![]()
Загрузить PDF
![]()
Загрузить PDF
Если вы пишете статью или делаете проект, вам нужно найти автора сайта, чтобы получить у него разрешение на использование материалов с сайта.
Шаги
-

1
Перейдите в нижнюю часть страницы. Ищите информацию об авторских правах сайта. Вы должны увидеть имя автора (или название компании) возле даты авторских прав.
-
2
На сайте найдите и щелкните по ссылке «About»(О сайте). Откроется страница с информацией об истории сайта, миссии сайта и, возможно, авторе. Обычно его имя указывается в самой верхней или самой нижней части страницы.
-
3
Откройте страницу «Contact»(Контакт). На ней, возможно, указано имя автора сайта и его контактные данные (адрес электронной почты и телефон). Если это компания, то указывается имя человека, с которым вы можете связаться и узнать имя автора сайта.
Реклама



Советы
- Если автор сайта не указан, в вашей статье/проекте сошлитесь на сайт, его адрес и другую информацию, которая вам известна.
- Вы можете найти автора веб-сайта из других источников (социальных сетей, whois сервисов и других).
- Не перепутайте автора какого-либо раздела сайта с автором всего сайта.
Реклама
Об этой статье
Эту страницу просматривали 26 782 раза.
Была ли эта статья полезной?
![]()
Download Article
Cite a website in MLA or APA
![]()
Download Article
- Finding a Website Author
- Citing a Website Without an Author
- Q&A
- Tips
|
|
|
Finding the author of a website is important if you’re writing a paper or doing a project that requires citations. This information can be difficult to determine, however, especially if the website you’re looking at isn’t article-based. There are several places you can try to look for the author, but if you can’t find one you can still cite the web page. This wikiHow will show you how to find the author of a website and cite a website in MLA or APA.
Things You Should Know
- Check at the top or bottom of an article for the author’s name. You can also search for a «Contact» or «About» page.
- Look in the terms and conditions or the website’s copyright information. Sometimes, you’ll find the author displayed next to the copyright.
- Search Google or WHOIS to find out who the domain is registered to.
-
1
Look at the top and bottom of an article. Many websites that employ contributing and staff writers will often display the author’s name at the top or bottom of an article. This is the first place you should look for an author.
- The author might be listed in an “article info” section, under the article title, or at the end of the article in an “about the author” section.
- Note that if you can’t find the author, your APA in-text citations will use the article title instead. Check out our complete guide to parenthetical citations for more info.
-
2
Find the website’s copyright information. Some websites will display the author next to the copyright information at the bottom of the page. This may be the publishing company as opposed to the actual author.
- You can also try looking at the “term of use” page to find more information about the publisher.
Advertisement
-
3
Look for a «Contact» or «About» page. If the specific page you are looking at does not have an author and is on a reputable website, it was probably authored under the authorization of the company or agency that runs the site. This can serve as the author if no specific author is listed.
-
4
Ask the owners. If you can’t find contact information for the website, you can try sending an email and asking for the author of a specific page or article. You aren’t guaranteed to get a response, but it may be worth a shot.
- Look for “contact information” or “contact us” in the website’s footer.
-
5
Search Google with a portion of the text to look for the original author. If you’re reading a website that isn’t being ethical, it may be displaying information copied from another source. Copy and paste a paragraph of text into a Google search to see if you can find who the original author is.
-
6
Use WHOIS to find the website owner. WHOIS is a database of website registrations, and you can use it to try to track down a website owner. This will not always work, as the owner is often not the author, and many owners and companies use privacy services to hide information.[1]
- Visit whois.icann.org and enter the website address into the search field.
- Look for the «Registrant Contact» information to find who registered the domain. You can still try to contact the owner through their proxy email if the registration information is blocked.






Advertisement
-
1
Find the title of the page or article. You’ll need the title of the article or page you are on as part of your MLA website citation or APA website citation. Even if it’s a blog post, you’ll still need the title.
- If you’re looking for more citation information, check out our guide on citing sources in MLA format.
-
2
Get the website name. Besides the title of the article, you’ll need the name of the website. For example, this article’s title is «How to Find the Author of a Website» and the website name is «wikiHow.»
-
3
Try to find the publisher. This is the company, organization, or person that produces or sponsors the website. This may not be different than the website title, but be sure to check. For example, a health organization may run a separate website devoted to heart health.
- You can typically find the publisher at the bottom of the page, in the copyright information.
-
4
Find the date the page or article was published. This isn’t always possible, but you should always try to find the publication date if you can.
-
5
Get a version number if possible (MLA). If the article or publication has a volume or version number, make sure to note this for MLA citations.
-
6
Get the article or web page URL (APA and older MLA). Depending on which method of citation you’re using, and your instructor’s guidelines, you may need the URL of the page or article.
- MLA7 no longer requires including the URL for websites. The page title and site title are sufficient. Check with your instructor if you use MLA for your citation format.[2]
- You don’t need to include the “https://” part of the URL.[3]
- MLA7 no longer requires including the URL for websites. The page title and site title are sufficient. Check with your instructor if you use MLA for your citation format.[2]
-
7
Get the DOI (digital object identifier) for scholarly journals (APA). If you are citing an online scholarly journal, include the DOI instead of the URL. This ensures that the reader will be able to find the article even if the URL changes:[4]
- For most publications, you can find the DOI at the top of the article. You may need to click an «Article» button or a button with the publisher’s name. This will open the full article with the DOI at the top.
- You can look up a DOI by using the CrossRef search (crossref.org). Enter in the article title or the author to find the DOI.
- Some journal articles will have a button called “cite this source” or similar. This will generate the citation automatically for the article!
-
8
Construct a citation from your available information. Now that you’ve gathered everything you can, even if you don’t have an author, you’re ready to create your citation. Use the following formats, skipping the Author entry if you can’t find one:[5]
-
MLA: Author <Last, First M>. «Article Title.» Website Title. Version Number. Website Publisher, Date Published. Web. Date Accessed.[6]
- Use «n.p.» if there is no publisher and «n.d.» if there is no publishing date.
-
APA: Author <Last, F>. Article Title. (Date Published). Website Title, Issue/Volume Number, Pages Referenced. Retrieved from <Full URL or DOI>[7]
-
MLA: Author <Last, First M>. «Article Title.» Website Title. Version Number. Website Publisher, Date Published. Web. Date Accessed.[6]








Advertisement
Add New Question
-
Question
How do I find the publisher of an article?

