбранного метода оптимизации — то есть того, как нейросеть корректирует формулу, чтобы прийти к нужным результатам. В библиотеке TensorFlow можно найти разные способы оптимизации, и на выходе каждой из них результаты могут различаться. Однако эта тема выходит за рамки нашей статьи — здесь уже необходимо достаточно глубоко погружаться в процесс машинного обучения и разбираться, как именно устроена оптимизация.
Если вы вдруг подумали, что можно просто увеличить число итераций и точность станет выше, то это справедливо лишь отчасти. У каждого метода оптимизации есть своя точность, до которой нейросеть может дойти. Например, она может вычислять результат с точностью до 0.00000001, однако абсолютно верным и точным результат не будет никогда. А значит, и абсолютно точного значения формулы мы никогда не получим — просто из-за погрешности вычислений и особенности функционирования компьютеров. Но если условно установить число итераций в миллиард, можно получить примерно такую формулу:
4.9999999999997X + 0.9999999999991
Она очень близка к настоящей, хотя и не равна ей. Поэтому математики и специалисты по машинному обучению решили, что будут считать две формулы равными, если значения их вычислений меньше, чем заранее заданная величина погрешности — например, 0.0000001. И если мы подставим в формулу выше и в настоящую вместо X число 5, то получим следующее:
5 · 5 + 1 = 26
4.9999999997 · 5 + 0.9999999991 = 25.9999999976
Если мы из первого числа вычтем второе, то получим:
26 — 25.9999999976 = 0.0000000024
А так как изначально мы сказали, что два числа будут равны, если разница между ними меньше 0.0000001, то обе формулы могут считаться идентичными, потому что получившаяся у нас на практике погрешность 0.0000000024 меньше допустимого значения, о котором мы договорились, — то есть 0.0000001. Вот такая интересная математика.
С помощью статьи PhD Оксфордского университета и автора книг о глубоком обучении Эндрю Траска показываем, как написать простую нейронную сеть на Python. Она умещается всего в девять строчек кода и выглядит вот так:
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) — 1
for iteration in xrange(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(training_set_inputs.T, (training_set_outputs — output) * output * (1 — output))
print 1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights))))
Чуть ниже объясним как получается этот код и какой дополнительный код нужен к нему, чтобы нейросеть работала. Но сначала небольшое отступление о нейросетях и их устройстве.
Человеческий мозг состоит из ста миллиардов клеток, которые называются нейронами. Они соединены между собой синапсами. Если через синапсы к нейрону придет достаточное количество нервных импульсов, этот нейрон сработает и передаст нервный импульс дальше. Этот процесс лежит в основе нашего мышления.

Мы можем смоделировать это явление, создав нейронную сеть с помощью компьютера. Нам не нужно воссоздавать все сложные биологические процессы, которые происходят в человеческом мозге на молекулярном уровне, нам достаточно знать, что происходит на более высоких уровнях.
Для этого мы используем математический инструмент — матрицы, которые представляют собой таблицы чисел. Чтобы сделать все как можно проще, мы смоделируем только один нейрон, к которому поступает входная информация из трех источников и есть только один выход (рис. 1). Наша задача — научить нейронную сеть решать задачу, которая изображена на рисунке ниже. Первые четыре примера будут нашим тренировочным набором. Получилось ли у вас увидеть закономерность? Что должно быть на месте вопросительного знака — 0 или 1?

Вы могли заметить, что вывод всегда равен значению левого столбца. Так что ответом будет 1.
Но как научить наш нейрон правильно отвечать на заданный вопрос? Для этого мы зададим каждому входящему сигналу вес, который может быть положительным или отрицательным числом. Если на входе будет сигнал с большим положительным весом или отрицательным весом, то это сильно повлияет на решение нейрона, которое он подаст на выход. Прежде чем мы начнем обучение модели, зададим для каждого примера случайное число в качестве веса. После этого мы можем приняться за тренировочный процесс, который будет выглядеть следующим образом:
- В качестве входных данных мы возьмем примеры из тренировочного набора. Потом мы воспользуемся специальной формулой для расчета выхода нейрона, которая будет учитывать случайные веса, которые мы задали для каждого примера.
- Далее посчитаем размер ошибки, который вычисляется как разница между числом, которое нейрон подал на выход и желаемым числом из примера.
- В зависимости от того, в какую сторону нейрон ошибся, мы немного отрегулируем вес этого примера.
- Повторим этот процесс 10 000 раз.

В какой-то момент веса достигнут оптимальных значений для тренировочного набора. Если после этого нейрону будет дана новая задача, которая следует такой же закономерности, он должен дать верный ответ.
Итак, что же из себя представляет формула, которая рассчитывает значение выхода нейрона? Для начала мы возьмем взвешенную сумму входных сигналов:
![]()
После этого мы нормализуем это выражение, чтобы результат был между 0 и 1. Для этого, в этом примере, я использую математическую функцию, которая называется сигмоидой:
![]()
Если мы нарисуем график этой функции, то он будет выглядеть как кривая в форме буквы S (рис. 4).

