Сразу на входе скажу — это инструкция не для разработчиков, это инструкция для тех, кто вообще ничего не понимает в программировании, но очень хочет сделать простого бота, который бы умел искать по сайту.
Идея такой статьи появилась после того, как я сам долго гуглил и не мог найти, как вообще такое делается, а после, немного разобравшись понял, что тут все просто. Поэтому это не открытие Америки, а простая инструкция для вас, если вы не хотите разбираться, платить деньги, а просто быстро запустить простого бота. Инструкция от начала и до конца — как сделать и запустить.
Что мы получим? Получим бота ( t.me/GdeSnimali_bot ), который умеет искать по сайту и присылает пользователю ссылку на статью или набор ссылок на статьи. В названии я написал WordPress, но по идее любой сайт. который поддерживает RestApi. Показывать буду на примере своего сайта, для которого это делал (Сочтите за рекламу, ибо не зря же я статью писал — сходите и зацените сайтик). Итак есть контентный сайт gdesnimali.ru, сайт на wordpress и каждый пост там — это описание локаций того или иного фильма. Искать мы будем только по названию фильма, а оно указано в заголовке, поэтому интересует поиск только по заголовку. Мы ожидаем, что в бота человек напишет название фильма, а в ответ хочет получить все что найдет поисковик на сайте.
Создание бота в телеграм
Идем по ссылке t.me/BotFather — это чат бот для создания ботов. Там пишем /newbot, он попросит выбрать нас название для своего бота, обязательное требование, чтобы название заканчивалось на _bot, поэтому у меня gdesnimali_bot
Если название подошло, то нам покажется сообщение где будет токен, он то нам и нужен. Выглядит это примерно так:
Use this token to access the HTTP API:
5133698220:AAHqiEwVzn0lH2nrwqntlHNmYeQecGL0x
Знайте, любой кто получит этот токен сможет управлять ботом, поэтому никому его не показывайте.
Но не спешите уходить из бота, он знает еще две нужные нам команды:
/setuserpic — отправляйте команду и следом картинуку, которая будет аватаркой бота.
/setdescription — отправляйте команду и следом описание вашего бота, которое будет высвечиваться пользователю до нажатия кнопки старт. Тут важно емко и интересно описать, что бот делает, чтобы пользователь не удалил его сразу.
Адаптируем код
Итак, я не программист, поэтому кто-то может поймать депрессию от моего кода, но главное — он работает. Код просто копируем и правим пару мест
import telebot
import requests
from telebot import types
bot = telebot.TeleBot(‘ВОТ ТУТ НУЖНО ВСТАВИТЬ КОД ОТ ТЕЛЕГРАМ’)
bot.remove_webhook()
@bot.message_handler(commands=[‘start’])
def start_message(message):
user_id = message.from_user.id
pressStartButton = ‘Кнопка старт’
markup = types.ReplyKeyboardMarkup(resize_keyboard=True)
filmSearchButton = types.KeyboardButton(‘ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА’)
markup.add (filmSearchButton)
bot.send_message(message.chat.id, «ВОТ ТУТ ПРИВЕТСТВЕННОЕ СООБЩЕНИЕ БОТА ПОСЛЕ КНОПКИ СТАРТ»,
parse_mode=’html’, reply_markup=markup)
@bot.message_handler(content_types=[‘text’])
def lalala (message):
if message.chat.type == ‘private’:
if message.text == ‘ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА’:
bot.send_message(message.chat.id, ‘ВОТ ТУТ ОПИСАНИЕ ЧТО МОЖНО ИСКАТЬ’)
else:
user_id = message.from_user.id
searchQuery = message.text
url = f»ВОТ ТУТ АДРЕС ВАШЕГО САЙТА wp-json/wp/v2/posts?search={searchQuery}»
responce = requests.get(url)
if not responce.json():
bot.send_message(message.chat.id, ‘Я ничего не нашел по вашему запросу’)
for SearchResult in responce.json():
title = SearchResult[‘title’]
completeMessage = f»{title[‘rendered’]} {SearchResult[‘link’]}»
bot.send_message(message.chat.id, completeMessage)
bot.polling(none_stop=True)
Что нужно в нем поменять?
Где надпись «ВОТ ТУТ НУЖНО ВСТАВИТЬ КОД ОТ ТЕЛЕГРАМ» — нужно вставить код который вы получили в телеграм при создании бота.
Где надпись «ВОТ ТУТ АДРЕС ВАШЕГО САЙТА» — должно получиться вот так, только вначале ваш сайт — f»https://gdesnimali.ru/wp-json/wp/v2/posts?search={searchQuery}»
Где надпись «ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА» (Обратите внимание она в коде два раза, оба раза должно быть одинаково до символа» — нужно написать просто на русском запрос на поиск, у меня написано «Искать фильм» — это кнопка которая будет снизу в меню, при ее нажатии он выведет сообщение «ВОТ ТУТ ОПИСАНИЕ, ЧТО МОЖНО ИСКАТЬ» — у меня это «Введите название фильма».