This is usually at the bottom, with a copyright symbol and a year.
-
Question
What can I do if there isn’t an About Page?
Try to find details of an email, then type the email or number into Google and a name might pop up.
-
Question
When looking at the author of a website, how do I know if they are credible?
First, look at the author’s credentials. See if they have any professional experience in the field they’re writing about, and if so, look at what they did, how long they did it, and where they did it. Usually if someone has extensive experience in a particular field or about a particular topic, they are considered credible. Then, do some research about the author. Are they generally considered to be credible or are they completely unheard of? Has that author’s work ever been published in any reputable journals? These questions and answers should help you decide whether or not an author can be considered credible.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
Advertisement
About This Article
Article SummaryX
1. Look at the copyright info.
2. Locate the About or Contact page.
3. Search Google for a portion of text to find the original author.
4. Look up the domain name with WHOIS.
Did this summary help you?
Thanks to all authors for creating a page that has been read 515,136 times.
Is this article up to date?
![]()
Download Article
Cite a website in MLA or APA
![]()
Download Article
- Finding a Website Author
- Citing a Website Without an Author
- Q&A
- Tips
|
|
|
Finding the author of a website is important if you’re writing a paper or doing a project that requires citations. This information can be difficult to determine, however, especially if the website you’re looking at isn’t article-based. There are several places you can try to look for the author, but if you can’t find one you can still cite the web page. This wikiHow will show you how to find the author of a website and cite a website in MLA or APA.
Things You Should Know
- Check at the top or bottom of an article for the author’s name. You can also search for a «Contact» or «About» page.
- Look in the terms and conditions or the website’s copyright information. Sometimes, you’ll find the author displayed next to the copyright.
- Search Google or WHOIS to find out who the domain is registered to.
-
1
Look at the top and bottom of an article. Many websites that employ contributing and staff writers will often display the author’s name at the top or bottom of an article. This is the first place you should look for an author.
- The author might be listed in an “article info” section, under the article title, or at the end of the article in an “about the author” section.
- Note that if you can’t find the author, your APA in-text citations will use the article title instead. Check out our complete guide to parenthetical citations for more info.
-
2
Find the website’s copyright information. Some websites will display the author next to the copyright information at the bottom of the page. This may be the publishing company as opposed to the actual author.
- You can also try looking at the “term of use” page to find more information about the publisher.
Advertisement
-
3
Look for a «Contact» or «About» page. If the specific page you are looking at does not have an author and is on a reputable website, it was probably authored under the authorization of the company or agency that runs the site. This can serve as the author if no specific author is listed.
-
4
Ask the owners. If you can’t find contact information for the website, you can try sending an email and asking for the author of a specific page or article. You aren’t guaranteed to get a response, but it may be worth a shot.
- Look for “contact information” or “contact us” in the website’s footer.
-
5
Search Google with a portion of the text to look for the original author. If you’re reading a website that isn’t being ethical, it may be displaying information copied from another source. Copy and paste a paragraph of text into a Google search to see if you can find who the original author is.
-
6
Use WHOIS to find the website owner. WHOIS is a database of website registrations, and you can use it to try to track down a website owner. This will not always work, as the owner is often not the author, and many owners and companies use privacy services to hide information.[1]
- Visit whois.icann.org and enter the website address into the search field.
- Look for the «Registrant Contact» information to find who registered the domain. You can still try to contact the owner through their proxy email if the registration information is blocked.
Advertisement
-
1
Find the title of the page or article. You’ll need the title of the article or page you are on as part of your MLA website citation or APA website citation. Even if it’s a blog post, you’ll still need the title.
- If you’re looking for more citation information, check out our guide on citing sources in MLA format.
-
2
Get the website name. Besides the title of the article, you’ll need the name of the website. For example, this article’s title is «How to Find the Author of a Website» and the website name is «wikiHow.»
-
3
Try to find the publisher. This is the company, organization, or person that produces or sponsors the website. This may not be different than the website title, but be sure to check. For example, a health organization may run a separate website devoted to heart health.
- You can typically find the publisher at the bottom of the page, in the copyright information.
-
4
Find the date the page or article was published. This isn’t always possible, but you should always try to find the publication date if you can.
-
5
Get a version number if possible (MLA). If the article or publication has a volume or version number, make sure to note this for MLA citations.
-
6
Get the article or web page URL (APA and older MLA). Depending on which method of citation you’re using, and your instructor’s guidelines, you may need the URL of the page or article.
- MLA7 no longer requires including the URL for websites. The page title and site title are sufficient. Check with your instructor if you use MLA for your citation format.[2]
- You don’t need to include the “https://” part of the URL.[3]
- MLA7 no longer requires including the URL for websites. The page title and site title are sufficient. Check with your instructor if you use MLA for your citation format.[2]
-
7
Get the DOI (digital object identifier) for scholarly journals (APA). If you are citing an online scholarly journal, include the DOI instead of the URL. This ensures that the reader will be able to find the article even if the URL changes:[4]
- For most publications, you can find the DOI at the top of the article. You may need to click an «Article» button or a button with the publisher’s name. This will open the full article with the DOI at the top.
- You can look up a DOI by using the CrossRef search (crossref.org). Enter in the article title or the author to find the DOI.
- Some journal articles will have a button called “cite this source” or similar. This will generate the citation automatically for the article!
-
8
Construct a citation from your available information. Now that you’ve gathered everything you can, even if you don’t have an author, you’re ready to create your citation. Use the following formats, skipping the Author entry if you can’t find one:[5]
-
MLA: Author <Last, First M>. «Article Title.» Website Title. Version Number. Website Publisher, Date Published. Web. Date Accessed.[6]
- Use «n.p.» if there is no publisher and «n.d.» if there is no publishing date.
-
APA: Author <Last, F>. Article Title. (Date Published). Website Title, Issue/Volume Number, Pages Referenced. Retrieved from <Full URL or DOI>[7]
-
MLA: Author <Last, First M>. «Article Title.» Website Title. Version Number. Website Publisher, Date Published. Web. Date Accessed.[6]
Advertisement
Add New Question
-
Question
How do I find the publisher of an article?
This is usually at the bottom, with a copyright symbol and a year.
-
Question
What can I do if there isn’t an About Page?
