Написание парсера с нуля: так ли страшен черт?
Время на прочтение
12 мин
Количество просмотров 91K
В прошлом топике я рассказывал о том, как мы с другом решили ради развлечения написать свой встраиваемый язык программирования для платформы .NET. У первой версии был серьезный недостаток — парсер был реализован на F# с помощью сторонней библиотеки. Из-за этого требовалась куча зависимостей, парсер работал медленно, а поддержка его была крайне муторным занятием.
Очевидно, что парсер нужно было переписать на C#, но при мысли о написании парсера с нуля вдруг находилась дюжина других срочных дел. Таким образом таск перекидывался и откладывался практически полгода и казался непосильным, а в итоге был сделан за 4 дня. Под катом я расскажу об удобном способе, позволившим реализовать парсер достаточно сложной грамматики без использования сторонних библиотек и не тронуться умом, а также о том, как это позволило улучшить язык LENS.
Но обо всем по порядку.
Первый блин
Как было сказано выше, в качестве ядра парсера мы использовали библиотеку FParsec. Причины данного выбора скорее исторические, нежели объективные: понравился легковесный синтаксис, хотелось поупражняться в использовании F#, и автор библиотеки очень оперативно отвечал на несколько вопросов по email.
Главным недостатком этой библиотеки для нашего проекта оказались внешние зависимости:
- Примерно десятимегабайтный F# Runtime
- 450 кб сборок самого FParsec
Кроме того, сам компилятор разбился на 3 сборки: парсер, синтаксическое дерево и точку входа. Сборка парсера занимала внушительные 130 кб. Для встраиваемого языка это абсолютно неприлично.
Другой проблемой было отображение ошибок. Лаконичная запись грамматики на местном DSL при некорректно введенной программе выдавала нечитаемую ошибку c перечислением ожидаемых лексем:
> let x =
> Ошибка: ожидается идентификатор
или число
или скобка
или вызов функции
или 'new'
или ...
Хотя кастомная обработка ошибок и возможна, DSL для нее явно не предназначен. Описание грамматики уродливо распухает и становится абсолютно неподдерживаемым.
Еще одним неприятным моментом была скорость работы. При «холодном старте» компиляция любого, даже самого простого скрипта занимала на моей машине примерно 350-380 миллисекунд. Судя по тому, что повторный запуск такого же скрипта занимал уже всего-то 5-10 миллисекунд, задержка была вызвана JIT-компиляцией.
Сразу оговорюсь — для большинства реальных задач время разработки куда критичнее, чем пара дополнительных библиотек или сотни миллисекунд, которые тратятся на разбор. С этой точки зрения написание рукопашного парсера является скорее учебным или эзотерическим упражнением.
Немного теории
Сферический парсер в вакууме представляет собой функцию, которая принимает исходный код, а возвращает некое промежуточное представление, по которому удобно будет сгенерировать код для используемой виртуальной машины или процессора. Чаще всего это представление имеет древовидную структуру и называется абстрактным синтаксическим деревом — АСД (в иностранной литературе — abstract syntactic tree, AST).
Древовидная структура особенно хороша тем, что ее обход в глубину отлично сочетается со стековой организацией, используемой во многих современных виртуальных машинах (например, JVM или .NET). Генерация кода в данной статье рассматриваться не будет, однако элементы синтаксического дерева, как результат работы парсера, будут время от времени упоминаться.
Итак, на входе мы имеем строку. Набор символов. Работать с ней в таком виде напрямую не слишком удобно — приходится учитывать пробелы, переносы строк и комментарии. Для упрощения себе жизни разработчики парсеров обычно разделяют разбор на несколько проходов, каждый из которых выполняет какую-то одну простую задачу и передает результат своей работы следующему:
- Лексический анализатор:
string -> IEnumerable<Lexem> - Синтаксический анализатор:
IEnumerable<Lexem> -> IEnumerable<Node> - Семантический анализатор:
IEnumerable<Node> -> ?
Поскольку семантический анализатор — штука сугубо индивидуальная, ее описание в данную статью не входит. Тем не менее, я поделюсь некоторыми полезными приемами для первых двух анализаторов.
Лексический анализатор
Требования:
- Скорость работы
- Легкость расширения
- Простота реализации
- Отслеживание положения в исходном тексте
Алгоритм лексера прост: он сканирует строку слева направо, пытаясь сопоставить текущее положение в строке с каждой известной ему лексемой. При удачном сопоставлении лексер сдвигается по строке направо на столько символов, сколько заняла предыдущая лексема, и продолжает поиск по новой до конца строки. Пробелы, табуляции и переводы строки для большинства грамматик можно просто игнорировать.
Все лексемы изначально стоит поделить на 2 типа — статические и динамические. К первым относятся те лексемы, которые можно выразить обычной строкой — ключевые слова и операторы. Лексемы типа идентификаторов, чисел или строк проще описать регулярным выражением.
Статические лексемы, в свою очередь, есть резон поделить на операторы и ключевые слова. Ключевые слова сопоставляются только в том случае, если следующий за ними символ не является допустимым для идентификатора (или дальше — конец строки). В противном случае возникнут проблемы с идентификаторами, чье начало совпадает с ключевым словом: например, "information" -> keyword(in), keyword(for), identifier(mation).
Пример реализации
enum LexemKind
{
Var,
Print,
Plus,
Minus,
Multiply,
Divide,
Assign,
Semicolon,
Identifier,
Number
}
class LocationEntity
{
public int Offset;
public int Length;
}
class Lexem : LocationEntity
{
public LexemKind Kind;
public string Value;
}
class LexemDefinition<T>
{
public LexemKind Kind { get; protected set; }
public T Representation { get; protected set; }
}
class StaticLexemDefinition : LexemDefinition<string>
{
public bool IsKeyword;
public StaticLexemDefinition(string rep, LexemKind kind, bool isKeyword = false)
{
Representation = rep;
Kind = kind;
IsKeyword = isKeyword;
}
}
class DynamicLexemDefinition : LexemDefinition<Regex>
{
public DynamicLexemDefinition(string rep, LexemKind kind)
{
Representation = new Regex(@"G" + rep, RegexOptions.Compiled);
Kind = kind;
}
}
static class LexemDefinitions
{
public static StaticLexemDefinition[] Statics = new []
{
new StaticLexemDefinition("var", LexemKind.Var, true),
new StaticLexemDefinition("print", LexemKind.Print, true),
new StaticLexemDefinition("=", LexemKind.Assign),
new StaticLexemDefinition("+", LexemKind.Plus),
new StaticLexemDefinition("-", LexemKind.Minus),
new StaticLexemDefinition("*", LexemKind.Multiply),
new StaticLexemDefinition("/", LexemKind.Divide),
new StaticLexemDefinition(";", LexemKind.Semicolon),
};
public static DynamicLexemDefinition[] Dynamics = new []
{
new DynamicLexemDefinition("[a-zA-Z_][a-zA-Z0-9_]*", LexemKind.Identifier),
new DynamicLexemDefinition("(0|[1-9][0-9]*)", LexemKind.Number),
};
}
class Lexer
{
private char[] SpaceChars = new [] { ' ', 'n', 'r', 't' };
private string Source;
private int Offset;
public IEnumerable<Lexem> Lexems { get; private set; }
public Lexer(string src)
{
Source = src;
Parse();
}
private void Parse()
{
var lexems = new List<Lexem>();
while(InBounds())
{
SkipSpaces();
if(!InBounds()) break;
var lex = ProcessStatic() ?? ProcessDynamic();
if(lex == null)
throw new Exception(string.Format("Unknown lexem at {0}", Offset));
lexems.Add(lex);
}
Lexems = lexems;
}
private void SkipSpaces()
{
while(InBounds() && Source[Offset].IsAnyOf(SpaceChars))
Offset++;
}
private Lexem ProcessStatic()
{
foreach(var def in LexemDefinitions.Statics)
{
var rep = def.Representation;
var len = rep.Length;
if(Offset + len > Source.Length || Source.Substring(Offset, len) != rep)
continue;
if(Offset + len < Source.Length && def.IsKeyword)
{
var nextChar = Source[Offset + len];
if(nextChar == '_' || char.IsLetterOrDigit(nextChar))
continue;
}
Offset += len;
return new Lexem { Kind = def.Kind, Offset = Offset, Length = len };
}
return null;
}
private Lexem ProcessDynamic()
{
foreach(var def in LexemDefinitions.Dynamics)
{
var match = def.Representation.Match(Source, Offset);
if(!match.Success)
continue;
Offset += match.Length;
return new Lexem { Kind = def.Kind, Offset = Offset, Length = match.Length, Value = match.Value };
}
return null;
}
private bool InBounds()
{
return Offset < Source.Length;
}
}
Преимущества:
- Работает быстро
- Элементарное устройство, можно написать за полчаса
- Новые лексемы добавляются очень просто
- Способ подходит для множества грамматик
Недостатки:
- Танцы с бубном при разборе языка со значимыми пробелами
- Порядок объявления лексем важен: желательно сортировать по длине
Синтаксический анализатор
Требования:
- Легкость расширения при изменении грамматики
- Возможность описывать подробные сообщения об ошибках
- Возможность заглядывать вперед на неограниченное количество позиций
- Автоматическое отслеживание положения в исходном коде
- Лаконичность, близость к исходной грамматике
Для того, чтобы упростить себе жизнь при написании парсера, следует оформить грамматику специальным образом. Никаких сложных конструкций! Все правила можно поделить на 3 типа:
- Описание — один конкретный узел:
(var_expr = "var" identifier "=" expr) - Повторение — один конкретный узел повторяется многократно, возможно с разделителем:
main = { stmt ";" } - Альтернатива — выбор из нескольких узлов
(stmt = var_expr | print_expr | assign_expr | other)
Правило-описание разбирается по шагам: проверили тип текущей лексемы, сдвинулись на следующую, и так до конца правила. С каждой проверенной лексемой можно сделать некоторое действие: выдать подробную ошибку в случае несовпадения, сохранить ее значение в узле и т.д.
Правило-перечисление — это цикл. Чтобы вернуть последовательность значений, в C# есть очень удобный функционал для создания генераторов с помощью yield return.
Правило-альтернатива по очереди вызывает правила-варианты с помощью специальной обертки, которая позволяет откатиться в исходное состояние. Правила просто вызываются по порядку, пока хотя бы одно из них не совпадет, связанные оператором coalesce (??).
Тут пытливый читатель спросит:
— Как это, просто вызываются по порядку? А как же опережающие проверки? Например, так:
if(CurrentLexem.Type == LexemType.Var) return parseVar();
if(CurrentLexem.Type == LexemType.For) return parseFor();
...
Признаюсь, свой первый серьезный парсер я написал именно так. Однако это плохая идея!
Во-первых, заглянуть можно только на фиксированное число символов. Для всяких for или var, конечно, подойдет. Но, допустим, у нас есть такие правила в грамматике:
assign = id_assign | member_assign | index_assign
id_assign = identifier "=" expr
member_assign = lvalue "." identifier "=" expr
index_assign = lvalue "[" expr "]" "=" expr
Если с id_assign еще все понятно, то оба других правила начинаются с нетерминала lvalue, под которым может скрываться километровое выражение. Очевидно, что никаких опережающих проверок тут не напасешься.
Другая проблема — смешение зон ответственности. Чтобы грамматика была расширяемой, правила должны быть как можно более независимы друг от друга. Данный подход требует, чтобы внешнее правило знало о составе внутренних, что увеличивает связность и осложняет поддержку при изменении грамматики.
Так зачем нам вообще опережающие проверки? Пусть каждое правило само знает о том, насколько далеко нужно заглянуть вперед, чтобы убедиться, что именно оно наиболее подходящее.
Рассмотрим на примере выше. Допустим, у нас есть текст: a.1 = 2:
- Первой вызывается альтернатива
id_assign. - Идентификатор
aуспешно совпадает. - Дальше идет точка, а ожидается знак «равно». Однако с идентификатора могут начинаться и другие правила, поэтому ошибка не выбрасывается.
- Правило assign откатывает состояние назад и пробует дальше.
- Вызывается альтернатива
member_assign. - Идентификатор и точка успешно совпадают. В грамматике нет других правил, которые начинаются с идентификатора и точки, поэтому дальнейшие ошибки не имеет смысл пытаться обработать откатыванием состояния.
- Число
1не является идентификатором, поэтому выкидывается ошибка.
Сначала напишем несколько полезных методов:
Скрытый текст
partial class Parser
{
private List<Lexem> Lexems;
private int LexemId;
#region Lexem handlers
[DebuggerStepThrough]
private bool Peek(params LexemType[] types)
{
var id = Math.Min(LexemId, Lexems.Length - 1);
var lex = Lexems[id];
return lex.Type.IsAnyOf(types);
}
[DebuggerStepThrough]
private Lexem Ensure(LexemType type, string msg, params object[] args)
{
var lex = Lexems[LexemId];
if(lex.Type != type)
error(msg, args);
Skip();
return lex;
}
[DebuggerStepThrough]
private bool Check(LexemType lexem)
{
var lex = Lexems[LexemId];
if (lex.Type != lexem)
return false;
Skip();
return true;
}
[DebuggerStepThrough]
private void Skip(int count = 1)
{
LexemId = Math.Min(LexemId + count, Lexems.Length - 1);
}
#endregion
#region Node handlers
[DebuggerStepThrough]
private T Attempt<T>(Func<T> getter) where T : LocationEntity
{
var backup = LexemId;
var result = Bind(getter);
if (result == null)
LexemId = backup;
return result;
}
[DebuggerStepThrough]
private T Ensure<T>(Func<T> getter, string msg) where T : LocationEntity
{
var result = Bind(getter);
if (result == null)
throw new Exception(msg);
return result;
}
[DebuggerStepThrough]
private T Bind<T>(Func<T> getter) where T : LocationEntity
{
var startId = LexemId;
var start = Lexems[LexemId];
var result = getter();
if (result != null)
{
result.StartLocation = start.StartLocation;
var endId = LexemId;
if (endId > startId && endId > 0)
result.EndLocation = Lexems[LexemId - 1].EndLocation;
}
return result;
}
#endregion
}
С их помощью реализация приведенной выше грамматики становится практически тривиальной:
partial class Parser
{
public Node ParseAssign()
{
return Attempt(ParseIdAssign)
?? Attempt(ParseMemberAssign)
?? Ensure(ParseIndexAssign, "Неизвестный тип выражения!");
}
public Node ParseIdAssign()
{
var id = TryGetValue(LexemType.Identifier);
if (id == null) return null;
if (!Check(LexemType.Assign)) return null;
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new IdAssignNode { Identifier = id, Expression = expr };
}
public Node ParseMemberAssign()
{
var lvalue = Attempt(ParseLvalue);
if (lvalue == null) return null;
if (!Check(LexemType.Dot)) return null;
var member = TryGetValue(LexemType.Identifier);
if (member == null) return null;
if (!Check(LexemType.Assign)) return null;
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new MemberAssignNode { Lvalue = lvalue, MemberName = member, Expression = expr };
}
public Node ParseIndexAssign()
{
var lvalue = Attempt(ParseLvalue);
if (lvalue == null) return null;
if (!Check(LexemType.SquareBraceOpen)) return null;
var index = Ensure(ParseExpr, "Ожидается выражение индекса!");
Ensure(LexemType.SquareBraceClose, "Не закрыта скобка!");
Ensure(LexemType.Assign, "Ожидается знак присваивания!");
var expr = Ensure(ParseExpr, "Ожидается присваиваемое выражение!");
return new IndexAssignNode { Lvalue = lvalue, Index = index, Expression = expr };
}
}
Атрибут DebuggerStepThrough сильно помогает при отладке. Поскольку все вызовы вложенных правил так или иначе проходят через Attempt и Ensure, без этого атрибута они будут постоянно бросаться в глаза при Step Into и забивать стек вызовов.
Преимущества данного метода:
- Откат состояния — очень дешевая операция
- Легко управлять тем, до куда можно откатываться
- Легко отображать детальные сообщения об ошибках
- Не требуются никакие внешние библиотеки
- Небольшой объем генерируемого кода
Недостатки:
- Реализация парсера вручную занимает время
- Сложность написания и оптимальность работы зависят от качества грамматики
- Леворекурсивные грамматики следует разруливать самостоятельно
Операторы и приоритеты
Неоднократно я видел в описаниях грамматик примерно следующие правила, показывающие приоритет операций:
expr = expr_1 { op_1 expr_1 }
expr_1 = exp2_2 { op_2 expr_2 }
expr_2 = exp2_3 { op_3 expr_3 }
expr_3 = int | float | identifier
op_1 = "+" | "-"
op_2 = "*" | "/" | "%"
op_3 = "**"
Теперь представим, что у нас есть еще булевы операторы, операторы сравнения, операторы сдвига, бинарные операторы, или какие-нибудь собственные. Сколько правил получается, и сколько всего придется поменять, если вдруг придется добавить новый оператор с приоритетом где-то в середине?
Вместо этого, можно убрать из грамматики вообще все описание приоритетов и закодить его декларативно.
Пример реализации
expr = sub_expr { op sub_expr }
sub_expr = int | float | identifier
partial class Parser
{
private static List<Dictionary<LexemType, Func<Node, Node, Node>>> Priorities =
new List<Dictionary<LexemType, Func<Node, Node, Node>>>
{
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Plus, (a, b) => new AddNode(a, b) },
{ LexemType.Minus, (a, b) => new SubtractNode(a, b) }
},
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Divide, (a, b) => new DivideNode(a, b) },
{ LexemType.Multiply, (a, b) => new MultiplyNode(a, b) },
{ LexemType.Remainder, (a, b) => new RemainderNode(a, b) }
},
new Dictionary<LexemType, Func<Node, Node, Node>>
{
{ LexemType.Power, (a, b) => new PowerNode(a, b) }
},
};
public NodeBase ProcessOperators(Func<Node> next, int priority = 0)
{
if (priority == Priorities.Count)
return getter();
var node = ProcessOperators(next, priority + 1);
var ops = Priorities[priority];
while (Lexems[LexemId].IsAnyOf(ops.Keys))
{
foreach (var curr in ops)
{
if (check(curr.Key))
{
node = curr.Value(
node,
ensure(() => ProcessOperators(next, priority + 1), "Ожидается выражение!")
);
}
}
}
return node;
}
}
Теперь для добавления нового оператора необходимо лишь дописать соответствующую строчку в инициализацию списка приоритетов.
Добавление поддержки унарных префиксных операторов оставляю в качестве тренировки для особо любопытных.
Что нам это дало?
Написанный вручную парсер, как ни странно, стало гораздо легче поддерживать. Добавил правило в грамматику, нашел соответствующее место в коде, дописал его использование. Backtracking hell, который частенько возникал при добавлении нового правила в старом парсере и вызывал внезапное падение целой кучи на первый взгляд не связанных тестов, остался в прошлом.
Итого, сравнительная таблица результатов:
| Параметр | FParsec Parser | Pure C# |
| Время парсинга при 1 прогоне | 220 ms | 90 ms |
| Время парсинга при дальнейших прогонах | 5 ms | 6 ms |
| Размер требуемых библиотек | 800 KB + F# Runtime | 260 KB |
Скорее всего, возможно провести оптимизации и выжать из синтаксического анализатора больше производительности, но пока и этот результат вполне устраивает.
Избавившись от головной боли с изменениями в грамматике, мы смогли запилить в LENS несколько приятных вещей:
Цикл for
Используется как для обхода последовательностей, так и для диапазонов:
var data = new [1; 2; 3; 4; 5]
for x in data do
println "value = {0}" x
for x in 1..5 do
println "square = {0}" x
Композиция функций
С помощью оператора :> можно создавать новые функции, «нанизывая» существующие:
let invConcat = (a:string b:string) -> b + a
let invParse = incConcat :> int::Parse
invParse "37" "13" // 1337
Частичное применение возможно с помощью анонимных функций:
fun add:int (x:int y:int) -> x + y
let addTwo = int::TryParse<string> :> (x:int -> add 2 x)
addTwo "40" // 42
Улучшения синтаксиса
- Однострочные комментарии:
somecode () // comment - Неинициализированные переменные:
var x : int - Скобки вокруг единственного аргумента лямбды опциональны:
var inc = x:int -> x + 1 - Скобки в управляющих конструкциях убраны:
if x then a () else b () while a < b do println "a = {0}" a a = a + 1 - Появился блок
try/finally - Скобки при передаче индекса или поля в функцию опциональны:
print "{0} = {1}" a[1] SomeType::b
Проект хоть и медленно, но развивается. Осталось еще много интересных задач. На следующую версию планируется:
- Объявление generic-типов и функций
- Возможность пометить функции или типы атрибутами
- Поддержку событий
Также можно скачать собранные демки под Windows.
#статьи
- 13 май 2022
-