Готово, теперь вам нужно просто сохранить этот код в файле питон, т.е. он должен заканчиваться на .py, например bot.py проще всего код вставить в обычный блокнот, там поправить и потом нажать «сохранить как» и сразу опубликовать с нужным форматом .py
Запуск на сервере
Бот должен где-то работать и он не может это делать на серверах телеграм.
Для своего бота я использую VPS сервер своего сайта и это было отдельным приключением все там настроить и установить. Вам я предлагаю использовать, как минимум на первое время хостинг pythoneverywhere. Он бесплатный для одного проекта. И есть отличная инструкция как запустить там бота. Я не буду ее переписывать, просто используйте код полуенный выше вместо кода в инструкции.
Спасибо за внимание — надеюсь у вас получится отличный бот!
Время на прочтение
3 мин
Количество просмотров 6.8K
Сразу на входе скажу — это инструкция не для разработчиков, это инструкция для тех, кто вообще ничего не понимает в программировании, но очень хочет сделать простого бота, который бы умел искать по сайту. Идея такой статьи появилась после того, как я сам долго гуглил и не мог найти, как вообще такое делается, а после, немного разобравшись понял, что тут все просто. Поэтому это не открытие Америки, а простая инструкция для вас, если вы не хотите разбираться, платить деньги, а просто быстро запустить простого бота. Инструкция от начала и до конца — как сделать и запустить.
Что получим?
Что мы получим? Получим бота ( пример бота), который умеет искать по сайту и присылает пользователю ссылку на статью или набор ссылок на статьи. В названии я написал WordPress, но по идее любой сайт. который поддерживает RestApi. Показывать буду на примере своего сайта, для которого это делал. Итак есть контентный сайт gdesnimali.ru, сайт на wordpress и каждый пост там — это описание локаций того или иного фильма. Искать мы будем только по названию фильма, а оно указано в заголовке, поэтому интересует поиск только по заголовку. Мы ожидаем, что в бота человек напишет название фильма, а в ответ хочет получить все что найдет поисковик на сайте.
Создание бота в телеграм
Идем по ссылке t.me/BotFather — это чат бот для создания ботов. Там пишем /newbot, он попросит выбрать нас название для своего бота, обязательное требование, чтобы название заканчивалось на _bot, поэтому у меня gdesnimali_bot
Если название подошло, то нам покажется сообщение где будет токен, он то нам и нужен. Выглядит это примерно так:
Use this token to access the HTTP API:
5133698220:AAHqiEwVzn0lH2nrwqntlHNmYeQecGL0x
Знайте, любой кто получит этот токен сможет управлять ботом, поэтому никому его не показывайте.
Но не спешите уходить из бота, он знает еще две нужные нам команды:
/setuserpic — отправляйте команду и следом картинуку, которая будет аватаркой бота.
/setdescription — отправляйте команду и следом описание вашего бота, которое будет высвечиваться пользователю до нажатия кнопки старт. Тут важно емко и интересно описать, что бот делает, чтобы пользователь не удалил его сразу.
Адаптируем код
Итак, я не программист, поэтому кто-то может уйти в депрессию от моего кода, но главное — он работает. Код просто копируем и правим пару мест
import telebot
import requests
from telebot import types
bot = telebot.TeleBot('ВОТ ТУТ НУЖНО ВСТАВИТЬ КОД ОТ ТЕЛЕГРАМ')
bot.remove_webhook()
@bot.message_handler(commands=['start'])
def start_message(message):
user_id = message.from_user.id
pressStartButton = 'Кнопка старт'
markup = types.ReplyKeyboardMarkup(resize_keyboard=True)
filmSearchButton = types.KeyboardButton('ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА')
markup.add (filmSearchButton)
bot.send_message(message.chat.id, "ВОТ ТУТ ПРИВЕТСТВЕННОЕ СООБЩЕНИЕ БОТА ПОСЛЕ КНОПКИ СТАРТ",
parse_mode='html', reply_markup=markup)
@bot.message_handler(content_types=['text'])
def lalala (message):
if message.chat.type == 'private':
if message.text == 'ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА':
bot.send_message(message.chat.id, 'ВОТ ТУТ ОПИСАНИЕ ЧТО МОЖНО ИСКАТЬ')
else:
user_id = message.from_user.id
searchQuery = message.text
url = f"ВОТ ТУТ АДРЕС ВАШЕГО САЙТА wp-json/wp/v2/posts?search={searchQuery}"
responce = requests.get(url)
if not responce.json():
bot.send_message(message.chat.id, 'Я ничего не нашел по вашему запросу')
for SearchResult in responce.json():
title = SearchResult['title']
completeMessage = f"{title['rendered']} {SearchResult['link']}"
bot.send_message(message.chat.id, completeMessage)
bot.polling(none_stop=True)Что нужно в нем поменять?