Try to find details of an email, then type the email or number into Google and a name might pop up.
-
Question
When looking at the author of a website, how do I know if they are credible?
First, look at the author’s credentials. See if they have any professional experience in the field they’re writing about, and if so, look at what they did, how long they did it, and where they did it. Usually if someone has extensive experience in a particular field or about a particular topic, they are considered credible. Then, do some research about the author. Are they generally considered to be credible or are they completely unheard of? Has that author’s work ever been published in any reputable journals? These questions and answers should help you decide whether or not an author can be considered credible.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
Advertisement
About This Article
Article SummaryX
1. Look at the copyright info.
2. Locate the About or Contact page.
3. Search Google for a portion of text to find the original author.
4. Look up the domain name with WHOIS.
Did this summary help you?
Thanks to all authors for creating a page that has been read 515,136 times.
Is this article up to date?
как узнать кто именно добавил статью на сайт, как отследить автора ?
0
как узнать кто именно добавил статью на сайт, как отследить автора ?
статья есть, а как узнать, кто из юзеров добавил?
Привет!
По его никнейму — Автор — такой-то…
madmax, где можно «увидеть» ник ?
————————————
в админке(Контент сайта), вижу статьи «+1», а где посмотреть ник?
Привет еще раз!
Сайт дико и тупо тормозит — до темы добираюсь минут 20…
Все описывает пост выше:
Пример с своего сайта:
Как сделать Советское знамя!
21-03-2009 (20:20) — Modelist Алексей Лукьянов
Статью добавил — пользователь — Modelist Алексей Лукьянов
Используя этот сайт, вы соглашаетесь с тем, что мы используем файлы cookie.
Текстовый анализатор: распознавание авторства (начало)
Время на прочтение
10 мин
Количество просмотров 8.8K
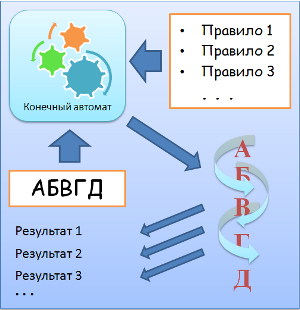
Добрый день, уважаемые хабражители. Я давно хотел опубликовать под GPL-лицензией свой «Текстовый анализатор» ([1]). Наконец, дошли руки. «Текстовый анализатор» — это исследовательский проект, который я разрабатывал три года на 3, 4 и 5-м курсах университета. Главная цель была: создать алгоритм распознавания авторства текста, используя нейросети Хэмминга или Хопфилда. Идея была такова: эти нейросистемы распознают образы, а к задаче распознавания образов можно свести задачу выявления авторства. Для этого необходимо по каждому тексту собрать статистику, и чем больше разных критериев, тем лучше: частотный анализ букв, анализ длин слов/предложений/абзацев, частотный анализ двухбуквенных сочетаний, и так далее. Нейросистема могла бы выявить, характеристики каких текстов наиболее сходны. Работы было — вал. Много кода, хитрые алгоритмы, ООП, паттерны проектирования. Помимо основной задачи я так же реализовал ещё одно ноу-хау: «Карту благозвучия». По задумке, такая карта должна показывать все плохо и хорошо звучащие места, выделяя их цветом. Критерии оценки благозвучия должны задаваться каким-то универсальным образом, например, правилами. Для этой цели я даже разработал специальный графический язык, RRL (Resounding Rules Language). Работы было — вал. Много кода, хитрые алгоритмы, ООП, паттерны проектирования. В итоге получилась большая и сложная программа, правда, с неприглядным интерфейсом. С этим проектом я даже выиграл в конкурсе дипломных работ, получил 1 и 3 места на университетских конференциях, а так же 2 место на международной научно-практической.
Прошло более двух лет, и я с трудом вспоминаю, как оно работает. Давайте вместе попробуем разобраться, что там под
катом
капотом алгоритма, который распознаёт авторство. Ну а карту благозвучия оставим на следующую статью.
(У статьи есть продолжение и окончание.)
Структура статьи:
- Анализ авторства
- Знакомство с кодом
- Внутренности TAuthoringAnalyser и хранение текстов
- Разбиение на уровни конечным автоматом на стратегиях
- Сбор частотных характеристик
- Нейросеть Хэмминга и анализ авторства
Дополнительные материалы:
- Исходники проекта «Текстовый анализатор» (Borland C++ Builder 6.0)
- Тестирование нейросистемы Хэмминга в Excel’е ([xls])
- Таблица переходов для КА, разбивающего текст на уровни ([xls])
- Расчет благозвучия отдельных букв ([xls])
- Презентация дипломного проекта «Текстовый анализатор» ([ppt])
- Презентация проекта «Карта благозвучия» ([ppt])
- Все эти материалы в сжатом виде ([zip], [7z], [rar])
1. Анализ авторства
Нужно:
- загрузить тексты-образцы и «ключевой» текст (авторство которго неизвестно);
- определить сравнимые образцы текстов:
- разбить тексты на слова, предложения, абзацы,
- составить одинаковые по длине блоки из слов, предложений, абзацев для каждого текста,
- выбрать только сравнимые блоки одинаковых размеров для уровней «слова», «предложения», «абзацы»;
- собрать статистику по этим трем уровням;
- загрузить данные в нейросистему Хэмминга;
- провести распознавание образа с её помощью;
- выявить на всех трех уровнях тексты-образцы, которые наиболее близки к ключевому тексту по характеристикам. Вероятно, авторам этих текстов и принадлежит ключевой текст.
Вот какие можно сделать выводы из плана:
- Будет работа с большими объемами данных, вплоть до мегабайтов — в зависимости от текстов.
- Тексты могут быть совсем разных размеров: от рассказов до многотомных романов. Следовательно, нужно как-то обеспечить базовую сравнимость разных произведений.
- Пункт 2 нужен для повышения точности распознавания, для дифференцирования процесса по уровням и для обеспечения базовой сравнимости текстов.
- Разбор текста по словам, предложениям и абзацам — это задача для конечного автомата.
- Статистик разных может быть много, хотелось бы, чтобы они собирались универсальным образом, чтобы всегда можно было добавить ещё какие-нибудь алгоритмы сбора.
- Нейросистема Хэмминга работает только с определенной информацией, а значит, нужно преобразовывать собранные данные к виду, который она понимает.