0
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.
Иллюстрация: Node.js / Colowgee для Skillbox Media

Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.

На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида «https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида «https://jrnlst.ru/?page=[номер страницы]», которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с «page=200» (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом «block-views-articles-latest-on-front-block» → первый элемент с классом «view-content» → все элементы с классом «flex-teaser-square» (по очереди) → в каждом из них первый элемент с классом «views-field views-field-title» → в каждом из них первый элемент с тегом ‘a’ (то есть гиперссылка с названием статьи).
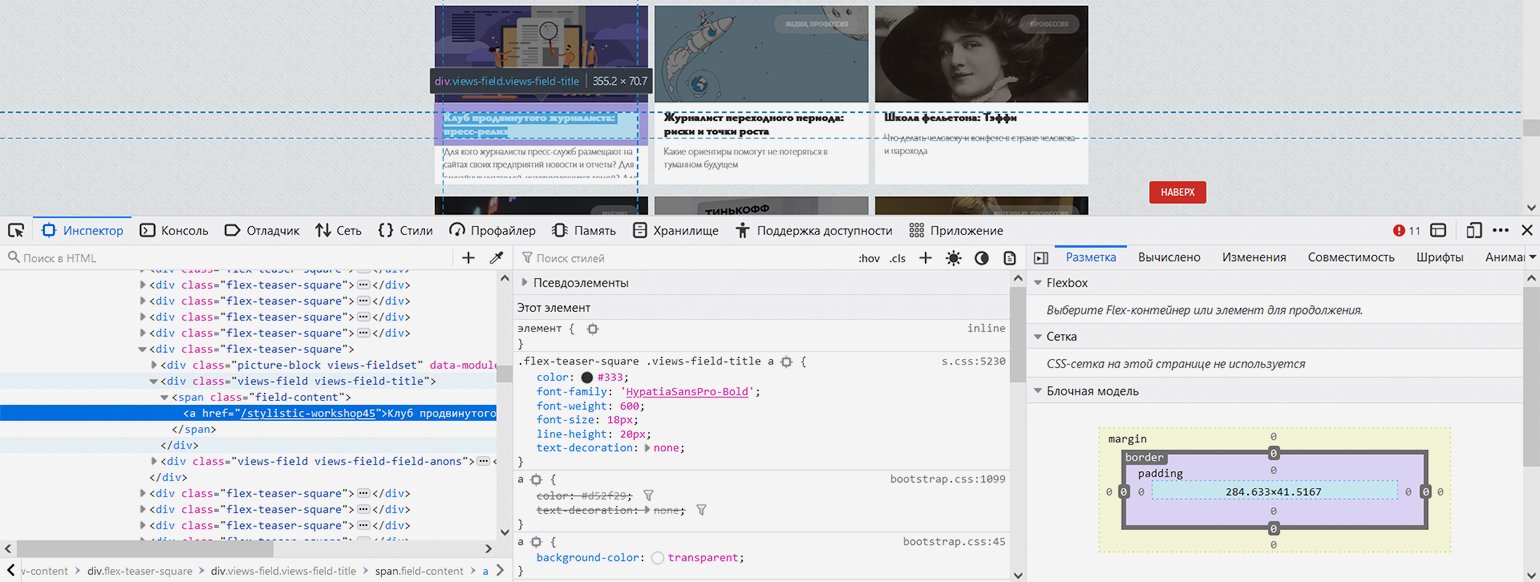
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
cd "D:ваш_путьJJ Articles Parser" node JJ_articles_parser.js pause
Здесь всё просто:
- Первая строка — командой cd переходим в нужные диск и папку.
- Вторая строка запускает интерпретатор Node.js и тут же передаёт ему в обработку наш JS-файл.
- Команда pause делает так, чтобы командная строка не выключалась после выполнения кода.
Теперь займёмся кодом самого парсера:
/* Парсер статей журнала «Журналист» (https://jrnlst.ru) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключение модуля axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 162; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице до 18 статей const baseLink = 'https://jrnlst.ru/?page='; // Типовая ссылка на страницу со статьями (без номера в конце) var page = 0; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) function paginator() { function getArticles() { var link = baseLink + page; // Конструктор ссылки на страницу со статьями для запроса по ней console.log('Запрос статей по ссылке: ' + link); // Уведомление о получившейся ссылке // Запрос к странице сайта axios.get(link) .then(response => { var currentPage = response.data; // Запись полученного результата const dom = new JSDOM(currentPage); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Определение количества ссылок на странице, потому что оно у них не всегда фиксированное. Это значение понадобится в цикле ниже var linksLength = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square').length; // Перебор и запись всех статей на выбранной странице for (i = 0; i < linksLength; i++) { // Получение относительных ссылок на статьи (так в оригинале) var relLink = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square')[i].getElementsByClassName('views-field views-field-title')[0].getElementsByTagName('a')[0].outerHTML; // Превращение ссылок в абсолютные var article = relLink.replace('/', 'https://jrnlst.ru/') + '<br>' + 'n'; // Уведомление о найденных статьях console.log('На странице ' + 'найдена статья: ' + article); // Запись результата в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.')}; // Уведомление об окончании работы парсера }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; // Завершение работы функции }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
На всё ровно 50 строк с учётом детальных комментариев для читающего и уведомлений в консоль о ходе выполнения программы.
Концептуально этот парсер работает так:
- Подключаем нужные модули.
- Определяем константы: количество страниц сайта, основную часть ссылки (кроме номера страницы, который как раз меняется).
- Определяем стартовые значения основных переменных: начало прохода с нулевой страницы и нулевую задержку запросов, которая будет постоянно увеличиваться.
- Определяем основную функцию парсера под названием paginator(), в которой находится почти весь код.
- Последней строкой запускаем эту функцию.
Отдельно скажем об устройстве функции paginator().
Внутри неё есть ещё одна функция — getArticles(), которая конструирует ссылку на последующую страницу из постоянной «базовой части» и номера, делает GET-запрос с помощью команды модулю axios, разбирает результат как DOM-дерево с помощью модуля jsdom, вынимает все ссылки на странице, превращает их из относительных в абсолютные, записывает результат в файл и увеличивает переменную с номером страницы для использования в следующем запросе.
Цикл for, который запускает внутреннюю функцию getArticles() — по расписанию и со всё увеличивающейся задержкой. Установлена задержка в 10 секунд, потому что это не будет сильно нагружать сайт, а общее время выполнения не окажется слишком долгим — плюс разработчики сайта сами рекомендовали такое время в директиве crawl-delay в файле robots.txt (хотя так делают разработчики далеко не всех сайтов, потому что эта директива считается устаревшей). Каждый последующий запуск функции инициирует запрос к более старой странице, поскольку каждый предыдущий запуск увеличивает переменную с номером страницы на 1.
Функция getArticles() запускается, пока переменная с номером следующей страницы не превысит константу с общим количеством страниц. Тогда выполнение всего кода завершается с уведомлением в консоль. В противном случае парсер пытался бы стучаться в двери сайта бесконечно, в чём нет никакого смысла.
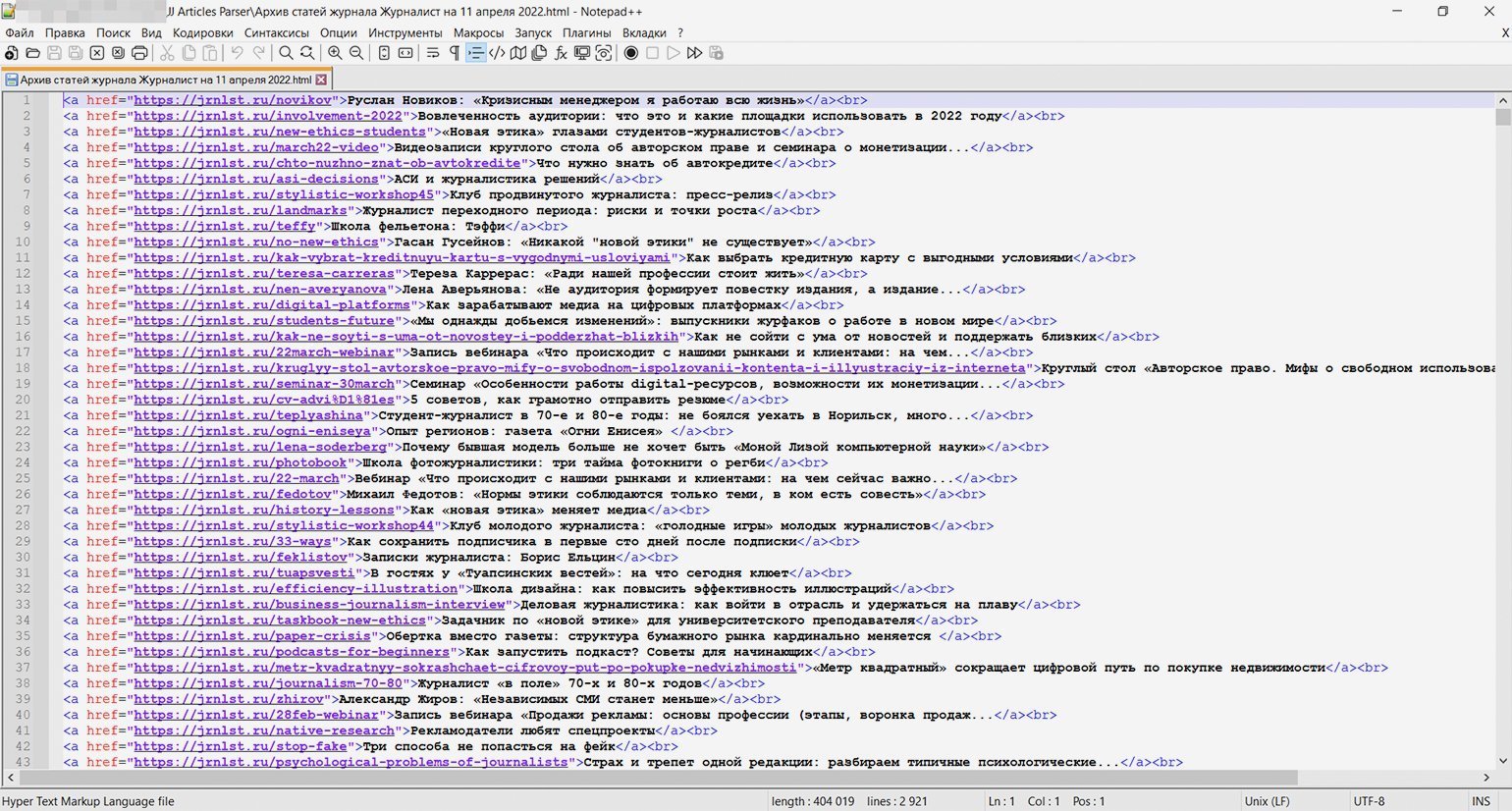
Скриншот: Евгений Колесников для Skillbox Media
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.
Напомним, второй способ — это загрузка дополнительных статей на ту же страницу. Обычно в таких случаях простых способов перейти на какую-то дату или в конец просто нет. Страницы со статьями, конечно же, существуют, но только для сервера, обрабатывающего запрос на подгрузку, а не для пользователя.
Для демонстрации этого способа пагинации по предложению редактора Тимура спарсим рубрику «Код» Skillbox Media (без новостей, только статьи). Как тут, спрашивается, применить описанные выше принципы сбора, если видимой нумерации страниц нет? Пойдём по тем же шагам, что и в прошлом примере.
В этом случае наши действия будут иными: нужно открыть в браузере инструменты веб-разработки на вкладке «Сеть», чтобы пошпионить за выполняемыми сайтом запросами, а после этого нажать на странице рубрики на кнопку «Показать ещё», подгружающую дополнительные материалы.