Где надпись «ВОТ ТУТ НУЖНО ВСТАВИТЬ КОД ОТ ТЕЛЕГРАМ» — нужно вставить код который вы получили в телеграм при создании бота.
Где надпись «ВОТ ТУТ АДРЕС ВАШЕГО САЙТА» — должно получиться вот так, только вначале ваш сайт — f»https://gdesnimali.ru/wp-json/wp/v2/posts?search={searchQuery}»
Где надпись «ВОТ ТУТ КНОПКА ДЛЯ СТАРТА ПОИСКА» (Обратите внимание она в коде два раза, оба раза должно быть одинаково до символа» — нужно написать просто на русском запрос на поиск, у меня написано «Искать фильм» — это кнопка которая будет снизу в меню, при ее нажатии он выведет сообщение «ВОТ ТУТ ОПИСАНИЕ, ЧТО МОЖНО ИСКАТЬ» — у меня это «Введите название фильма».
Готово, теперь вам нужно просто сохранить этот код в файле питон, т.е. он должен заканчиваться на .py, например bot.py проще всего код вставить в обычный блокнот, там поправить и потом нажать «сохранить как» и сразу опубликовать с нужным форматом .py
Запуск на сервере
Бот должен где-то работать и он не может это делать на серверах телеграм.
Для своего бота я использую VPS сервер своего сайта и это было отдельным приключением все там настроить и установить. Вам я предлагаю использовать, как минимум на первое время хостинг pythoneverywhere. Он бесплатный для одного проекта. И есть отличная инструкция как запустить там бота. Я не буду ее переписывать, просто используйте код полуенный выше вместо кода в инструкции (Например эта: ссылка на инструкцию).

by Quinn Langille
Apartment hunting sucks, especially in Montreal. This guide will show you how to build a bot that stays on top of the hunt for you. This way, you’ll never have to endlessly refresh your searches again.
Context
Unlike other cities, most people who rent apartments in Montreal are on the same lease term. New leases start in July, last 12 months, and end on June 30th. While one could argue that this simplifies a lot of things — such as availability and expectations — it also means that competition is steep.
Every day I would wake up, refresh my 10 open Kijiji pages, and send emails inquiring about all the new ads. I would do this again at lunch, dinner, and before bed. My reply rate was low — well below 10%. When someone did reply, their answer was usually grim.
My next step was to up the ante and actually pick up the phone. Calling made my chances a little better. Landlords were more responsive, and this time there were usually less than 10 people ahead of me. But definitely still more than 5. Back to the drawing board.
One day, while complaining to a coworker that all my time was getting eaten by this apartment hunt — it dawned on me. I could I solve this problem with my computer.
When I got home I wrote a small program that watches Kijiji searches for changes. When it sees them, it sends a Short Message Service (SMS) text to my phone with the relevant information. The rest of this article will explain how I did that.
Note: for those who don’t care about the tutorial, I’ve put the Kijiji scraper up as an open source repo here: ?
Building Pad-Patrol
When I arrived home from work, I got my laptop out and fired up my terminal. I knew the program should be lightweight, as I’ll be running it 24/7 — or at least until I find an apartment. I decided to just build a simple node script that I could execute from my terminal.
Setup
Assuming that you have node and npm installed, the first step — of any node project — is to initialize npm inside the project directory.
Next, let’s create an src directory where our code will live.
Inside thesrc directory, make an index.js file where our script will go.
You can do that like so:
$ npm init // this will ask a few questions$ mkdir src$ cd src && touch index.jsWriting the script
When making a solo project I tend to freestyle — breaking stuff and then fixing it (arguably the best way to learn). I’m going to try to mimic my initial thought process with the following instructions, but let me know if they seem all over the place.
The very first thing we have to do is make a successful request to Kijiji. To ensure that we’re able to get a proper response, let’s make a very basic fetch.
To do that, we’ll need to install a request library:
$ npm install request-promiseand then add the following to index.js:
Once that’s saved, we can run $ node src/index.js and we should see some HTML markup in our console. Step one complete — Easy!
Because we only care when content changes, lets make a simple hash of the response. That way, we can compare the response and compare the hashes. In the event we need to log our results, this will be much less cumbersome than the raw markup.