2. Знакомство с кодом
Для «разогрева» рассмотрим сначала класс главной формы — TAuthoringAnalyserTable ([cpp], [h]). (Если «разогрев» не нужен, можно сразу перейти к следующему разделу.) Сама форма ужасна, юзабилити, можно сказать, на нуле. Но нас интересует код, а не кнопочки-формочки.
В начале cpp-файла видим инстанцированние классов:
Copy Source | Copy HTML
- TVCLControllersFasade VCLFasade; // 1 - фасад по работе с VCL
- TAnalyserControllersFasade AnalyserFasade; // 2 - фасад алгоритмов анализа
- TVCLViewsContainer ViewsContainer; // 3 - контейнер визуальных компонентов

Здесь для (1) и (2) применен паттерн «Фасад» (Facade, [1], [2], [3], [4]). Внутри класса-фасада (1) скрыт большой интерфейс для работы с визуальными компонентами VCL. Именно там прописаны реакции на нажатие кнопок «Загрузить текст», на обновление списка текстов, и вообще на любое событие от формы. Форма обращается к этим функциям, не зная, что произойдет. Фасад скрывает от формы всё лишнее. Но, на самом деле, VCLFasade ([cpp], [h]) только связывает события от форм и алгоритмы; в нем нет этих алгоритмов, а лежат они где-то дальше в другом фасаде — (2), AnalyserFasade ([cpp], [h]). Класс (1) всего лишь перенаправляет вызовы объекту (2) и делает дополнительную работу вроде заполнения визуального компонента «Список». Да, такая вот монструозная конструкция: объект (1) знает об объекте (2) и его функциях. Откуда он знает? В конструкторе главной формы, чуть ниже, есть параметризация первого фасада вторым:
Copy Source | Copy HTML
- // .......
- VCLFasade.SetAnalyserControllersFasade(&AnalyserFasade); // Параметризация одного объекта другим.
- // .......
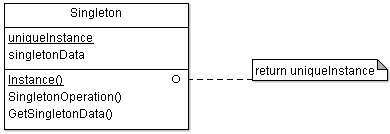
Сейчас я уже не уверен, что класс (1) — это «Фасад», возможно, это что-то другое, или вообще просто так. Хорошо было бы поместить фасады в паттерн «Одиночка» (Singleton, [1], [2], [3], [4]). К сожалению, два года назад я до этого не додумался. Не то чтобы программа пострадала, нет, всё работает, как и должно работать. Но мы теряем некоторые возможности, связанные с паттерном «Одиночка». Ведь мы не можем создавать несколько точек входа в одну подсистему? Не можем. Стоило бы это запретить.
Что ещё есть интересного в конструкторе главной формы?
Copy Source | Copy HTML
- // .......
- VCLFasade.SetViewsContainer(&ViewsContainer); // В фасад (1) передаются контейнер представлений
- VCLFasade.SetAuthoringAnalyserTable(this); // и указатель на главную форму.
- /* Прим.: Можно сделать вывод, что где-то есть циклические включения h-файлов и, <br/>возможно, предопределения. Конечно, это плохо, но вот так вот сложилось тогда. */
- // Параметризация фасада (2) репортинговой системой:
- AnalyserFasade.SetAuthoringAnalysisReporter(&AnalysisReporter);
- AnalyserFasade.SetResoundingAnalysisReporter(&AnalysisReporter);
- // .......
А дальше — большая простыня по заполнению контейнера визуальных компонентов (контролов). С формы берется элемент (например, кнопка) и заносится в контейнер, причем — в свою группу:
Copy Source | Copy HTML
- // .......
- TVCLViewsContainer * vc = &ViewsContainer; // Для сокращения имени.
- vc->AddViewsGroup(cCurrentTextInfo); // Создаём группу компонентов, cCurrentTextInfo - текстовое имя группы.
- vc->AddView(cCurrentTextInfo, LCurrentTextNumber); // LCurrentTextNumber, LCurrentTextAuthor,
- vc->AddView(cCurrentTextInfo, LCurrentTextAuthor); // LCurrentTextTitle и т. д. - это указатели на визуальные компоненты.
- vc->AddView(cCurrentTextInfo, LCurrentTextTitle); // Например: TLabel *LCurrentTextNumber;
- vc->AddView(cCurrentTextInfo, CLBTextsListBox);
- vc->AddView(cCurrentTextInfo, MSelectedTextPreview);
- vc->AddViewsGroup(cKeyTextInfo); // Создаём ещё одну группу.
- vc->AddView(cKeyTextInfo, LKeyTextNumber);
- vc->AddView(cKeyTextInfo, LKeyTextAuthor);
- vc->AddView(cKeyTextInfo, LKeyTextTitle);
- vc->AddView(cKeyTextInfo, CLBTextsListBox);
- // ...и так далее...
Довольно любопытный подход, хотя и не очень понятный. Контролы передаются в контейнер (3), который в свою очередь, передается фасаду (1). Там, очевидно, контролы каким-то образом используются. После рассмотрения классов TVCLViewsContainer ([cpp], [h]) и TVCLView ([h]), становится ясно, что всё, что делается с контролами — это Update, Show/Hide, Enable/Disable, причем группами. Целиком можно обновить одну группу, скрыть другую, зная только имя… Для чего это было нужно, сейчас могу только догадываться. Этот подход нарушает инкапсуляцию, поскольку с контролами можно сделать что угодно, вплоть до удаления. Они выносятся за скобки своей формы, чем рискуют быть измененными.
В классе главной формы больше ничего интересного нет, поэтому посмотрим поближе на класс (2) ([cpp], [h]). Этот второй фасад уже настоящий, без шуток, разве что название записано через S, а не C («Facade» — правильное написание слова, как оно дано везде, в том числе и в GOF ([1], [2], [3])). Класс упрощает работу с подсистемами анализа, скрывая реальные классы за интерфейсами. А реальных классов там три:
Copy Source | Copy HTML
- class TAnalyserControllersFasade
- {
- TTextsController _TextsController;
- TAuthoringAnalyser _AuthoringAnalyser;
- TResoundingMapAnalyser _ResoundingAnalyser;
- // .......