Скриншот: Евгений Колесников для Skillbox Media
В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
{
"params[SECTION_ID]": "10",
"params[CODE_EXCLUDE]": "news",
"params[FIRST_IS_FULL]": "Y",
"params[COUNT]": "7",
"params[PAGE_NUM]": "2",
"params[FIELDS][]": "PROPERTY_FAKE_COUNTER",
"params[CACHE_TYPE]": "A",
"params[COMPONENT_TEMPLATE]": "articles"
}
Параметр «PAGE_NUM», равный в данном случае 2, соответствует как раз номеру страницы, «SECTION_ID», равный 10, соответствует рубрике «Код», которую мы собрались парсить, а «COUNT», равный 7, — количеству выводимых на странице материалов.
Обратите внимание, что загрузка дополнительных статей в данном случае оформлена как POST-запрос, а не GET- (обычно GET-запрос используется для получения данных с сервера, а POST-запрос — для отправки). Почему это так — отдельный вопрос, выходящий за рамки статьи. При разработке парсера мы должны подстроиться под логику разработчиков сайта, однако ради любопытства попробуем провести небольшой эксперимент.
Если мы скопируем указанную выше ссылку и перейдём по ней без указания параметров, то сайт выдаст ошибку («status: error») — он просто не будет знать, какую информацию мы у него просим. Здесь браузер передаст именно GET-запрос, а не POST-, однако сайт всё равно нам отвечает (сообщение об ошибке — тоже сообщение).
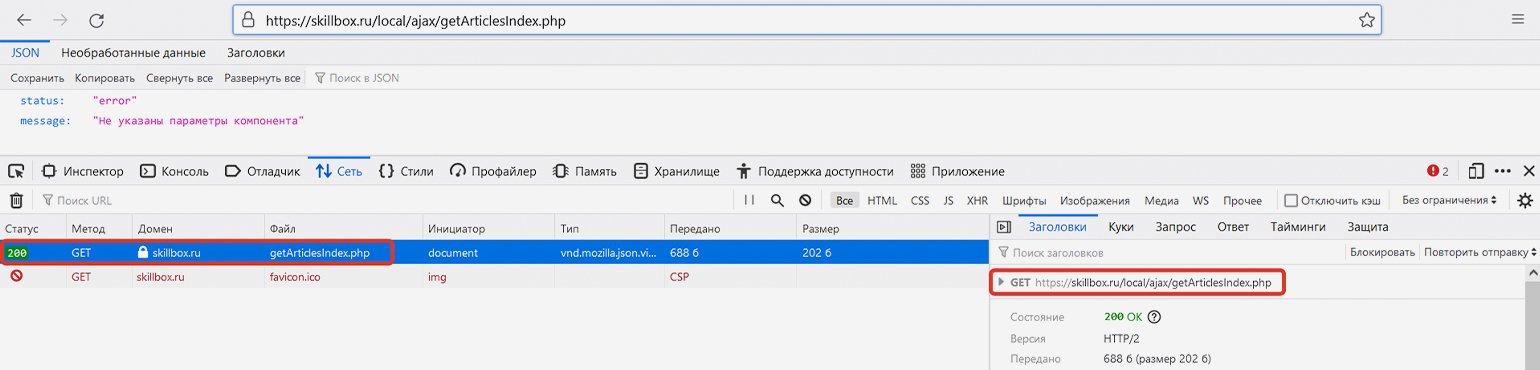
Скриншот: Евгений Колесников для Skillbox Media
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом «ok».
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
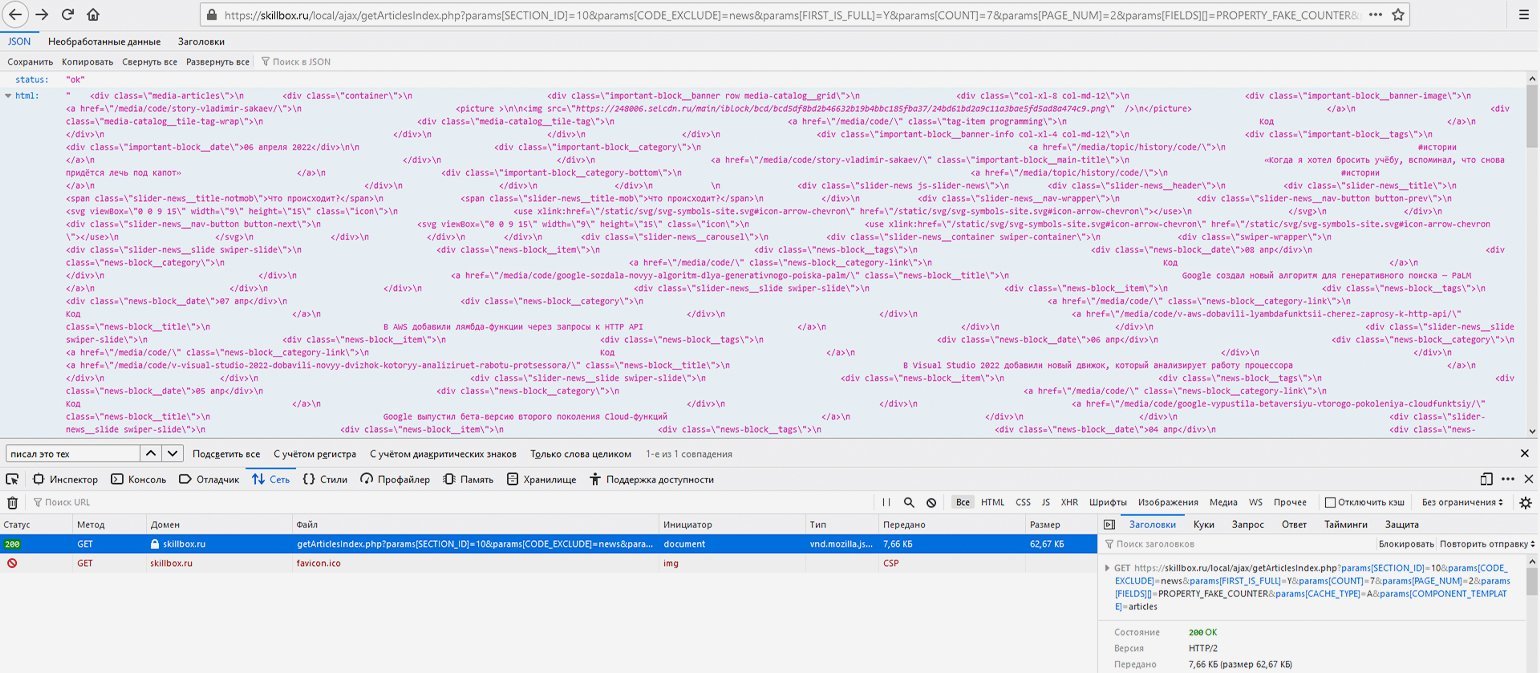
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра «[PAGE_NUM]». Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
Скриншот: Евгений Колесников для Skillbox Media
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
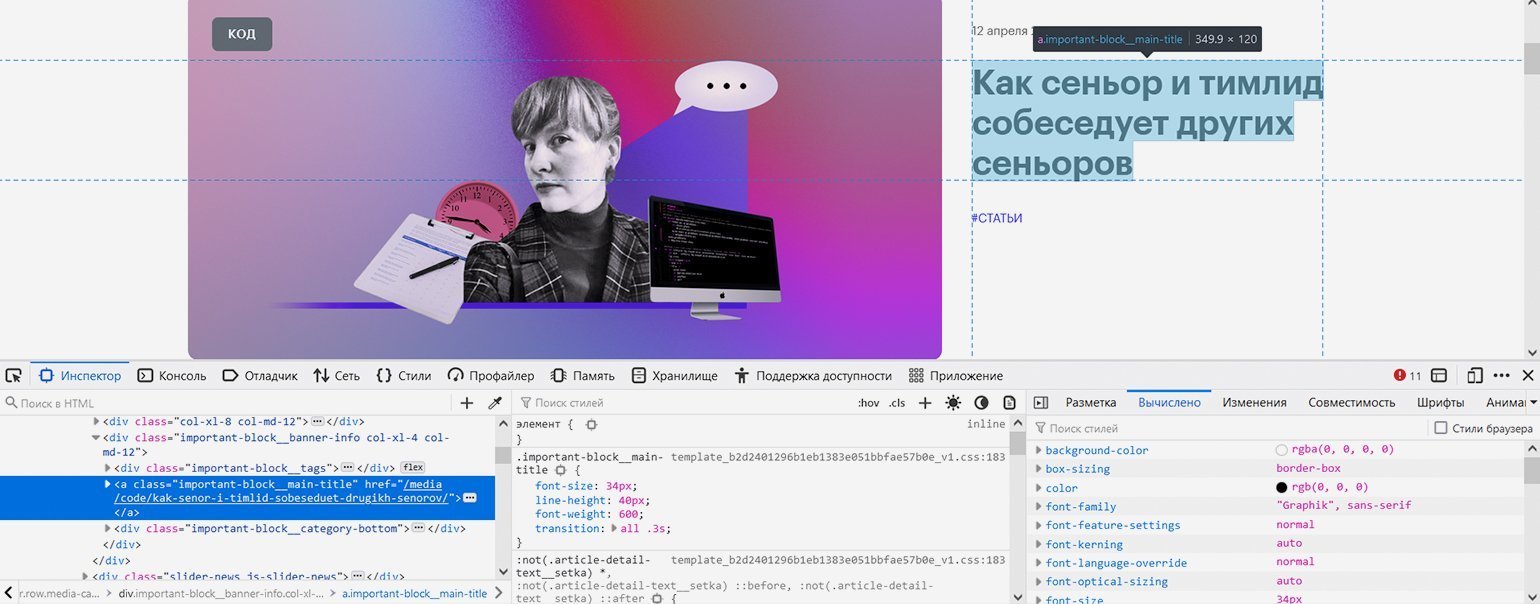
Скриншот: Евгений Колесников для Skillbox Media
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом «important-block__main-title».
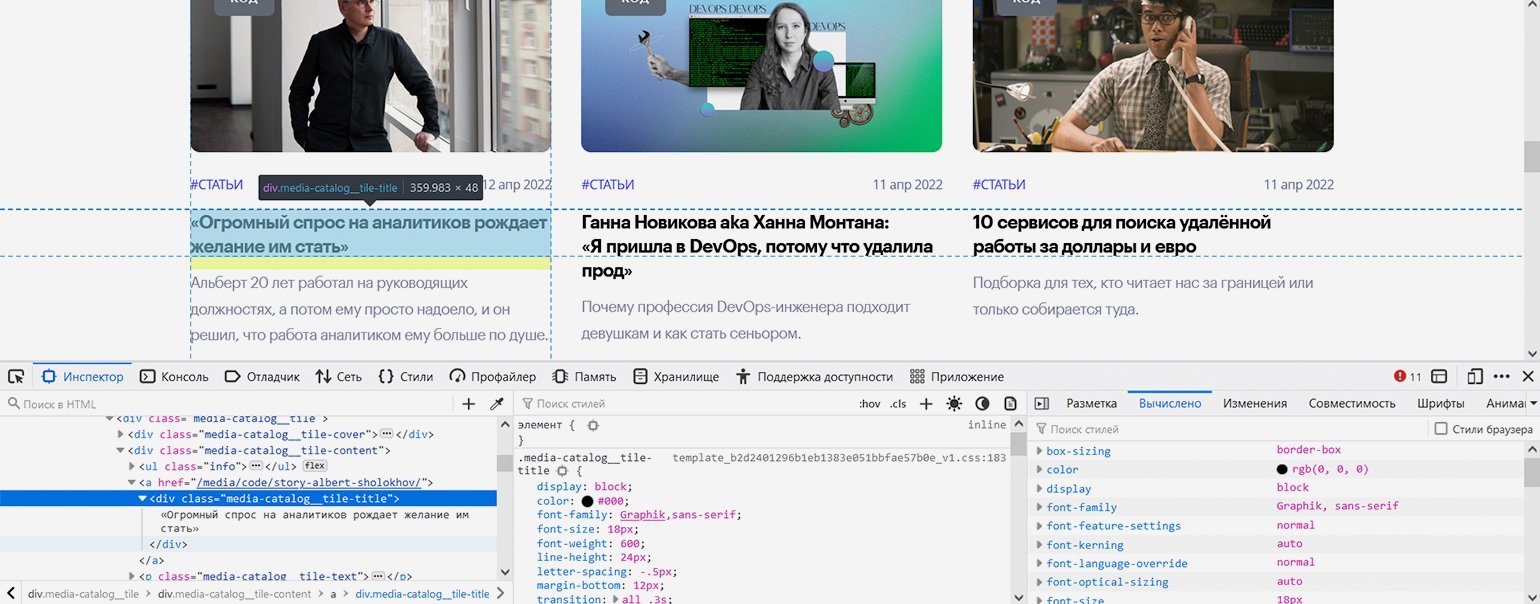
Скриншот: Евгений Колесников для Skillbox Media
С остальными посложнее: блочный элемент <div> с классом «media-catalog__tile-title» вложен в ссылку — элемент <a>, что довольно необычно. <div> содержит только текст заголовка, а у ссылки <a> не указан класс — но всё это мы решим с помощью правильной навигации.
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
/* Парсер статей рубрики «Код» портала Skillbox Media (https://skillbox.ru/media/code/) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключаем к Node.js модуль axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 101; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице по семь статей var page = 1; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) // Определяем стартовые параметры запроса (меняться будет только номер страницы) var params = new URLSearchParams(); params.append('params[SECTION_ID]', '10'); params.append('params[CODE_EXCLUDE]', 'news'); params.append('params[FIRST_IS_FULL]', 'Y'); params.append('params[COUNT]', '7'); params.append('params[PAGE_NUM]', '1'); params.append('params[FIELDS][]', 'PROPERTY_FAKE_COUNTER'); params.append('params[CACHE_TYPE]', 'A'); params.append('params[COMPONENT_TEMPLATE]', 'articles'); function paginator() { function getArticles() { console.log('Запрос статей со страницы ' + params.get('params[PAGE_NUM]')); // Уведомление о номере текущей страницы // Запрос к странице сайта axios.post('https://skillbox.ru/local/ajax/getArticlesIndex.php?', params) .then(response => { var currentPage = response.data; // Запись полученного результата var jsonToHtml = currentPage.html; // Получаем из JSON-ответа только HTML-код const dom = new JSDOM(jsonToHtml); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Парсинг закреплённой статьи var pinnedHeaderSpaces = dom.window.document.getElementsByClassName('important-block__main-title')[0].innerHTML; // Получение заголовка закреплённой статьи с лишними пробелами var pinnedHeader = pinnedHeaderSpaces.trim(); // Заголовок закреплённой статьи с удалёнными лишними пробелами var pinnedLink = dom.window.document.getElementsByClassName('important-block__main-title')[0].getAttribute('href'); // Получение относительной ссылки на закреплённую статью var pinnedArticle = '<a href="https://skillbox.ru' + pinnedLink + '">' + pinnedHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком закреплённой статьи console.log('На странице найдена закреплённая статья: ' + pinnedArticle); // Запись закреплённой статьи в файл fs.appendFileSync('ПУТЬ/articles.html', pinnedArticle, (err) => { if (err) throw err; }); // Парсинг остальных шести статей на странице var articlesNumber = dom.window.document.getElementsByClassName('media-catalog__tile-title').length; // Определение количества ссылок на странице, потому что на последней странице их меньше. Эта цифра понадобится в цикле ниже for (var art = 0; art < articlesNumber; art++) { var articleHeaderSpaces = dom.window.document.getElementsByClassName('media-catalog__tile-title')[art].innerHTML; // Получение заголовка статьи с лишними пробелами var articleHeader = articleHeaderSpaces.trim(); // Заголовок статьи с удалёнными лишними пробелами var articleLink = dom.window.document.getElementsByClassName('media-catalog__tile')[art].getElementsByClassName('media-catalog__tile-title')[0].parentElement.getAttribute('href'); // Получение относительной ссылки на статью var article = '<a href="https://skillbox.ru' + articleLink + '">' + articleHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком статьи console.log('На странице найдена статья: ' + article); // Запись статьи в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.'); // Уведомление об окончании работы парсера }; }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу params.set('params[PAGE_NUM]', page); return; }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