To do this, we can use a hashing tool called checksum:
$ yarn add checksumand then:
Ok cool, this worked! Our 1500 lines of HTML has been cut down to 32 digits. Now, let’s wrap it in a reusable function:
The above code will create a hash from the fetched value. Then on the following fetch, it will compare the original and new hashes.
If they’re different, it will return true. This worked great…like, a little too great. As you’ll see, it returns true every time ?
After further inspection of the response from the fetch, we can see that Kijiji has a timestamp in the header. This means that the hash will be different on every fetch. It’s important to note that this would have also happened due to rotating ads and a bunch of other dynamic content.
The takeaway from the above oversight is to always carefully inspect your response when dealing with an API you didn’t write.
This mean’s we’ll need to access granular bits of the markup, so let’s install a third party package to help parse the response. Cheerio is a library that can ingest HTML markup and turn it into an accessible JavaScript API. It’s intended purpose was to help jQuery developers not use jQuery, but intentions are overrated.
For us, it’s going to be a fake set of Chrome Developer Tools!
As a pre-requisite to using Cheerio in this way, we need to know what to look for in our markup. So let’s bust open Chrome and inspect our URL.
If we inspect at the ads, we can see all search responses have the classes .search-item and .regular-ad. Perfect!
We can select those with Cheerio like so:
Just like we had planned, this spits out an array of neatly organized objects. According to Cheerio’s documentation, all attributes of an element are nested in a key called attribs. If we go back to the Chrome Developer Tools, we can see that each ad has a unique data-attribute called ID. Let’s target that — replace the code inside your checkURL function with the following:
rp(siteToCheck).then(response => { const $ = co.load(HTMLresponse); let apartmentString = ""; // use cheerio to parse HTML response and find all search results $(".search-item.regular-ad").each((i, element) => { console.log(element.attribs["data-ad-id"]); });});Ok great, we’re getting a list of unique ID numbers. These ID’s are the only information we care about on the page.
So let’s go back to our original plan of comparing hashes, except we’ll only hash the unique IDs:
Perfect! It’s working exactly as intended. When someone posts a new ad (or removes an old ad, a caveat of watching the order of IDs) we print true in our console. All that’s left to do it set up our SMS tool.
Sending SMS from the Terminal
This is actually much easier than it seems. To do this we’ll use a third party software called Twilio. It does a lot, but one of it’s core features is to send SMS. As a bonus, it also has great JavaScript API! To finish the tutorial, you’ll need one of their accounts — a free trial will be more than enough to play around — and maybe even get a new apartment.
Ok, so to start we need to run:
$ yarn add twiliofrom there, in index.js lets add Twilio and define a new function called SMS:
const twilio = require(twilio);// you'll need to get your own credentials for this oneconst client = new Twilio("accountID", "authKey");function SMS({ body, to, from }) { client.messages .create({ body, to, from }) .then(() => { console.log(`? Success! Message has been sent to ${to}`); }) .catch(err => { console.log(err); });} This simple function takes two phone numbers (to and from) and a message (body). Instead of console logging the result of our checkURL function, we can call SMS with whatever message we want:
There you have it! Every time our script sees a change between the site hashes, it will send a text message with the URL right to your phone ?.
Happy Hunting!
The actual script that I’ve built is a little more complicated than the above example — I’ve put it up as an open source repo on GitHub.
Eventually, I’d like to make some additions to it — the first of which will be making it more generic and not just a Kijiji scraper. It’s pretty basic, so it will be a great first-time project for new contributors.
Feel free to contribute in any way you see fit ?
Also, in case anyone was wondering, I just signed a lease last Sunday. The apartment I ended up renting was from the very first update pad-patrol sent me — it was destiny ✨
I’m currently working as a software developer at luxury fashion company in Montreal. I’ve been doing that for about a year, after finishing a web dev bootcamp last summer. I spend my free time learning hot new tech and, up until a few days ago, hunting for apartments.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
by Quinn Langille
Apartment hunting sucks, especially in Montreal. This guide will show you how to build a bot that stays on top of the hunt for you. This way, you’ll never have to endlessly refresh your searches again.
Context
Unlike other cities, most people who rent apartments in Montreal are on the same lease term. New leases start in July, last 12 months, and end on June 30th. While one could argue that this simplifies a lot of things — such as availability and expectations — it also means that competition is steep.
Every day I would wake up, refresh my 10 open Kijiji pages, and send emails inquiring about all the new ads. I would do this again at lunch, dinner, and before bed. My reply rate was low — well below 10%. When someone did reply, their answer was usually grim.
My next step was to up the ante and actually pick up the phone. Calling made my chances a little better. Landlords were more responsive, and this time there were usually less than 10 people ahead of me. But definitely still more than 5. Back to the drawing board.