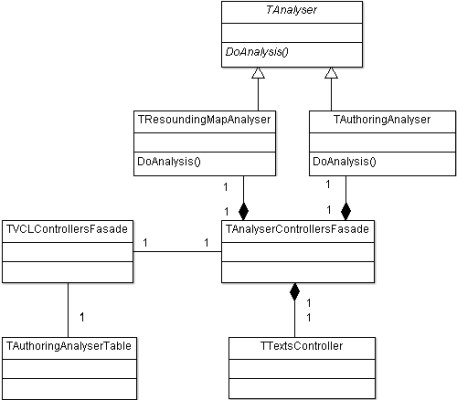
Простые функции класса TAnalyserControllersFasade обращаются к более сложным функциям трех реальных классов, но клиент ничего об этой сложности не знает. Это упрощает разработку и использование. Загружаем тексты (функции LoadAsPrototype(), LoadAsKeyText()), загружаем настройки анализаторов (LoadResoundingAnalysisRules()), запускаем анализ (функция DoAnalysis()), и оно каким-то магическим образом где-то там работает. Если приглядимся к функции DoAnalysis(), то увидим, что нужный анализ вызывается по текстовому имени. Это — хорошо. Плохо то, что в паре с фасадом это не очень расширяемое решение. Если бы я захотел провести еще какой-то анализ, например, проверку грамматики, мне нужно было бы добавить четвертый реальный класс — GrammarAnalyser, — и прописать в фасаде несколько дополнительных функций. А если я пишу суперуниверсальный инструмент для анализа текста, и у меня таких анализаторов — тьма-тьмущая? Тогда бы пришлось придумывать унифицированные интерфейсы, поднимать абстракцию над анализаторами, делать изменяемые в run-time алгоритмы… Получилось бы очень… очень. К счастью, я страдаю чуть меньшей манией гигантизма, да и не требовалось на тот момент.
3. Внутренности TAuthoringAnalyser и хранение текстов
Заглянем в класс TAuthoringAnalyser ([cpp], [h]) — реальный класс, делающий реальный анализ авторства. Уже в самом начале h-файла бросаются в глаза монструозные typedef’s:
Copy Source | Copy HTML
- class TAuthoringAnalyser : public TAnalyser
- {
- public:
- typedef map<TTextString, ParSentWordFSM::TCFCustomUnitDivisionTreeItem, less<TTextString> > TTextsParSentWordTrees;
- typedef map<TUInt, TRangeMapsEqualifer::TEqualifiedMapsContainer, less<TUInt> > TLeveledEqualifiedMaps;
- typedef map<TUInt, TFrequencyTablesContainer, less<TUInt> > TLeveledFrequencyContainers;
- typedef map<TUInt, TTextString, less<TUInt> > TIndexToAliasAssociator;
- typedef map<TUInt, TIndexToAliasAssociator, less<TUInt> > TLeveledIndexToAliasAssociators;
- // <Небезопасный код> // Прим.: чем этот код небезопасен, вспомнить вряд ли удастся...
- typedef map<TUInt, TResultVector, less<TUInt> > TLeveledResultVectors;
- // </Небезопасный код>
- // .......
Эти типы нужны, чтобы хранить все промежуточные данные, вычисления, результаты. Так, TTextsParSentWordTrees содержит, очевидно, структурные деревья текстов: «Весь текст -> абзацы -> предложения -> слова»; TLeveledFrequencyContainers содержит распределенные по уровням частотные характеристики текстов, ну и так далее. Еще можно заметить, что переопределены все встроенные типы ([h]). TUInt == unsigned int, TTextString == AnsiString. Трудно представить, когда бы это могло пригодиться. Переопределенные типы, конечно, можно изменить за мгновение ока, не внося правок в файлы проекта, но как часто возникают подобные ситуации? Когда вдруг оказывается, что 32-битного целого не хватает? Когда внезапно AnsiString перестал нас удовлетворять, и мы захотели std::string? Слишком гипотетическая ситуация, и случается прежде всего с плохо спроектированной программой. Как бы то ни было, типы переопределены, не очень мешают, не очень помогают, — и к этому придётся привыкнуть.
Чуть ниже в защищенной секции нашего анализатора-фасада объявляются объекты этих и других типов:
Copy Source | Copy HTML
- // .......
- private:
- TTextsConfigurator *_AllTextsConfigurator;
- TTextsConfigurator _AnalysedTextsConfigurator;
- TTextsParSentWordTrees _Trees;
- TLeveledEqualifiedMaps _LeveledEqualifiedMaps;
- TLeveledFrequencyContainers _FrequencyContainers;
- TLeveledIndexToAliasAssociators _IndexToAliasAssociators;
- // .......
У класса TTextsConfigurator сложная структура. В его задачи входит загрузка, хранение и предоставление текстов — без их глубокого копирования. Хороша же была бы программа, если бы тексты, передаваясь в параметрах, полностью копировались. Тогда бы не хватило никакой памяти, никакого процессорного времени. Поэтому TTextsConfigurator предоставляет доступ через указатели. Считается, что будучи однажды загруженным, текст становится всегда доступен. «Конфигуратор текстов» так же хранит дополнительную информацию: является ли текст образцом или он — ключевой; активирован текст или нет (в программе можно исключать тексты из анализов), кто автор, какое название, и т.д. Как это реализовано, можно посмотреть в классах TTextsConfigurator ([cpp], [h]), TTextConfiguration ([cpp], [h]) TLogicalTextItem && TMPLogicalTextItem ([h]), TRawDataItem && TMPRawDataItem ([cpp], [h]) и TTextDataProvider ([cpp], [h]). Именно в таком порядке объекты этих классов вкладываются друг в друга, и мы получаем своеобразную матрёшку. Идея была в том, чтобы разделить логическое и физическое представление текста, а так же предоставить возможность загружать «сырые данные» из разных источников, ничего не зная ни об источниках, ни о формате, в котором хранится текст. Поэтому загрузчик «сырых данных» можно сменить. Помимо всего прочего, там используется паттерн «Умный указатель» (классы TMPRawDataItem и TMPLogicalTextItem) в его ипостаси «Master Pointer» ([1], [2]). Так же присутствует иерархия классов, позволяющая абстрагироваться от физического представления текстов. Всё это мне почти не пригодилось; возможно, я сделал лишнюю работу, зато приобрёл массу опыта и положительных эмоций.

Проверка через WHOIS
Контактов или формы обратной связи может и не быть. Поэтому приходится искать их самостоятельно. Хорошо, если есть ссылки на социальные сети или мессенджеры, но что делать, если и их нет?