Наш код изменился, но всё ещё похож на прошлый. Обратите внимание на ряд нюансов:
- Делаем не GET-, а POST-запрос, поэтому вместо метода axios.get() будем использовать axios.post() (строка 29).
- Используем интерфейс URLSearchParams для передачи и чтения найденных выше параметров сетевого запроса в особом формате (строки 14–23, 27 и 62–63).
- Немного затрагиваем получение данных из JSON-формата, но только в одной строчке (строки 32–33).
- На каждой странице сначала отдельно парсим закреплённую статью, а потом шесть обычных, следуя логике вёрстки сайта.
Скриншот: Евгений Колесников для Skillbox Media
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:
После этого у вас откроется интерфейс разработчика:
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
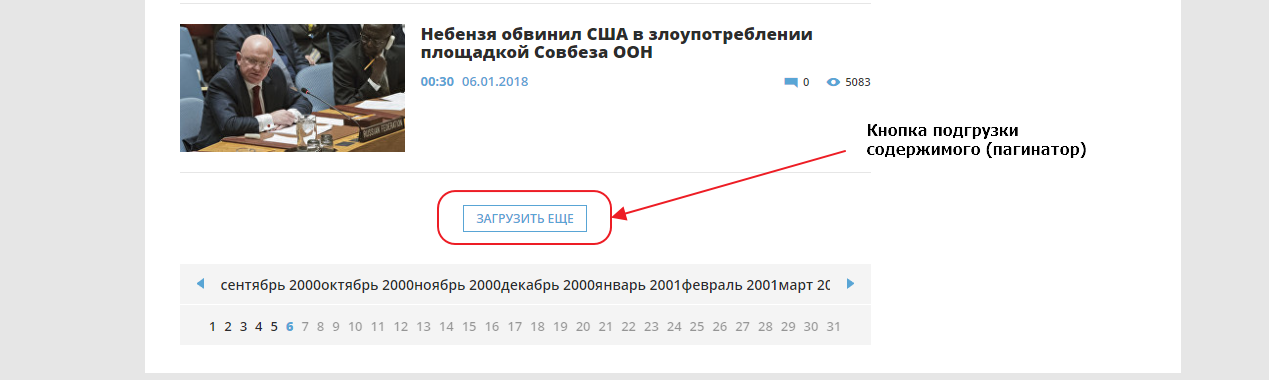
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
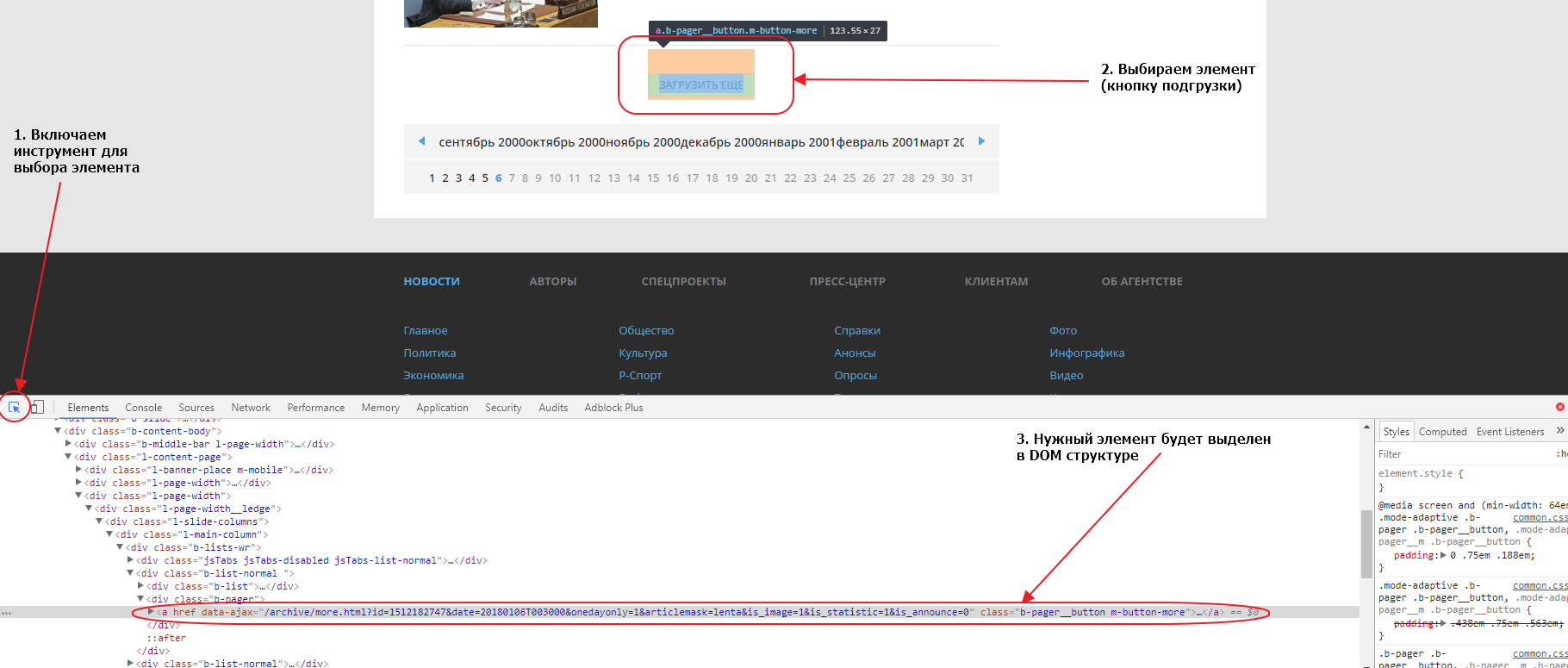
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0.
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
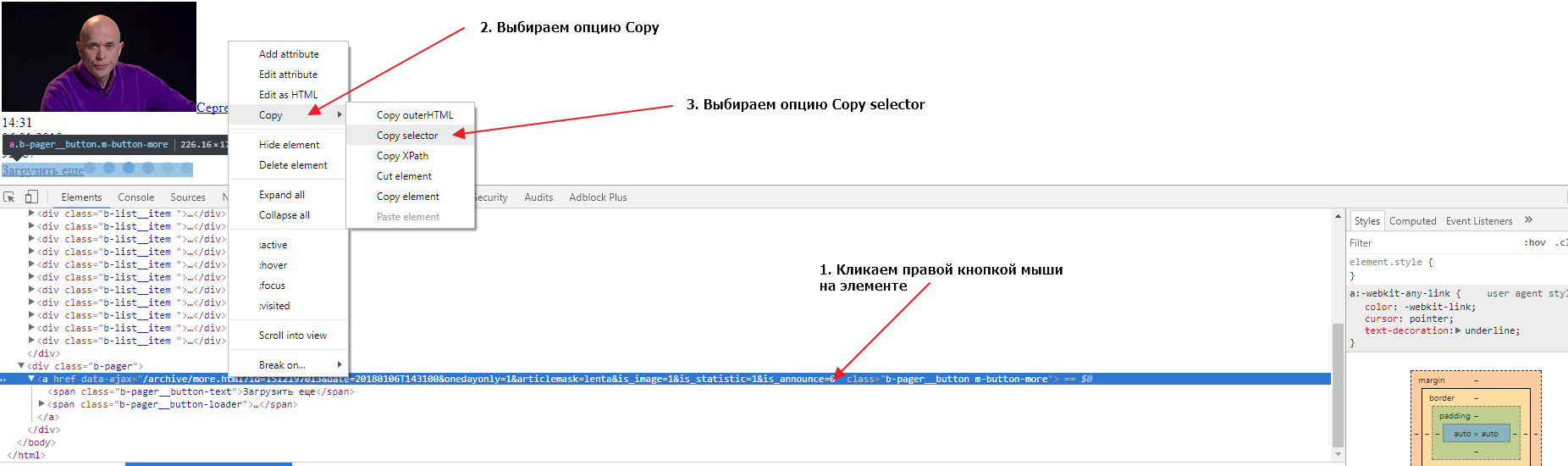
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
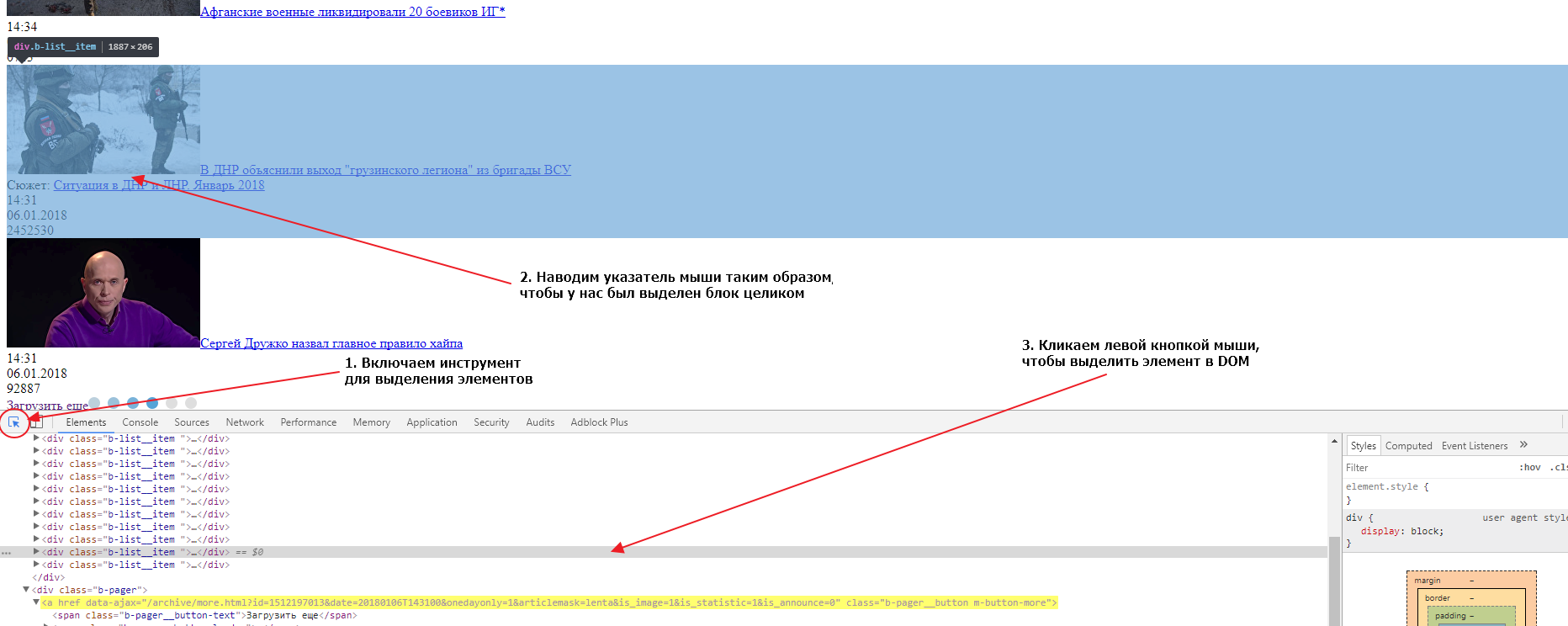
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
Всем привет! Сегодня мы учимся парсить любой веб-портал из кода нашего приложения. Для парсинга данных используем язык программирования C#. Если ваш любимый язык не C#, то не беда — используя данный подход можно решить задачу парсинга на любом современном языке.
Итак, ставим задачу.
Задача: спарсить карточку товара из онлайн магазина baucenter.ru, зная артикул товара.
Что понадобится ?
1. Сниффер HTTPS пакетов. Использую Fiddler.
2. Среда разработки приложения Visual Studio 2019.
Этап 1. Сбор данных сниффером пакетов
Запускаем Fiddler, параллельно открываем браузер и переходим на baucenter.ru. В поле поиска товара вставляем любой известный на данном сайте артикул товара (при открытии любого товара отображается артикул). Использую артикул 416001653.
Результат сбора данных представлен на рисунке 1. Только собранных пакетов будет не 32 как нарисунке, а больше (у меня 320).
Этап 2. Фильтрация пакетов
Из большого количества собранных пакетов полезными являются единицы, остальные просто засоряют список, тем самым затрудняя понимание того, что нужно сделать.
Ненужные пакеты — это:
- Пакеты вида Tunnel to …;
- Изображения и шрифты;
- JavaScript файлы;
- CSS файлы;
- Запросы на другие порталы нежели baucenter.ru.
Удалив ненужное, получаем следующее:
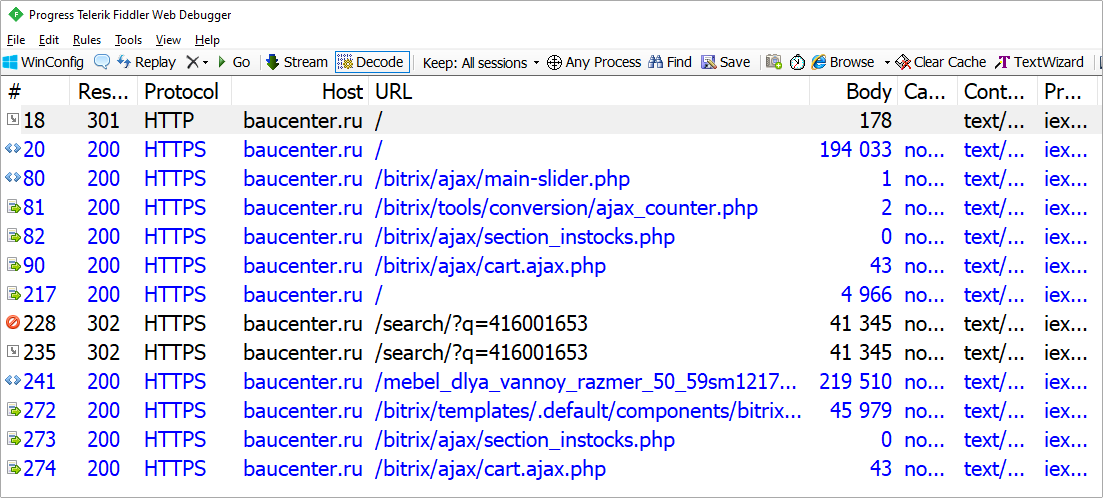
Рисунок 2. Список отфильтрованных пакетов
Открыв карточку товара с артикулом 416001653 в браузере, видим карточку товара со всеми данными. Нас интересует название товара и цена.
Название товара: Тумба с раковиной Onika Крит 52 см.
Цена товара: 3390.
В Fiddler через поиск по тексту ищем, в каком запросе есть текст с названием товара, ценой и артикулом. В моём случае это запрос №241. Рассмотрим его.
Обратим внимание, чтобы выполнить данный запрос нужно знать адрес карточки товара https://baucenter.ru/mebel_dlya_vannoy_razmer_50_59sm1217/686594/. А его в данный момент у нас нет.
Снова через поиск по тексту в Fiddler ищем текст: https://baucenter.ru/mebel_dlya_vannoy_razmer_50_59sm1217/686594/. В моём случае этот текст находится в запросе №217.
Рассмотрев данный запрос и ответ веб-сайта на данный запрос (рисунки 4 и 5), делаем следующие выводы:
- в HTML-коде ответа на запрос №217 есть ссылка на карточку товара. Зная эту ссылку, мы из кода программы сделаем туда запрос и получим необходимые данные о товаре (название и цену, например);
- для выполнения запроса №217 нужно знать только артикул товара, а он у нас есть («416001653»);
- чтобы получить карточку товара из кода приложения, нужно сделать 2 запроса: POST-запрос на адрес https://baucenter.ru, передав артикул товара, и GET-запрос на полученный адрес из первого запроса.
Этап 4. Создать классы GetRequest и PostRequest в приложении
Чтобы спарсить данные из приложения, необходимо, чтобы ваше приложение отправило необходимые запросы на веб-портал. Эти запросы должны быть неотличимы от запросов веб-браузера. Для выполнения парсинга данных создадим классы GetRequest и PostRequest.
public class GetRequest
{
HttpWebRequest _request;
string _address;
public Dictionary<string, string> Headers { get; set; }
public string Response { get; set; }
public string Accept { get; set; }
public string Host { get; set; }
public string Referer { get; set; }
public string Useragent { get; set; }
public WebProxy Proxy { get; set; }
public GetRequest(string address)
{
_address = address;
Headers = new Dictionary<string, string>();
}
public void Run(CookieContainer cookieContainer)
{
_request = (HttpWebRequest)WebRequest.Create(_address);
_request.Method = "Get";
_request.CookieContainer = cookieContainer;
_request.Proxy = Proxy;
_request.Accept = Accept;
_request.Host = Host;