One day, while complaining to a coworker that all my time was getting eaten by this apartment hunt — it dawned on me. I could I solve this problem with my computer.
When I got home I wrote a small program that watches Kijiji searches for changes. When it sees them, it sends a Short Message Service (SMS) text to my phone with the relevant information. The rest of this article will explain how I did that.
Note: for those who don’t care about the tutorial, I’ve put the Kijiji scraper up as an open source repo here: ?
Building Pad-Patrol
When I arrived home from work, I got my laptop out and fired up my terminal. I knew the program should be lightweight, as I’ll be running it 24/7 — or at least until I find an apartment. I decided to just build a simple node script that I could execute from my terminal.
Setup
Assuming that you have node and npm installed, the first step — of any node project — is to initialize npm inside the project directory.
Next, let’s create an src directory where our code will live.
Inside thesrc directory, make an index.js file where our script will go.
You can do that like so:
$ npm init // this will ask a few questions$ mkdir src$ cd src && touch index.jsWriting the script
When making a solo project I tend to freestyle — breaking stuff and then fixing it (arguably the best way to learn). I’m going to try to mimic my initial thought process with the following instructions, but let me know if they seem all over the place.
The very first thing we have to do is make a successful request to Kijiji. To ensure that we’re able to get a proper response, let’s make a very basic fetch.
To do that, we’ll need to install a request library:
$ npm install request-promiseand then add the following to index.js:
Once that’s saved, we can run $ node src/index.js and we should see some HTML markup in our console. Step one complete — Easy!
Because we only care when content changes, lets make a simple hash of the response. That way, we can compare the response and compare the hashes. In the event we need to log our results, this will be much less cumbersome than the raw markup.
To do this, we can use a hashing tool called checksum:
$ yarn add checksumand then:
Ok cool, this worked! Our 1500 lines of HTML has been cut down to 32 digits. Now, let’s wrap it in a reusable function:
The above code will create a hash from the fetched value. Then on the following fetch, it will compare the original and new hashes.
If they’re different, it will return true. This worked great…like, a little too great. As you’ll see, it returns true every time ?
After further inspection of the response from the fetch, we can see that Kijiji has a timestamp in the header. This means that the hash will be different on every fetch. It’s important to note that this would have also happened due to rotating ads and a bunch of other dynamic content.
The takeaway from the above oversight is to always carefully inspect your response when dealing with an API you didn’t write.
This mean’s we’ll need to access granular bits of the markup, so let’s install a third party package to help parse the response. Cheerio is a library that can ingest HTML markup and turn it into an accessible JavaScript API. It’s intended purpose was to help jQuery developers not use jQuery, but intentions are overrated.
For us, it’s going to be a fake set of Chrome Developer Tools!
As a pre-requisite to using Cheerio in this way, we need to know what to look for in our markup. So let’s bust open Chrome and inspect our URL.
If we inspect at the ads, we can see all search responses have the classes .search-item and .regular-ad. Perfect!
We can select those with Cheerio like so:
Just like we had planned, this spits out an array of neatly organized objects. According to Cheerio’s documentation, all attributes of an element are nested in a key called attribs. If we go back to the Chrome Developer Tools, we can see that each ad has a unique data-attribute called ID. Let’s target that — replace the code inside your checkURL function with the following:
rp(siteToCheck).then(response => { const $ = co.load(HTMLresponse); let apartmentString = ""; // use cheerio to parse HTML response and find all search results $(".search-item.regular-ad").each((i, element) => { console.log(element.attribs["data-ad-id"]); });});Ok great, we’re getting a list of unique ID numbers. These ID’s are the only information we care about on the page.
So let’s go back to our original plan of comparing hashes, except we’ll only hash the unique IDs:
Perfect! It’s working exactly as intended. When someone posts a new ad (or removes an old ad, a caveat of watching the order of IDs) we print true in our console. All that’s left to do it set up our SMS tool.
Sending SMS from the Terminal
This is actually much easier than it seems. To do this we’ll use a third party software called Twilio. It does a lot, but one of it’s core features is to send SMS. As a bonus, it also has great JavaScript API! To finish the tutorial, you’ll need one of their accounts — a free trial will be more than enough to play around — and maybe even get a new apartment.
Ok, so to start we need to run:
$ yarn add twiliofrom there, in index.js lets add Twilio and define a new function called SMS:
const twilio = require(twilio);// you'll need to get your own credentials for this oneconst client = new Twilio("accountID", "authKey");function SMS({ body, to, from }) { client.messages .create({ body, to, from }) .then(() => { console.log(`? Success! Message has been sent to ${to}`); }) .catch(err => { console.log(err); });} This simple function takes two phone numbers (to and from) and a message (body). Instead of console logging the result of our checkURL function, we can call SMS with whatever message we want:
There you have it! Every time our script sees a change between the site hashes, it will send a text message with the URL right to your phone ?.