Самый простой и эффективный способ — воспользоваться так называемыми WHOIS-сервисами. Это бесплатные каталоги, которые содержат информацию о владельце домена. Эта информация может быть как закрытой, так и открытой для общего доступа.
Популярные сервисы:
Если информация закрыта, то вы не увидите фамилии владельца, в этой графе будет написано «Частное лицо» (Private Person). Но, скорее всего, возможность связаться все же будет.
Во-первых, через сервис, на котором был зарегистрирован домен. Как правило, среди прочей информации можно найти и ссылку на форму обратной связи через регистратора доменных имен. Можно и самостоятельно перейти на сайт регистратора и вбить нужный домен.

Во-вторых, может быть оставлен адрес электронной почты в обычном или зашифрованном виде. В последнем случае это ничуть не помешает отправить письмо, однако вы не будете знать реального адреса владельца.
Если владелец компания, то все может быть еще проще. У компаний обычно есть официальные сайты или странички в соцсетях, где контактная информация должна быть наверняка. Кроме того, о компании можно узнать подробнее, набрав в поиске ее название. Никогда не знаешь, что в итоге всплывет.
Поиск обратных ссылок
Владельцы небольших сайтов часто пытаются раскрутить их, размещая ссылки на форумах, социальных сетях или других сайтах. Таким образом, можно найти контакты владельца или хотя бы человека, связанного с сайтом.
Искать обратные ссылки можно через специальные сервисы, например ahrefs.com.

Стоит отметить, что ссылки могут появляться и естественным образом, иначе говоря, тот, кто дал ссылку, не обязательно имеет отношение к сайту. А вот если она стоит в профиле или на странице в соцсети, то это почти наверняка нужный вам человек.
Поиск файлов
Файлы, которые владелец выкладывает на своем сайте, тоже могут рассказать довольно много о его личности. Попробуйте поискать на сайте файлы определенного типа через поисковик. Делается это просто. В строке поиска наберите filetype: doc site: site.ru, где вместо site.ru укажите адрес нужного сайта. Возможно, вы найдете документы, которые выкладывал автор. Такие текстовые файлы обычно содержат контактную информацию: реальное имя и фамилию или ник.

Чтобы увидеть эту информацию, нужно кликнуть на файле правой кнопкой мыши и выбрать свойства
Также можно узнать некоторые сведения и из фотографий. Если автор загружает фото в необработанном виде, то можно прочитать exif-данные. С этим справится Jeffrey’s Image Metadata Viewer. Кроме того, можно попробовать найти человека по лицу. Для этого отлично подойдет поиск «Яндекса» по картинкам (Google ищет заметно хуже) или сервис findclone.ru.

Сервис findclone требует регистрации
Это тоже интересно:
Очередной мануал для начинающих разведчиков.
Информация о владельце домена является конфиденциальной и предоставляется регистратором только по запросу органов власти. Но есть несколько возможных способов выведать ее. О них и расскажем в этой статье.
Зачем это нужно: найти управу на человека, который нагло ворует ваш контент, оценить платежеспособность владельца сайта перед тем как сделать ему предложение о покупке, найти специалиста в узкой области, который пишет для своего блога толковые статьи, но подписывается обезличенным никнейном и т.п.
1. Смотрим историю whois
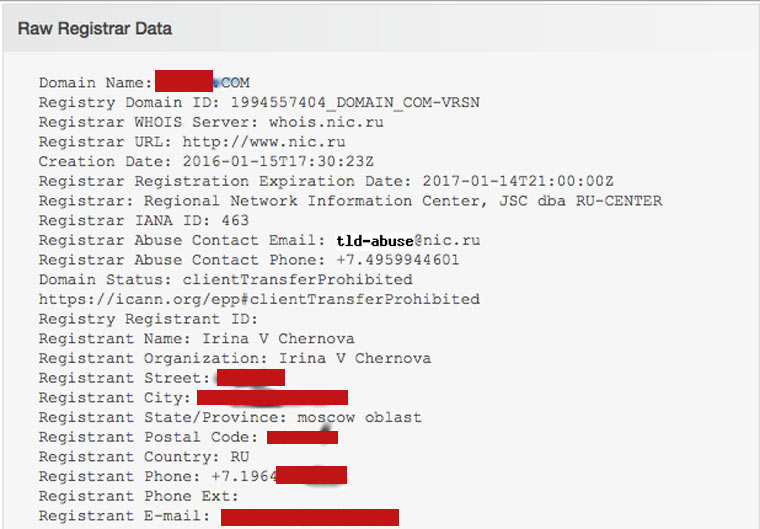
Начать стоит с проверки сайта на who.is. На скрине показан пример, когда c помощью этого сервиса стал известен не только email, но также мобильный телефон и адрес владельца (такое бывает, если очень повезет). Я в шоке от политики приватности своего хостера! В большинстве случаев отображается только ссылка, по которой можно отправить сообщение владельцу домена через регистратора. И с ее помощью есть шанс узнать много интересного.
2. Пытаемся связаться с ним официальным способом
Отправив сообщение через регистратора, можно выведать действующий email человека, его фамилию/имя, контактный телефон и IP-адрес, которые помогут полностью идентифицировать его личность (см. статью 15 фишек для сбора информации о человеке в интернете).
Результат зависит от удачи. Неизвестно проверяет ли человек ту почту, которую указал при регистрации домена и насколько достоверные предоставлены им данные. Также важны ваши навыки социнженерии. Можно предлагать инвестиции, представляться ассистентом Юрия Мильнера:-), убеждать что нужно непременно созвониться по телефону или скайпу, спросить о возможности личной встречи. Главное убедить человека, что судьба подкинула ему реальный шанс заработать и выпросить максимум данных, которые можно применить в дальнейшей разведке.
Желательно добавить фразу: «Пожалуйста, дайте мне знать, что предложение вам не интересно». Это увеличивает шанс того, что человек из вежливости черкнет пару строк, засветив свою почту, имя и IP-адрес.
Также стоит написать всем предыдущим владельцам домена, с просьбой дать контакты тех людей, которым они передали его. Если повезет, то в ответе будет: «Продал Васе N, его телефон +791612345…». Но, к сожалению, люди часто бывают скрытны. Но также часто бывают вежливы и отписываются: «Простите, но я не могу поделиться этой информацией». И это уже нам на руку.
Зная электронную почту бывшего владельца (и его никнейм), можно найти его объявление о продаже сайта/домена на специализированном форуме и список пользователей, которые на него откликнулись. Из них можно составить круг возможных нынешних владельцев домена.