Подставив первое уравнения во второе, мы получим итоговую формулу выхода нейрона.
![]()
Вы можете заметить, что для простоты мы не задаем никаких ограничений на входящие данные, предполагая, что входящий сигнал всегда достаточен для того, чтобы наш нейрон подал сигнал на выход.
Во время тренировочного цикла (он изображен на рисунке 3) мы постоянно корректируем веса. Но на сколько? Для того, чтобы вычислить это, мы воспользуемся следующей формулой:
![]()
Давайте поймем почему формула имеет такой вид. Сначала нам нужно учесть то, что мы хотим скорректировать вес пропорционально размеру ошибки. Далее ошибка умножается на значение, поданное на вход нейрона, что, в нашем случае, 0 или 1. Если на вход был подан 0, то вес не корректируется. И в конце выражение умножается на градиент сигмоиды. Разберемся в последнем шаге по порядку:
- Мы использовали сигмоиду для того, чтобы посчитать выход нейрона.
- Если на выходе мы получаем большое положительное или отрицательное число, то это значит, что нейрон был весьма уверен в том или ином решении.
- На рисунке 4 мы можем увидеть, что при больших значениях переменной градиент принимает маленькие значения.
- Если нейрон уверен в том, что заданный вес верен, то мы не хотим сильно корректировать его. Умножение на градиент сигмоиды позволяет добиться такого эффекта.
Градиент сигмоиды может быть найден по следующей формуле:
![]()
Таким образом, подставляя второе уравнение в первое, конечная формула для корректировки весов будет выглядеть следующим образом:
![]()
Существуют и другие формулы, которые позволяют нейрону обучаться быстрее, но преимущество этой формулы в том, что она достаточно проста для понимания.
Хотя мы не будем использовать специальные библиотеки для нейронных сетей, мы импортируем следующие 4 метода из математической библиотеки numpy:
- exp — функция экспоненты
- array — метод создания матриц
- dot — метод перемножения матриц
- random — метод, подающий на выход случайное число
Теперь мы можем, например, представить наш тренировочный набор с использованием array():
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])=
training_set_outputs = array([[0, 1, 1, 0]]).T
Функция .T транспонирует матрицу из горизонтальной в вертикальную. В результате компьютер хранит эти числа таким образом:

Теперь мы готовы к более изящной версии кода. После нее добавим несколько финальных замечаний.
Обратите внимание, что на каждой итерации мы обрабатываем весь тренировочный набор одновременно. Таким образом наши переменные все являются матрицами.
Итак, вот полноценно работающий пример нейронной сети, написанный на Python:
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
Задаем порождающий элемент для генератора случайных чисел, чтобы он генерировал одинаковые числа при каждом запуске программы
random.seed(1)
Мы моделируем единственный нейрон с тремя входящими связями и одним выходом. Мы задаем случайные веса в матрице размера 3 x 1, где значения весов варьируются от -1 до 1, а среднее значение равно 0.
self.synaptic_weights = 2 * random.random((3, 1)) — 1
Функция сигмоиды, график которой имеет форму буквы S.
Мы используем эту функцию, чтобы нормализовать взвешенную сумму входных сигналов.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
Производная от функции сигмоиды. Это градиент ее кривой. Его значение указывает насколько нейронная сеть уверена в правильности существующего веса.
def __sigmoid_derivative(self, x):
return x * (1 — x)
Мы тренируем нейронную сеть методом проб и ошибок, каждый раз корректируя вес синапсов.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in xrange(number_of_training_iterations):
Тренировочный набор передается нейронной сети (одному нейрону в нашем случае).
output = self.think(training_set_inputs)
Вычисляем ошибку (разницу между желаемым выходом и выходом, предсказанным нейроном).
error = training_set_outputs — output
Умножаем ошибку на входной сигнал и на градиент сигмоиды. В результате этого, те веса, в которых нейрон не уверен, будут откорректированы сильнее. Входные сигналы, которые равны нулю, не приводят к изменению веса.
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
Корректируем веса.
self.synaptic_weights += adjustment
Заставляем наш нейрон подумать.
def think(self, inputs):
Пропускаем входящие данные через нейрон.
return self.__sigmoid(dot(inputs, self.synaptic_weights))
if __name__ == «__main__»:
Инициализируем нейронную сеть, состоящую из одного нейрона.
neural_network = NeuralNetwork()
print «Random starting synaptic weights:
» print neural_network.synaptic_weights
Тренировочный набор для обучения. У нас это 4 примера, состоящих из 3 входящих значений и 1 выходящего значения.
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
Обучаем нейронную сеть на тренировочном наборе, повторяя процесс 10000 раз, каждый раз корректируя веса.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print «New synaptic weights after training:
» print neural_network.synaptic_weights
Тестируем нейрон на новом примере.
print «Considering new situation [1, 0, 0] -> ?:
» print neural_network.think(array([1, 0, 0]))
Этот код также можно найти на GitHub. Обратите внимание, что если вы используете Python 3, то вам будет нужно заменить команду “xrange” на “range”.
Попробуйте теперь запустить нейронную сеть, используя в терминале эту команду:
python main.py
Результат должен быть таким:
Random starting synaptic weights:
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
New synaptic weights after training:
[[ 9.67299303]
[-0.2078435 ]
[-4.62963669]]
Considering new situation
[1, 0, 0] -> ?: [ 0.99993704]
Ура, мы построили простую нейронную сеть с помощью Python!
Сначала нейронная сеть задала себе случайные веса, затем обучилась на тренировочном наборе. После этого она предсказала в качестве ответа 0.99993704 для нового примера [1, 0, 0]. Верный ответ был 1, так что это очень близко к правде!
Традиционные компьютерные программы обычно не способны обучаться. И это то, что делает нейронные сети таким поразительным инструментом: они способны учиться, адаптироваться и реагировать на новые обстоятельства. Точно так же, как и человеческий мозг.
Конечно, мы создали модель всего лишь одного нейрона для решения очень простой задачи. Но что если мы соединим миллионы нейронов? Сможем ли мы таким образом однажды воссоздать реальное сознание?