Happy Hunting!
The actual script that I’ve built is a little more complicated than the above example — I’ve put it up as an open source repo on GitHub.
Eventually, I’d like to make some additions to it — the first of which will be making it more generic and not just a Kijiji scraper. It’s pretty basic, so it will be a great first-time project for new contributors.
Feel free to contribute in any way you see fit ?
Also, in case anyone was wondering, I just signed a lease last Sunday. The apartment I ended up renting was from the very first update pad-patrol sent me — it was destiny ✨
I’m currently working as a software developer at luxury fashion company in Montreal. I’ve been doing that for about a year, after finishing a web dev bootcamp last summer. I spend my free time learning hot new tech and, up until a few days ago, hunting for apartments.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started

Сегодня мы собираемся создать ChatBot API и веб-интерфейс на Python 3. ChatBots сложно построить, потому что существует бесконечное количество входных параметров. Из-за этого ChatBot, который может последовательно придумывать хорошие ответы, требует огромных знаний.
Разработчики часто применяют алгоритмы машинного обучения, NLP и совокупность предопределенных ответов в своей конструкции системы ChatBot. Мы собираемся сохранить наш код базовым, поэтому будем обходить создание сложного «мозга» для нашего ChatBot.
Вместо того, чтобы строить мозг ИИ, мы будем использовать тот, который бесплатен и уже создан: поиск Google.
Наш ChatBot выполнит поиск Google по запросу пользователя, очистит текст от первого результата и ответит пользователю первым предложением текста этой страницы.
Запросы в Google с помощью Python
Чтобы запрограммировать нашего простого ChatBot с всеведением (бесконечное знание), мы будем выполнять поиск в Google с помощью Python. К счастью, есть библиотека Python для поиска Google, которую мы можем установить с помощью pip.
После локальной установки библиотеки Google вы можете написать следующий код:
from googlesearch import search query = 'how old is samuel l jackson' ## Google Search query results as a Python List of URLs search_result_list = list(search(query, tld="co.in", num=10, stop=3, pause=1))
Получив список URL-адресов из результатов поиска, мы можем выполнить запрос GET для этой веб-страницы с помощью библиотеки запросов Python. Мы также можем разобрать HTML с помощью html из LXML, а также BeautifulSoup.
import requests from lxml import html from googlesearch import search from bs4 import BeautifulSoup query = 'how old is samuel l jackson' ## Google Search query results as a Python List of URLs search_result_list = list(search(query, tld="co.in", num=10, stop=3, pause=1)) page = requests.get(search_result_list[index]) tree = html.fromstring(page.content) soup = BeautifulSoup(page.content, features="lxml")
Все зависимости Python этого проекта можно найти в requirements.txt на GitHub.
Вот готовый файл, который наш HTTP-сервер может импортировать как зависимость. Я создал метод, который выполняет поиск в Google, получает первый
на веб-странице и возвращает его содержимое в виде строки. Если поиск не удастся каким-либо образом, ChatBot ответит: «Извините, я не могу придумать ответ для этого».
import requests
import string
from lxml import html
from googlesearch import search
from bs4 import BeautifulSoup
# to search
# print(chatbot_query('how old is samuel l jackson'))
def chatbot_query(query, index=0):
fallback = 'Sorry, I cannot think of a reply for that.'
result = ''
try:
search_result_list = list(search(query, tld="co.in", num=10, stop=3, pause=1))
page = requests.get(search_result_list[index])
tree = html.fromstring(page.content)
soup = BeautifulSoup(page.content, features="lxml")
article_text = ''
article = soup.findAll('p')
for element in article:
article_text += 'n' + ''.join(element.findAll(text = True))
article_text = article_text.replace('n', '')
first_sentence = article_text.split('.')
first_sentence = first_sentence[0].split('?')[0]
chars_without_whitespace = first_sentence.translate(
{ ord(c): None for c in string.whitespace }
)
if len(chars_without_whitespace) > 0:
result = first_sentence
else:
result = fallback
return result
except:
if len(result) == 0: result = fallback
return result
Теперь мы можем принять пользовательский ввод и выполнить поиск Google. Мы сделаем HTTP-запрос GET к первому результату поиска. Затем мы анализируем возвращенный HTML-код и выделяем первое предложение в первом
на этой странице. Это алгоритм ответа нашего ChatBot, машинного обучения не требуется.
Python API для простого ChatBot
Далее нам нужно создать серверное приложение, которое будет нашим API для запросов ChatBot. Он будет обслуживать ответы на HTTP-запросы. Для начала эти запросы будут поступать с простой HTML-страницы, которую мы сделаем позже.