3. Ищем сайты, зарегистрированные на имя владельца
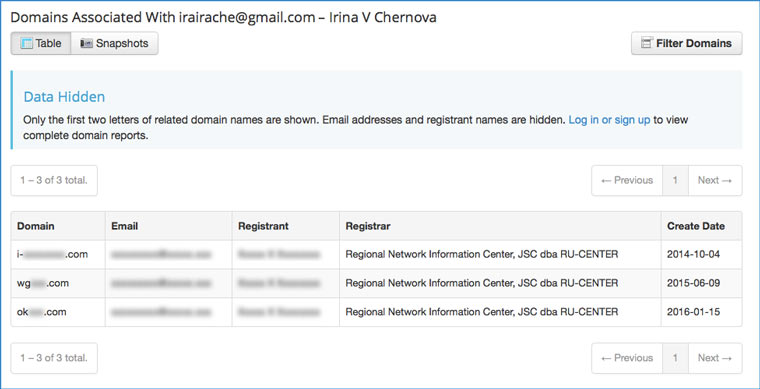
Зная адрес электронной почты человека, можно узнать, какие домены на него зарегистрированы. Сделать это можно на domainiq.com. Не исключено, что одним из этих сайтов окажется личный блог, по которому можно установить личность человека.
4. Обращаемся к хостеру
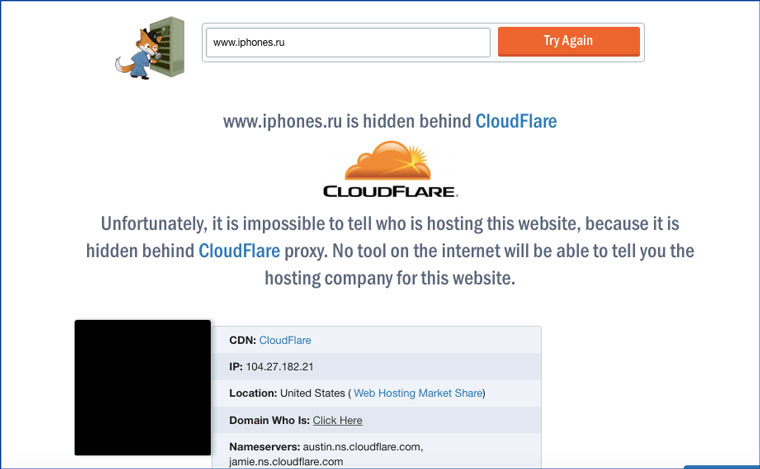
На hostadvice.com можно узнать хостинг-провайдера сайта. Если вы сможете письменно обосновать необходимость предоставления вам данных о владельце, то есть шанс, что хостер поделится ими с вами. Или будет очень упорны (недели настойчивых писем должно хватить).
Обращаясь к кому-то из сферы IT по интернету лучше представляться женщиной (и ставить в профиль скромное фото со светлыми волосами). Неопытные мужчины думают, что блондинки недалеки, не представляют никакой опасности и с радостью оказывают им мелкие услуги.
5. Смотрим информацию о создателях файлов
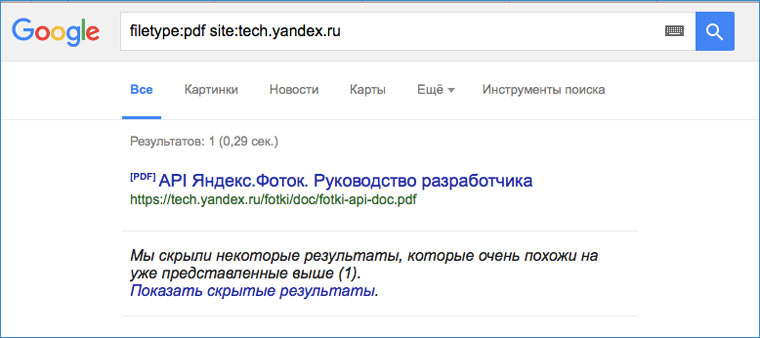
Google умеет искать не только по html-страницам, но и по разным типам файлов. Вот пример запроса для поиска пдфок на определенном сайте: filetype:pdf site:tech.yandex.ru
Найденные на сайте файлы нужно скачать на компьютер и в свойствах посмотреть их автора, создателя и т.п. Очень многие люди в информации о компьютере указывают свои реальные имя и фамилию, а при выкладке файлов со своей машины в интернете забывают стереть эту информацию.
Google умеет искать файлы со следующими расширениями:
- doc;
- ppt;
- xls;
- pdf;
- rtf;
- swf.
6. Ищем «полезные» файлы в robots.txt
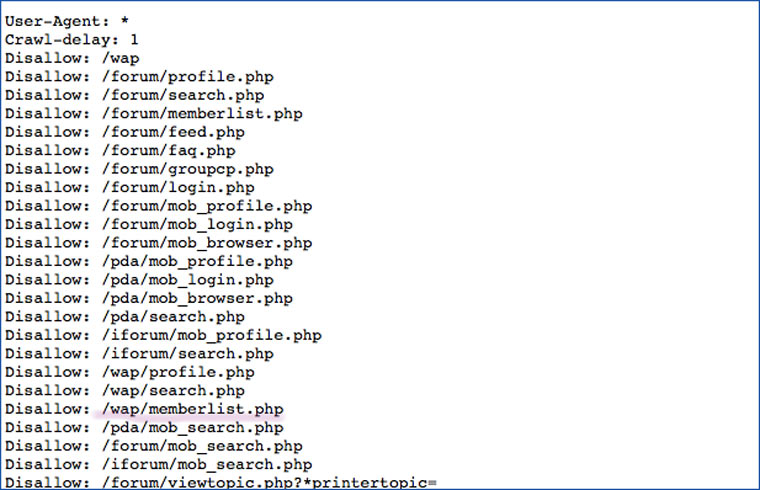
В этом файле владельцы указывают файлы и папки, которые они закрывают от индексации поисковиками. Иногда там могут быть указаны старые страницы с личными данными или фотографиями. Мой опыт показывает, что есть определенная категория людей, которые использует свои сервера в качестве облачного хранилища и кладут туда что попало. Как правило, файл robots.txt лежит в корневом каталоге сайта.