_request.Referer = Referer;
_request.UserAgent = Useragent;
foreach (var pair in Headers)
{
_request.Headers.Add(pair.Key, pair.Value);
}
try
{
HttpWebResponse response = (HttpWebResponse)_request.GetResponse();
var stream = response.GetResponseStream();
if (stream != null) Response = new StreamReader(stream).ReadToEnd();
}
catch (Exception)
{
}
}
}public class PostRequest
{
HttpWebRequest _request;
string _address;
public Dictionary<string, string> Headers { get; set; }
public string Response { get; set; }
public string Accept { get; set; }
public string Host { get; set; }
public string Data { get; set; }
public string ContentType { get; set; }
public WebProxy Proxy { get; set; }
public string Referer { get; set; }
public string Useragent { get; set; }
public PostRequest(string address)
{
_address = address;
Headers = new Dictionary<string, string>();
}
public void Run(CookieContainer cookieContainer)
{
_request = (HttpWebRequest)WebRequest.Create(_address);
_request.Method = "Post";
_request.CookieContainer = cookieContainer;
_request.Proxy = Proxy;
_request.Accept = Accept;
_request.Host = Host;
_request.ContentType = ContentType;
_request.Referer = Referer;
_request.UserAgent = Useragent;
byte[] sentData = Encoding.UTF8.GetBytes(Data);
_request.ContentLength = sentData.Length;
Stream sendStream = _request.GetRequestStream();
sendStream.Write(sentData, 0, sentData.Length);
sendStream.Close();
foreach (var pair in Headers)
{
_request.Headers.Add(pair.Key, pair.Value);
}
try
{
HttpWebResponse response = (HttpWebResponse)_request.GetResponse();
var stream = response.GetResponseStream();
if (stream != null) Response = new StreamReader(stream).ReadToEnd();
}
catch (Exception)
{
}
}
}Данные классы позволяют выполнять Get и Post запросы на веб-порталы. В конструктор класса передается адрес веб-сайта. В свойства класса передаются стандартные заголовки HTTP запроса: Accept, Host, Data, ContentType, Referer, Useragent. Свойство Proxy служит для установки прокси-сервера, через который будет отправлен запрос.
Это нужно для удобной проверки выполнения своего кода, передав в это свойство значение прокси-сервера Fiddler (по умолчанию 127.0.0.1:8888). Таким образом, при выполнении запросов из программы вы увидите запросы в Fiddler и сможете легко понять проблему, если она будет.
Выполнение запроса происходит при вызове метода Run, и передаче в данный метод контейнер куки. Контейнер куки создаёте перед выполнением всех запросов. После выполнения запросов контейнер записывает в себя, полученные от веб-портала куки. Это позволяет выполнять последующие запросы с сохраненными куки-данными.
Результат выполнения запроса записывается в виде текста в свойство Response.
Этап 5. Создание приложения для получения карточки товара
static void Main(string[] args)
{
// артикул товара
var code = "416001653";
// прокси-сервер
var proxy = new WebProxy("127.0.0.1:8888");
// контейнер куки
var cookieContainer = new CookieContainer();
// запрос №1. получение адреса карточки товара по артикулу товара
var postRequest = new PostRequest("https://baucenter.ru/");
postRequest.Data = $"ajax_call=y&INPUT_ID=title-search-input&q={code}&l=2";
postRequest.Accept = "*/*";
postRequest.Useragent = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko";
postRequest.ContentType = "application/x-www-form-urlencoded";
postRequest.Referer = "https://baucenter.ru/";
postRequest.Host = "baucenter.ru";
postRequest.Proxy = proxy;
postRequest.Headers.Add("Bx-ajax", "true");
postRequest.Run(cookieContainer);
// поиск в HTML-коде ответа адрес карточки товара
var strStart = postRequest.Response.IndexOf("search-result-group search-result-product");
strStart = postRequest.Response.IndexOf("<a href=", strStart) + 9;
var strEnd = postRequest.Response.IndexOf(""", strStart);
var getPath = postRequest.Response.Substring(strStart, strEnd - strStart);
// вывод в консоль найденный адрес карточки по артикулу
Console.WriteLine($"getPath={getPath}");
// запрос №2. получение карточки товара
var getRequest = new GetRequest($"https://baucenter.ru{getPath}");
getRequest.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9";
getRequest.Useragent = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko";
getRequest.Referer = "https://baucenter.ru/";
getRequest.Host = "baucenter.ru";
getRequest.Proxy = proxy;
getRequest.Run(cookieContainer);
// создание объекта класса карточки товара для парсинга искомых данных
var card = new Card();
card.Parse(getRequest.Response);
// вывод в консоль параметров найденного товара: название и цена
Console.WriteLine($"title={card.Title}");
Console.WriteLine($"price={card.Price}");
Console.ReadKey();
} /// <summary>
/// Класс карточка товара.
/// Метод Parse - парсинг HTML, запись свойств Title и Price
/// </summary>
public class Card
{
public string Price { get; set; }
public string Title { get; set; }
public void Parse(string html)
{
var priceStart = html.IndexOf("Цена") + 11;
var priceEnd = html.IndexOf("<span", priceStart);
Price = html.Substring(priceStart, priceEnd - priceStart).Trim();
var titleStart = html.IndexOf("<h1>") + 4;
var titleEnd = html.IndexOf("</h1>", titleStart);
Title = html.Substring(titleStart, titleEnd - titleStart).Trim();
}
}Результат выполнения программы представлен на рисунке 6.
Код приложения можно найти здесь.
Подробное видео разработки данного проекта здесь:

Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.

Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
Почему и зачем использовать веб-парсинг?

Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
- Динамический мониторинг цен
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
- Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
- Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
- Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
- Тренды в социальных сетях
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
- Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
- Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
- Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
- Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
- Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
- Сканер
 Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
 Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
- Selenium-Selenium – это библиотека автоматического тестирования с открытым исходным кодом. Она используется для проверки активности браузера. Чтобы установить эту библиотеку, введите в терминале следующую команду.
pip install selenium
Примечание. Рекомендуется использовать IDE PyCharm.

- Pandas – библиотека для обработки и анализа данных. Используется для извлечения данных и сохранения их в желаемом формате.
- BeautifulSoup
BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
pip install bs4
Установка парсера
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:
pip install html5lib

BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
- Ярлык
Объект Tag соответствует исходному документу XML или HTML.
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
Выход:
<class "bs4.element.Tag">
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
-
- Имя
У каждого тега есть имя, доступное как .name:
tag.name
- Атрибуты
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
tag[id]
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
# add the element tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # delete the tag del tag['id']
- Многозначные атрибуты
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- Навигационная строка
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
tag.string # u'Extremely bold' type(tag.string) #
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
tag.string.replace_with("No longer bold")
tag
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
- BeautifulSoup объект
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
doc=BeautifulSoup("INSERT FOOTER HEREHere's the footer","xml")
doc.find(text="INSERT FOOTER HERE").replace_with(footer)
print(doc)
Выход:
?xml version="1.0" encoding="utf-8"?> #
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests.get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
Выход:
The object type <class 'requests.models.Response'> Convert the object into: <class 'bs4.BeautifulSoup'>
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
Выход:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,Free and open-source software,Proprietary software with free and open-source editions,Proprietary software,Journals,Conferences,See also,References,Further reading,External links,
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.

Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
following code: # importing the libraries from bs4 import BeautifulSoup import requests url="https://www.javatpoint.com/" # Make a GET request to fetch the raw HTML content html_content = requests.get(url).text # Parse the html content soup = BeautifulSoup(html_content, "html5lib") print(soup.prettify()) # print the parsed data of html
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
- Напечатаем заголовок веб-страницы.
print(soup.title)
Выход даст следующий результат:
<title>Tutorials List - Javatpoint</title>
- В приведенных выше выходных данных тег HTML включен в заголовок. Если вам нужен текст без тега, вы можете использовать следующий код:
print(soup.title.text)
Выход: это даст следующий результат:
Tutorials List - Javatpoint
- Мы можем получить всю ссылку на странице вместе с ее атрибутами, такими как href, title и ее внутренний текст. Рассмотрим следующий код:
for link in soup.find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
href is: https://www.facebook.com/javatpoint Inner Text is: The title is: None href is: https://twitter.com/pagejavatpoint Inner Text is: The title is: None href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg Inner Text is: The title is: None href is: https://javatpoint.blogspot.com Inner Text is: Learn Java Title is: None href is: https://www.javatpoint.com/java-tutorial Inner Text is: Learn Data Structures Title is: None href is: https://www.javatpoint.com/data-structure-tutorial Inner Text is: Learn C Programming Title is: None href is: https://www.javatpoint.com/c-programming-language-tutorial Inner Text is: Learn C++ Tutorial
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratingsn"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.close()
Выход:

Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Пишем изящный парсер на Питоне +51
Программирование, Ненормальное программирование, Python
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/
В C++17 (нет-нет, Питон скоро будет, вы правильно зашли!) появляется новый синтаксис для оператора if, позволяющий объявлять переменные прямо в заголовке блока. Это довольно удобно, поскольку конструкции вида
Foo foo = make_foo();
if(foo.is_nice()) {
// do work with foo
}
// never use foo again
// foo gets deleted
довольно общеупотребительны. Код выше лёгким движением руки программиста (и тяжёлым движением руки комитета по стандартизации) превращается в:
if(Foo foo = make_foo(); foo.is_nice()) {
// do work with foo
} // foo gets deleted
// never use foo again (well, you can't anyway)
Стало чуть-чуть лучше, хотя всё ещё не выглядит идеально. В Python нет и такого, но если вы ненавидите if в Python-коде так же сильно, как я, и хотите научиться быстро писать простые парсеры, то добро пожаловать под кат. В этой статье мы попытаемся написать короткий и изящный парсер для JSON на Python 2 (без каких-либо дополнительных модулей, конечно же).
Что такое парсинг и с чем его едят
Парсинг (по-русски «синтаксический анализ») — это бессмертная задача разобрать и преобразовать в осмысленные единицы нечто, написанное на некотором фиксированном языке, будь то язык программирования, язык разметки, язык структурированных запросов или главный язык жизни, Вселенной и всего такого. Типичная последовательность этапов решения задачи выглядит примерно так:
- Описать язык. Конечно, сначала надо определиться, какую именно задачу мы решаем. Обычно описание языка — это очередная вариация формы Бэкуса-Наура. (Вот, например, описание грамматики Python, использующееся при построении его парсера.) При этом устанавливаются как правила «построения предложений» в языке, так и правила определения валидных слов.
- Разбить ввод на токены. Пишется лексический анализатор (в народе токенайзер), который разбивает входную строку или файл на последовательность токенов, то есть валидных слов нашего языка (или ноет, что это нельзя сделать).
- Проверить синтаксис и построить синтаксическое дерево. Проверяем, соответствует ли последовательность токенов описанию нашего языка. Здесь в ход идут алгоритмы вроде метода рекурсивного спуска. Каждое валидное предложение языка включает какое-то конечное количество валидных слов или других валидных предложений; если токены смогли сложиться в стройную картину, то на выходе мы автоматически получаем дерево, которое и называется абстрактным синтаксическим деревом.
- Сделать, наконец, работу. У вас есть синтаксическое дерево и вы можете наконец сделать то, что хотели: посчитать значение арифметического выражения, организовать запрос в БД, скомпилировать программу, отобразить веб-страницу и так далее.
Вообще область эта изучена вдоль и поперёк и полна замечательных результатов, и по ней написаны сотни (возможно, хороших) книг. Однако, теоретическая разрешимость задачи и написание кода — не одно и то же.
Модельная задача
Написание парсера проиллюстрируем на простом, но не до конца тривиальном примере — парсинге JSON. Грамматика выглядит примерно так:
root ::= value
value ::= string | number | object | array | 'true' | 'false' | 'null'
array ::= '[' ']' | '[' comma-separated-values ']'
comma-separated-values ::= value | value ',' comma-separated-values
object ::= '{' '}' | '{' comma-separated-keyvalues '}'
comma-separated-keyvalues ::= keyvalue | keyvalue ',' comma-separated-keyvalues
keyvalue ::= string ':' value
Здесь нет правил для string и number — они, вместе со всеми строками в кавычках, будут нашими токенами.
Парсим JSON
Полноценный токенайзер мы писать не станем (это скучно и не совсем тема статьи) — будем работать с целой строкой и бить её на токены по мере необходимости. Напишем две первые функции:
import re
# без re.DOTALL мы сломаемся на первом же переносе строки
number_regex = re.compile(r"(-?(?:0|[1-9]d*)(?:.d+)?(?:[eE][+-]?d+)?)s*(.*)", re.DOTALL)
def parse_number(src):
match = number_regex.match(src)
if match is not None:
number, src = match.groups()
return eval(number), src # использовать eval - не лучшее решение, но самое простое
string_regex = re.compile(r"('(?:[^\']|\['\/bfnrt]|\u[0-9a-fA-F]{4})*?')s*(.*)", re.DOTALL)
def parse_string(src):
match = string_regex.match(src)
if match is not None:
string, src = match.groups()
return eval(string), src # здесь мы вообще подменили JSON'овский
# формат строк на питоновский, ну да ладно
(Я обещал без if’ов, но это последние, чесслово!)
Для всего остального напишем одну функцию, генерящую простенькие функции-парсеры:
def parse_word(word, value=None):
l = len(word)
def result(src):
# добавьте в следующую строчку вызовы .lower() для case-insensitive языка!
if src.startswith(word): # опять if! вот живучая тварь!
return value, src[l:].lstrip() # lstrip нужен для игнорирования пробелов, см. ниже
result.__name__ = "parse_%s" % word # для отладки
return result
parse_true = parse_word("true", True)
parse_false = parse_word("false", False)
parse_null = parse_word("null", None)
Итого, по какому принципу мы строим наши функции:
- Они принимают строку, которую нужно парсить.
- Они возвращают пару (результат, оставшаяся_строка) при успехе (то есть когда требуемая конструкция нашлась в начале строки) и
Noneпри провале. - Они отправляют в небытие все пробельные символы между токенами. (Не делайте так, если пишете парсер Питона!)
Собственно, на этих трёх функциях проблемы с токенами решены, и мы можем перейти к интересной части.
Парсим правило с ветвлением
Как должна выглядеть функция parse_value, соответствующая грамматике выше? Обычно как-то так:
def parse_value(src):
# попытайся распарсить строковый литерал
match = parse_string(src)
if match is not None:
# получилось!
return match
# не получилось; ну тогда попытайся распарсить число
match = parse_number(src)
if match is not None:
return match
# да что ж такое. ну тогда попытайся расп...
# ...
Ну уж нет, эти if достали меня!
Давайте поменяем три функции выше самым неожиданным образом: заменим return на yield! Теперь они возвращают генераторы — пустые, если парсинг не удался, и ровно с одним элементом, если удался. Да-да, мы разворачиваем на 90 градусов наш принцип номер 2: все наши функции мы будем теперь писать в таком стиле:
number_regex = re.compile(r"(-?(?:0|[1-9]d*)(?:.d+)?(?:[eE][+-]?d+)?)s*(.*)", re.DOTALL)
def parse_number(src):
match = number_regex.match(src)
if match is not None:
number, src = match.groups()
yield eval(number), src
# если управление дошло до сюда без yield, числа обнаружить не удалось.
# ну что же, пустой генератор тоже генератор.
string_regex = re.compile(r"('(?:[^\']|\['\/bfnrt]|\u[0-9a-fA-F]{4})*?')s*(.*)", re.DOTALL)
def parse_string(src):
match = string_regex.match(src)
if match is not None:
string, src = match.groups()
yield eval(string), src
def parse_word(word, value=None):
l = len(word)
def result(src):
if src.startswith(word):
yield value, src[l:].rstrip()
result.__name__ = "parse_%s" % word
return result # здесь возвращаем функцию-парсер, не yield'им
parse_true = parse_word("true", True)
parse_false = parse_word("false", False)
parse_null = parse_word("null", None)
Во что же превратится наша parse_value? На первый взгляд во что-то такое:
def parse_value(src):
for match in parse_string(src):
yield match
return
for match in parse_number(src):
yield match
return
# ...
Но на второй взгляд мы увидим, что каждая опция может занимать всего одну строчку!
# весьма полезная itertools.chain объединяет переданные ей итераторы
# в цепочку, не трогая ни один раньше времени
from itertools import chain
def parse_value(src):
for match in chain(
parse_string(src),
parse_number(src),
parse_array(src),
parse_object(src),
parse_true(src),
parse_false(src),
parse_null(src),
): # закрывающей скобке грустно, но веселье только начинается
yield match
return
При этом эффективность остаётся на прежнем уровне — каждая функция начнёт выполняться (а стало быть, делать работу, проверяя регулярные выражения) только тогда, когда предыдущая не даст результата. return гарантирует, что лишняя работа не будет выполнена, если где-то в середине списка парсинг удался.
Парсим последовательности конструкций
Перейдём к следующему номеру нашей программы — функции parse_array. Выглядеть она должна как-то так:
parse_left_square_bracket = parse_word("[")
parse_right_square_bracket = parse_word("]")
def parse_array(src):
# здесь потребуется временная переменная tsrc, иначе даже при неудачном
# парсинге пустого массива открывающая скобка может быть "съедена"
for _, tsrc in parse_left_square_bracket(src):
for _, tsrc in parse_right_square_bracket(tsrc):
# если мы здесь, то нам удалось последовательно распарсить '[' и ']'
yield [], tsrc
return
# здесь переменную src уже не жалко -- за этим циклом только боль и пустота
for _, src in parse_left_square_bracket(src):
for items, src in parse_comma_separated_values(src):
for _, src in parse_right_square_bracket(src):
yield items, src
# если управление дошло сюда без yield, то парсинг массива не удался
Ни одного if, как и обещано, но что-то всё равно не так… Давайте напишем небольшую вспомогательную функцию, которая поможет нам соединять функции-парсеры в последовательности подобно тому, как chain помогла соединять их в режиме «или». Эта функция должна будет аккуратно брать все результаты и вернуть все первые элементы результатов (результаты анализа) и последний второй элемент (оставшуюся непроанализированной часть строки). Мой вариант выглядит так:
def sequence(*funcs):
if len(funcs) == 0: # ну простите, не могу в рекурсию без if'а
def result(src):
yield (), src
return result
def result(src):
for arg1, src in funcs[0](src):
for others, src in sequence(*funcs[1:])(src):
yield (arg1,) + others, src # конкатенируем содержательные результаты
return result
С этим мощным (пусть и страшноватым) инструментом наша функция перепишется в виде:
parse_left_square_bracket = parse_word("[")
parse_right_square_bracket = parse_word("]")
parse_empty_array = sequence(parse_left_square_bracket, parse_right_square_bracket)
def parse_array(src):
for _, src in parse_empty_array(src): # увы, эта функция недостаточно умна, чтобы вернуть []
yield [], src
return # этот return нужен, чтобы не пойти радостно парсить
# дальше в конструкции вида {} {"a": 1}
for (_, items, _), src in sequence(
parse_left_square_bracket,
parse_comma_separated_values,
parse_right_square_bracket,
)(src):
yield items, src
# если управление дошло сюда без yield, то парсинг массива не удался
Ну а дописать функцию parse_comma_separated_values — раз плюнуть:
parse_comma = parse_word(",")
def parse_comma_separated_values(src):
for (value, _, values), src in sequence(
parse_value,
parse_comma,
parse_comma_separated_values # я говорил, что не могу в рекурсию без if? я соврал
)(src):
yield [value] + values, src
return
for value, src in parse_value(src):
yield [value], src
Приведёт ли такое решение к бесконечной рекурсии? Нет! Однажды функция parse_comma не найдёт очередной запятой, и до последующей parse_comma_separated_values выполнение уже не дойдёт.
Идём дальше! Объект:
parse_left_curly_bracket = parse_word("{")
parse_right_curly_bracket = parse_word("}")
parse_empty_object = sequence(parse_left_curly_bracket, parse_right_curly_bracket)
def parse_object(src):
for _, src in parse_empty_object(src):
yield {}, src
return
for (_, items, _), src in sequence(
parse_left_curly_bracket,
parse_comma_separated_keyvalues,
parse_right_curly_bracket,
)(src):
yield items, src
parse_colon = parse_word(":")
def parse_keyvalue(src):
for (key, _, value), src in sequence(
parse_string,
parse_colon,
parse_value
)(src):
yield {key: value}, src
def parse_comma_separated_keyvalues(src):
for (keyvalue, _, keyvalues), src in sequence(
parse_keyvalue,
parse_comma,
parse_comma_separated_keyvalues, # тут снова рекурсия, не проглядите
)(src):
keyvalue.update(keyvalues)
yield keyvalue, src
return
for keyvalue, src in parse_keyvalue(src):
# к сожалению, питон не умеет в генераторе возвращать другой генератор
yield keyvalue, src
Ну, что там дальше?
Собственно, всё! Остаётся добавить простую интерфейсную функцию:
def parse(s):
s = s.strip() # наш токенайзер убивает пробелы после токенов, но не терпит до
match = list(parse_value(s))
if len(match) != 1:
# где-то что-то пошло не так. про отладку расскажу в другой раз :)
raise ValueError("not a valid JSON string")
result, src = match[0]
if src.strip():
# мы распарсили, но в строке ещё что-то осталось. это ошибка.
raise ValueError("not a valid JSON string")
return result
Вуаля!
Весь код вместе
from itertools import chain
import re
def sequence(*funcs):
if len(funcs) == 0:
def result(src):
yield (), src
return result
def result(src):
for arg1, src in funcs[0](src):
for others, src in sequence(*funcs[1:])(src):
yield (arg1,) + others, src
return result
number_regex = re.compile(r"(-?(?:0|[1-9]d*)(?:.d+)?(?:[eE][+-]?d+)?)s*(.*)", re.DOTALL)
def parse_number(src):
match = number_regex.match(src)
if match is not None:
number, src = match.groups()
yield eval(number), src
string_regex = re.compile(r"('(?:[^\']|\['\/bfnrt]|\u[0-9a-fA-F]{4})*?')s*(.*)", re.DOTALL)
def parse_string(src):
match = string_regex.match(src)
if match is not None:
string, src = match.groups()
yield eval(string), src
def parse_word(word, value=None):
l = len(word)
def result(src):
if src.startswith(word):
yield value, src[l:].lstrip()
result.__name__ = "parse_%s" % word
return result
parse_true = parse_word("true", True)
parse_false = parse_word("false", False)
parse_null = parse_word("null", None)
def parse_value(src):
for match in chain(
parse_string(src),
parse_number(src),
parse_array(src),
parse_object(src),
parse_true(src),
parse_false(src),
parse_null(src),
):
yield match
return
parse_left_square_bracket = parse_word("[")
parse_right_square_bracket = parse_word("]")
parse_empty_array = sequence(parse_left_square_bracket, parse_right_square_bracket)
def parse_array(src):
for _, src in parse_empty_array(src):
yield [], src
return
for (_, items, _), src in sequence(
parse_left_square_bracket,
parse_comma_separated_values,
parse_right_square_bracket,
)(src):
yield items, src
parse_comma = parse_word(",")
def parse_comma_separated_values(src):
for (value, _, values), src in sequence(
parse_value,
parse_comma,
parse_comma_separated_values
)(src):
yield [value] + values, src
return
for value, src in parse_value(src):
yield [value], src
parse_left_curly_bracket = parse_word("{")
parse_right_curly_bracket = parse_word("}")
parse_empty_object = sequence(parse_left_curly_bracket, parse_right_curly_bracket)
def parse_object(src):
for _, src in parse_empty_object(src):
yield {}, src
return
for (_, items, _), src in sequence(
parse_left_curly_bracket,
parse_comma_separated_keyvalues,
parse_right_curly_bracket,
)(src):
yield items, src
parse_colon = parse_word(":")
def parse_keyvalue(src):
for (key, _, value), src in sequence(
parse_string,
parse_colon,
parse_value
)(src):
yield {key: value}, src
def parse_comma_separated_keyvalues(src):
for (keyvalue, _, keyvalues), src in sequence(
parse_keyvalue,
parse_comma,
parse_comma_separated_keyvalues,
)(src):
keyvalue.update(keyvalues)
yield keyvalue, src
return
for keyvalue, src in parse_keyvalue(src):
yield keyvalue, src
def parse(s):
s = s.strip()
match = list(parse_value(s))
if len(match) != 1:
raise ValueError("not a valid JSON string")
result, src = match[0]
if src.strip():
raise ValueError("not a valid JSON string")
return result
130 строк. Попробуем запустить:
>>> import my_json
>>> my_json.parse("null")
>>> my_json.parse("true")
True
>>> my_json.parse("false")
False
>>> my_json.parse("0.31415926E1")
3.1415926
>>> my_json.parse("[1, true, '1']")
[1, True, '1']
>>> my_json.parse("{}")
{}
>>> my_json.parse("{'a': 1, 'b': null}")
{'a': 1, 'b': None}Успех!
Заключение
Конечно, я рассмотрел далеко не все ситуации, которые могут возникнуть при написании парсеров. Иногда программисту может потребоваться ручное управление выполнением, а не запуск последовательности chainов и sequenceов. К счастью, это не так неудобно в рассмотренном подходе, как может показаться. Так, если нужно попытаться распарсить необязательную конструкцию и сделать действие в зависимости от её наличия, можно написать:
for stuff, src in parse_optional_stuff(src):
# опциональная конструкция на месте -- работаем
break # предотвращает выполнение else
else:
# опциональная конструкция отсутствует -- грустим
pass
Здесь мы пользуемся малопопулярной фишкой Питона — блоком else у циклов, который выполняется, если цикл дошёл до конца без break. Это выглядит не так привлекательно, как наш код в статье, но точно не хуже, чем те if, от которых мы столь изящно избавились.
Несмотря на неполноту и неакадемичность изложения, я надеюсь, что эта статья будет полезна начинающим программистам, а может, даже удивит новизной подхода программистов продвинутых. При этом я прекрасно отдаю себе отчёт, что это просто новая форма для старого доброго рекурсивного спуска; но если программирование — это искусство, разве не важна в нём форма если не наравне, то хотя бы в степени, близкой к содержанию?..
Как обычно, не откладывая пишите в личку обо всех обнаруженных неточностях, орфографических, грамматических и фактических ошибках — иначе я сгорю от стыда!
Парсинг
если в этом блоке вы плохо видите некоторые изображения, откройте их в новой вкладе
Введение
Все данные, которые мы видим на различных страницах интернета отдаются нам в виде html документов и данные в этих документах структурированы html тегами, которым зачастую присвоен какой-то уникальный идентификатор. Такое устройство распространения данных и дало нам возможность собирать эту информацию и, конечно, python имеет для этих целей свои библиотеки. Говорят, что нет интернет ресурса, с которого не возможно было бы спарсить данные, не возьмусь утверждать то же самое, но как минимум спарсить список вакансий с соответствующих сайтов или список актуальных скидок с какого-нибудь маркетплейса большого труда не составить. В этом блоке будем разбираться как это делается.
Библиотека requests
Установка библиотеки requests:
sudo apt install python3-requests — для терминала linux.
pip install requests — для виртуального окружения.
Библиотека requests позволяет нам отправлять запросы на сервера и получать на них ответ. requests поддерживает методы get и post, метод get используется, когда нам нужно просто получить данные со страницы, метод post используется, когда мы хотим передать какие-то данные обрабатываемому сайту, например авторизационные данные.
Давайте воспользуемся метод get для получения информации с сайта github.

Сначала импортируем библиотеку requests. В переменную link поместим ссылку на страницу, к которой хотим обратиться. GitHub имеет открытую api документацию, поэтому обратимся сразу к api сайта. Принято при работе с этой библиотекой называть переменную, которая будет хранить запрошенные данные, response, но это конечно не принципиально. Воспользоваться get запросом можно несколькими способна, конструкция типа:
response = requests.get('ссылка на ресурс') — возвратит статус запроса, в нашем случае мы получили ответ — response [200], код ответа 200 означает, что запрос отработал без ошибок.
response = requests.get('ссылка на ресурс').text — использование метода text позволяет декодировать запрос в читаемый текст, не всегда метод text может правильно декодировать запрос, тогда можно воспользоваться бинарным ответом.
response = requests.get('ссылка на ресурс').content — метод content отобразит бинарное содержимое ответа.
Поскольку в нашем запросе проблем с декодированием не возникло методы .text и .content возвратили нам одинаковый результат.
Что же мы получили в ответ на наш запрос? Мы получили разветвления, по которым мы можем продолжить делать запросы для получения нужной нам информации. Например, в этом списке есть отдельная ссылка, которая возвратит все emoji, используемые на github.