Для начала мы импортируем библиотеки Python 3 HTTP server и socket server вместе с поисковым файлом Google, который мы сделали ранее.
import http.server import socketserver from google_search import chatbot_query PORT = 8080 DIRECTORY = 'public'
Наш API будет обслуживаться через порт 8080, и мы будем обслуживать ресурсы веб-страниц из папки, которая называется public в родительском каталоге нашего проекта. Далее мы сделаем наш собственный обработчик для запросов GET и POST.
HTTP GET-запросы попытаются вернуть соответствующий файл из папки public. Это будут файлы HTML, CSS и JavaScript для нашего интерфейса веб-браузера. POST-запросы будут использоваться для запросов ChatBot.
class Handler(http.server.SimpleHTTPRequestHandler):
def __init__(self, *args, **kwargs):
super().__init__(*args, directory=DIRECTORY, **kwargs)
def do_POST(self):
self.send_response(200)
content_length = int(self.headers['Content-Length'])
post_body = self.rfile.read(content_length)
self.end_headers()
print('user query', post_body)
google_search_chatbot_reply = chatbot_query(post_body)
self.wfile.write(str.encode(google_search_chatbot_reply))
Наконец, мы запустим сервер и используем наш обработчик. Вот весь файл, включая приведенные фрагменты кода.
import http.server
import socketserver
from google_search import chatbot_queryPORT = 8080
DIRECTORY = 'public'
class Handler(http.server.SimpleHTTPRequestHandler):
def __init__(self, *args, **kwargs):
super().__init__(*args, directory=DIRECTORY, **kwargs)
def do_POST(self):
self.send_response(200)
content_length = int(self.headers['Content-Length'])
post_body = self.rfile.read(content_length)
self.end_headers()
print('user query', post_body)
google_search_chatbot_reply = chatbot_query(post_body)
self.wfile.write(str.encode(google_search_chatbot_reply))
with socketserver.TCPServer(('', PORT), Handler) as httpd:
print('serving at port', PORT)
try:
httpd.serve_forever()
except KeyboardInterrupt:
pass
httpd.server_close()
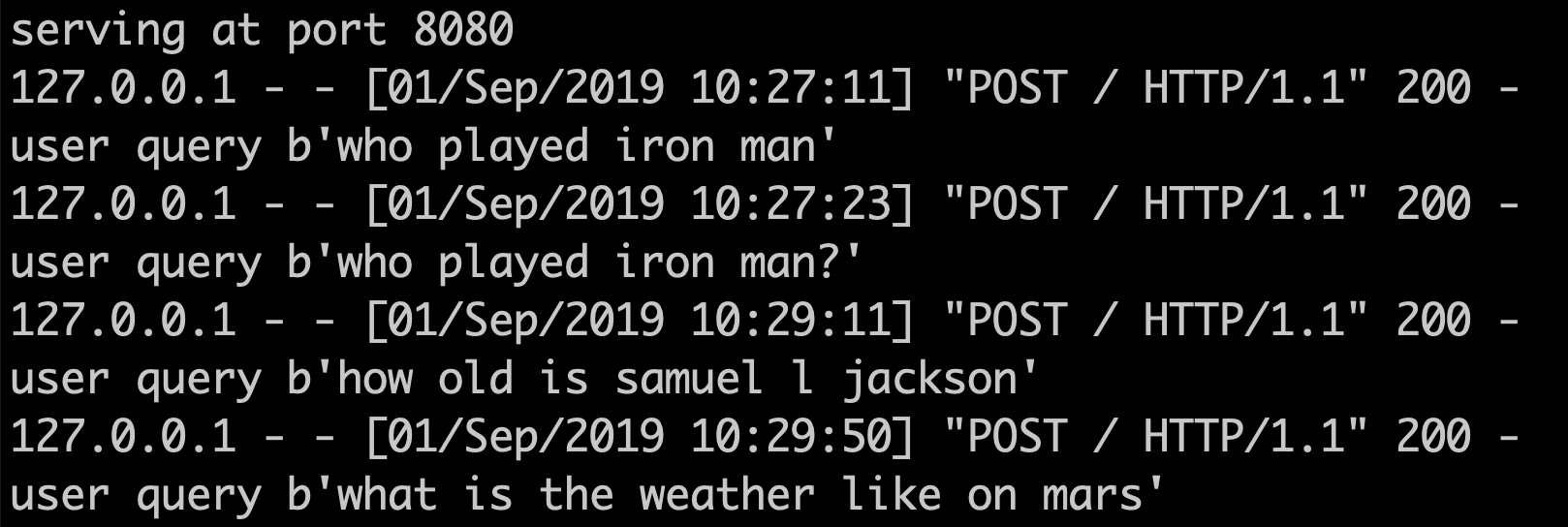
Мы можем использовать CURL для тестирования ChatBot API с запросами POST.
curl -d "how old is samuel l jackson" http://localhost:8080
Далее мы создадим HTML-страницу, которая может запрашивать этот API. К концу у нас будет сквозной чат-бот, который предоставляет сложные ответы.