7. Ищем «полезные» страницы в sitemap.xml
В файле с картой сайта: sitemap.xml, который часто располагается в той же папке, что и robots.txt также можно найти страницы, которые могут содержать полезную информацию. К примеру, страницу с контактами, ссылка на которую была убрана с главной страницы.
8. Ищем почтовые адреса, связанные с доменом
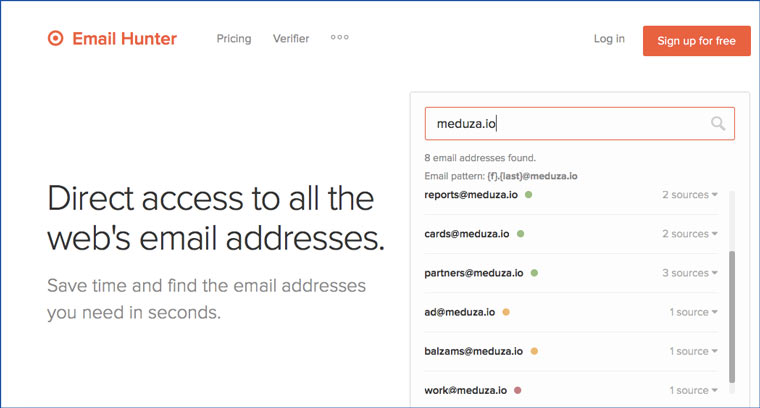
Указываем адрес сайта на emailhunter.co и получаем список адресов, связанных с ним.
9. Ищем сайты, которые ссылаются на домен
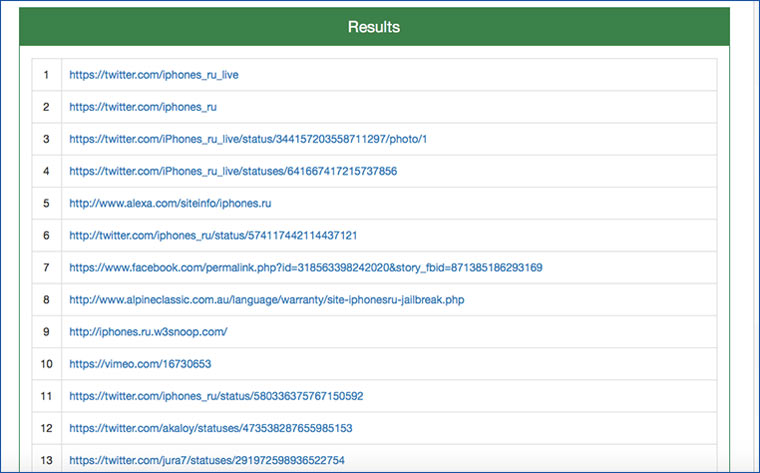
Указываем сайт в форму поиска на Backlink Checker и получаем 50 ссылок на страницы, которые ссылаются на него. Есть шанс отыскать среди них профили в соцсетях, а также другие проекты владельца ресурса.
10. Проверяем exif-данные фотографий
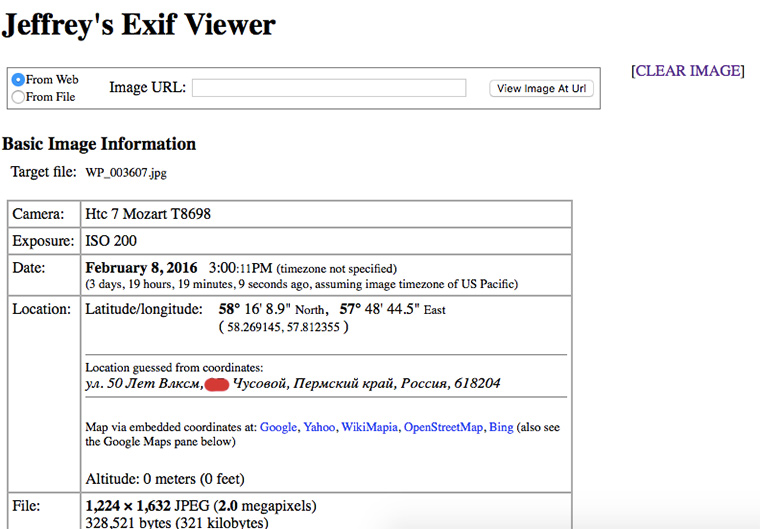
Иногда люди выкладывают на свои сайты фотографий без их предварительной оптимизации для веба. Можно попробовать посмотреть пару снимков с помощью Jeffry’s Exif Viewer. Таким образом можно узнать адрес владельца и модель его мобильного телефона.
11. Идентифицируем владельца по лицу
Если сайт небольшой, то можно с помощью поиска Google по картинкам и оператора site: посмотреть все изображения которые есть на нем. Не исключено, что среди них может быть его фотография (какой-нибудь admin.jpg пятилетней давности). Личность человека по фото можно установить с помощью findface.ru.
12. Читаем комментарии в исходном коде
Заходим на сайт, нажимаем Shift + Command + U (или выбираем из меню пункт Показать программный код страницы). Сначала просматриваем HTML-код на предмет палевных комментов с именами и никнеймами. К примеру: «BigFatNagibator, проверь это место пожалуйста!». Попутно ищем js-скрипты, которые были написаны владельцем сайта специально для этого ресурса. Не исключено, что в них может оказаться торжественная надпись «Created by Sasha Petrov. Irkutsk» и ссылка на его профиль в Github.
Результативность всех этих методов зависит большой частью от вашего упорства и смекалки. Если владелец сайта не конченый параноик и живет онлайн-жизнью, то обязательно должна быть ниточка, которая поможет найти его.
Если вам не нужно никого искать, но у вас есть проект, владение которым вы хотели бы скрыть, то рекомендую проверить по всем пунктам из статьи степень сложности идентификации своей личности. Может, будете удивлены.

 (25 голосов, общий рейтинг: 4.88 из 5)
(25 голосов, общий рейтинг: 4.88 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Очередной мануал для начинающих разведчиков. Информация о владельце домена является конфиденциальной и предоставляется регистратором только по запросу органов власти. Но есть несколько возможных способов выведать ее. О них и расскажем в этой статье. Зачем это нужно: найти управу на человека, который нагло ворует ваш контент, оценить платежеспособность владельца сайта перед тем как сделать ему предложение…
- Безопасность,
- Подборки,
- сеть,
- хаки
![]()