В ответ на этот запрос мы получаем огромный список ссылок, при переходе по которыми мы увидим какой-то emoji.
Это пример простых api запросов, с api сайтов работать достаточно просто, ведь разработчики сайта сами обернули в удобный вид информацию, которая может пригодиться пользователям. Но мы можем отправлять запросы не только к api, но и просто на любой сайт в интернете.
Процесс анализа интернет страниц для сбора информации и называется парсинг. Но библиотека requests это, конечно, не единственный инструмент для парсинга.
Библиотека fake-useragent
Установка библиотеки fake-useragent:
pip install fake-useragent
Многие сайты защищены от парсинга проверкой HTTP заголовка User-Agent, когда этого заголовка нет сайт воспринимает запрос, как запрос от робота и запрос не выполняется. Библиотека fake_useragent создает имитацию реального пользователя.

UserAgent каждый раз генерирует случайного пользователя, с разной ОС, браузером и прочими данными.
Библиотека BeautifulSoup и первый парсер
BeautifulSoup — наш основной инструмент, мощная и простая библиотека для парсинга.
Установка библиотеки BeautifulSoup:
sudo apt install python3-bs4 — для терминала linux.
pip install bs4 — для виртуального окружения.
Для работы библиотеки BeautifulSoup нужен модуль lxml. Объект BeautifulSoup принимает два аргумента — разметку страницы, к которой мы обращаемся и анализатор этой разметки. lxml как раз является этим анализатором, на ряду с ним используются html.parser и, например, html5lib, но если два последних позволяют обрабатывать исключительно HTML-файлы, то lxml обрабатывает и XML- и HTML-файлы.
Установка библиотеки lxml:
sudo apt install python3-lxml — для терминала linux.
pip install lxml — для виртуального окружения.
Начнем сразу с практики. Давайте опять вернемся на сайт github и посмотрим на страницу маркетплейса.

Отсортируем приложения по количеству установок. Допустим я не хочу заходить в этот раздел, чтобы посмотреть какое приложение на данный момент самое популярное, а хочу запускать программу, которая будет показывать мне его в консоли. Давайте это реализуем.

Посмотрим код этой страницы, нас интересует несколько данных. А именно заголовки запроса, в самом простом варианте хватит только user-agent. Для того чтобы его узнать зайдем во вкладку Network и если там пусто обновим страницу для того, чтобы увидеть список наших запросов на сайт. Выберем любой из этих запросов, например самый верхний и перейдем во вкладку headers. Возьмем оттуда наш user-agent. Необходимые данные есть, теперь перейдем в pycharm.
githubpars.py
import requests
from bs4 import BeautifulSoup
url = 'https://github.com/marketplace?query=sort%3Apopularity-desc&type=apps'
headers = {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0'
}
def get_apps():
response = requests.get(url=url, headers=headers)
html_file = response.text
with open('index.html') as file:
file.write(html_file)
bs = BeautifulSoup(response.text, "lxml")
apps_cards = bs.find_all("div", class_="d-md-flex flex-wrap mb-4")
for app_card in apps_cards:
print(app_card)
def main():
get_apps()
if __name__ == '__main__':
main()
Сначала импортируем библиотеки requests и BeautifulSoup. Далее создадим переменные url и headers, где url — адрес страницы откуда мы хотим забрать данные, а headers — заголовки запроса, которые нужны, чтобы показать сайту, что мы реальный человек, а не робот. В headers можно было бы добавить еще заголовок accept, найти его можно там же, где и user-agent. Первым делом сделаем get запрос к странице, используя атрибуты url и headers. Полученные данные представим в текстовом виде методом .text. Для наглядности сохраним спаршеную страницу в файл index.html. Если теперь открыть этот файл, то там будет весь html код исследуемой страницы. Следующим шагом создадим объект BeautifulSoup, с названием bs, куда передадим в качестве атрибутов наш response с примененным к нему методом text и lxml. Основные методы bs4, которыми мы будем пользоваться это find() и find_all().
Метод find() находит первое совпадение по имени тега или по его классу, либо, как на примере, одновременно по тегу и классу для большей точности.
Метод find_all() работает также, только находит все совпадения по заданным параметрам во всем файле. Обратите внимание, что class_ пишется с нижним подчеркиванием в конце, это необходимо из-за того, что class зарезервированное слово.
По какой логике мы выбираем какие данные передать в find() и find_all()? Вернемся на github. Я перешел с главной страницы на страницу посмотреть все.

Воспользуемся инструментом выбора элемента, выделен красным квадратиком на скриншоте, и найдем область, в которой находится список наших приложений. Все наши приложения лежат в теге div с классом «d-md-flex flex-wrap mb-4», передадим эти данные в переменную apps_cards. И как сразу видно в инспекторе внутри лежат все данные, которые нас могут заинтересовать. Пробежимся циклом по нашей переменной apps_cards и выведем результат.

Вот какие данные нам удалось забрать, информация о всех карточках, чего и следовало ожидать. Наша программа выполняет то, что от нее требуется. Соберем более детальные данные, например заберем название приложения и количество его установок. Как видно название лежит в теге h3 с классом — h4, а количество скачиваний в теге span с классом — text-small color-fg-muted text-bold. Воспользуемся этими данными.

Переменная app_name — для имени и переменная app_count_of_installs — для количества установок. Метод .text обрежет теги и оставит голый текст, а метод .strip уберет образовавшиеся после удаления тегов пробелы по краям. Выведем результат и получим то, что хотели — имя приложения и количество его установок. Не забывайте про конструкцию if __name__ == ‘__main__’.
Вот такая простенькая программа выводит нам в консоль интересующую нас информацию. Теперь эту программу можно открыть при закрытом браузере и увидеть самое популярное на данный момент приложение на github. Конечно, это не самое эффективное применение и не самые необходимые данные, но надеюсь данный кейс сформировал у вас представление о том, что такое парсинг и общую идею его работы.
Углубляемся в парсинг
Просто взять название со страницы вряд ли будет полезно, ткм более написав для этого достаточно нагроможденную программу. Это можно сделать гораздо лаконичнее. Всем названиям приложений присвоен один класс, достаточно их распечатать.

gt2.py
import requests
from bs4 import BeautifulSoup
url = 'https://github.com/marketplace?query=sort%3Apopularity-desc&type=apps'
headers = {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:96.0) Gecko/20100101 Firefox/96.0'
}
def get_apps():
response = requests.get(url=url, headers=headers)
bs = BeautifulSoup(response.text, 'lxml')
titles = bs.find_all(class_='h4')
n = 0
for title in titles:
app_title = title.text.strip()
n += 1
print(f"{n} - {app_title}")
def main():
get_apps()
if __name__ == '__main__':
main()
Таким образом получим все названия с первой страницы и за одно узнаем сколько их на странице. Объяснений по коду тут не требуется мы уже все это обсудили. Но допустим нам хочется не только получить названия приложений, но и ссылку в маркетплейс на страницу этого приложения. Вернемся еще раз к коду страницы.

Как мы видим каждому приложению выделен отдельный блок. И у каждого есть атрибут «href=» где лежит ссылка на проект. Давайте пробежимся по всем приложениям и заберем помимо названий ссылки.

Тут уже есть что обсудить. Во-первых, как и в самом первом парсере, заберем весь html код страницы и прочитаем его в переменную item, и в дальнейшем будем обращаться к ней. Зачем нам мучить сайт запросами, если мы можем обращаться к его сохраненной копии. Конечно, если мы хотим получать актуальную информацию с сайта, то такой вариант нам не подойдет, но когда мы только пишем программу и экспериментируем с ее кодом, каждый раз обращаться напрямую к сайту нет нужды. Далее пробежимся по каждому тегу a с интересующим нас классом. Названия приложений заберем уже знакомым способом. А ссылки заберем методом get, которым обратимся к атрибуту href. Но если просто забрать содержимое href, то мы получим ссылку без доменного имени, поэтому на каждой итерации будем плюсовать доменное имя к нашей ссылке. Теперь наш парсер кажется более полезным, мы получили список приложений по популярности со ссылками на них. Правда остался еще один момент, мы забираем приложения только с первой страницы, но конечно хотелось бы забрать данные со всех страниц.

Спустимся вниз страницы и посмотрим сколько страницы на странице, перейдем на вторую и обратим внимание на ссылку, меняется параметр page. Воспользуемся этим.

Вот таким нехитрым способом можно это реализовать. Поместим url внутрь функции и поместим все тело функции в цикл for, количество итераций которого равно количеству страниц + 1. С помощью f строки будем поочередно вставлять номер страницы в ссылку. Программа вернула нам все приложения со всех страниц и ссылки на них списком, достаточно удобно. Последним приложением в списке является — Indeema Tambo, перейдем на 27 страницу и посмотрим все ли верно.

Чего и следовало ожидать. И напоследок давайте сохраним полученную информацию в json файл.

githubpars_evolve.py
import requests
from bs4 import BeautifulSoup
import json
headers = {
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:96.0) '
'Gecko/20100101 Firefox/96.0'
}
def get_apps():
apps_github_dict = {}
for x in range(28):
url = f'https://github.com/marketplace?page={x}'
f'&q=sort%3Apopularity-desc&query=sort%3Apopularity-desc&type=apps'
response = requests.get(url=url, headers=headers)
with open('index.html', 'w') as file:
file.write(response.text)
with open('index.html') as file:
item = file.read()
bs = BeautifulSoup(item, 'lxml')
titles = bs.find_all(class_='col-md-6 mb-4 d-flex no-underline')
for title in titles:
app_title = title.find('h3', class_='h4').text.strip()
app_href = 'https://github.com/' + title.get("href")
apps_github_dict[app_title] = app_href
with open('apps_info_dict.json', 'w') as file:
json.dump(apps_github_dict, file, indent=4)
def main():
get_apps()
if __name__ == '__main__':
main()
Импортируем библиотеку json. Создадим перед главным циклом пустой словарь куда будем в качестве ключа передавать название проекта, а в качестве значения ссылку на этот проект. И с помощью метода dump библиотеки json сохраним этот словарь в json формат.
Парсинг и телеграм бот
Давайте сымитируем ситуацию. Какое-то время я работал на сайте g2g, на этом сайте люди продают игровые услуги за деньги, конкретно я в основном продавал золото в игре World of Warcraft.

Рассмотрим сайт. Я продавал золото на сервере Dragon’s Call — фракция Альянс. Перейдем на страницу продавцов этого сервера и включим тумблер lower price, чтобы отсортировать продавцов по возрастанию цены. Перед нами карточки продавцов, у них есть: имя, метод доставки, время доставки, количество золота в наличии, минимальное количество золота, которое можно приобрести и цена за одну монету плюс валюта. Я хочу получать актуальную информацию с этой страницы, чтобы мониторить как меняется активность на этой вкладке. Мне хочется получать имя, количество золота и цену за единицу. Мы уже знаем как это сделать, но возникает одна трудность и как с ней поступать мы еще не знаем. Вся нужная нам информация находится в одном блоке с классом ‘other_offer-desk-main-box other_offer-div-box’, для имени и цены за единицу тоже есть уникальные классы, а вот у количества, класс точно такой же как и у времени доставки и такой же, как у минимальной суммы сделки. Для того чтобы взять нужную информацию из одинаковых тегов с одинаковыми классами напишем такую программу.

g2gpars.py
import requests
from bs4 import BeautifulSoup
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:96.0) '
'Gecko/20100101 Firefox/96.0'
}
def get_sellers():
url = 'https://www.g2g.com/offer/Dragon-s-Call-TBC--DE----'
'Alliance?service_id=lgc_service_1&brand_id=lgc_game_29076®ion'
'_id=ac3f85c1-7562-437e-b125-e89576b9a38e&fa=lgc_29076_server%3Algc_'
'29076_server_40988&q=dra&sort=lowest_price&include_offline=1'
response = requests.get(url=url, headers=headers)
with open('index_g2g.html', 'w') as file:
file.write(response.text)
with open('index_g2g.html') as file:
item = file.read()
bs = BeautifulSoup(item, 'lxml')
sellers = bs.find_all(class_='other_offer-desk-main-box other_offer-div-box')
for seller in sellers:
seller_name = seller.find("div", class_='seller__name-detail').text.strip()
seller_stock = seller.find("div", class_='offers-bottom-attributes '
'offer__content-lower-items').find_next().find_next().find("span").text.strip()
seller_price = seller.find("span", class_='offer-price-amount').text
print(f"{seller_name} - {seller_stock} - {seller_price}")
def main():
get_sellers()
Ничего нового, кроме find_next(). Метод find_next() позволяет обращаться к следующему тегу, это более мощный метод, чем next_element(). next_element() в отличие от find_next() ищет следующий элемент html дерева. Например, если после тега, к которому вы применили метод next_element идет перенос строки, то вы заберете его и получите тип None.
Для того чтобы взять предыдущий элемент есть метод previous_element().
Помимо этих методов есть find_next_sibling() и find_previous_siblings() — они вернут вам теги находящиеся после и до соответственно, на одном уровне с тегом, к которому были применены эти методы. Это не все методы, которые существуют для перемещения по html дереву, все методы можно найти например в официальной документации. Возможно далее мы воспользуемся какими-нибудь еще, но на данный момент я не знаю на сколько парсеров затянется этот раздел. Просто знайте, если на странице есть какая-то информация BeautifulSoup сможет ее забрать. Мы забрали нужную нам информацию, нам хватит только ее.
Теперь хотелось бы обернуть эту информацию в телеграм бота, который будет по запросу проверят сайт и возвращать нам эту информацию. Это быстрее, чем смотреть вручную, плюс в переписке с ботом будет храниться история обращений, благодаря которой можно будет посмотреть как поменялась информация по каждому продавцу, а также видеть какие из них пропали из списка, а какие появились. Благодаря этой информации можно эффективно анализировать активность покупателей.