Создание веб-страницы ChatBot
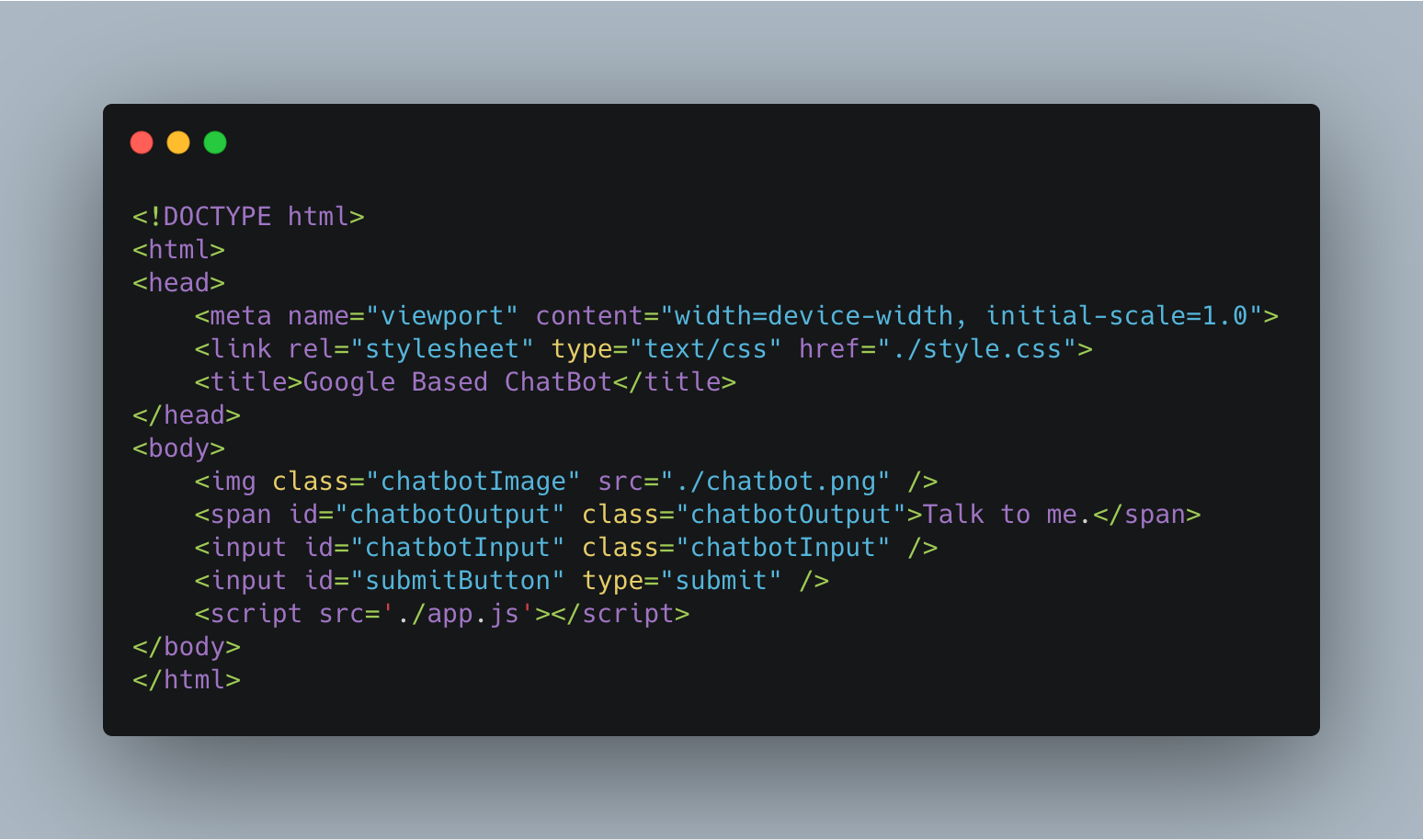
Наша веб-страница будет очень простой. Она будет содержать изображение бота, поле для ввода текста и кнопку отправки. Всякий раз, когда пользователь отправляет ввод, API-интерфейс chatbot будет доступен через запрос POST. Текстовый ответ, который возвращается из API, будет заполнен на веб-странице.
Вот HTML-страница. Сохраните его как index.html в папке public, которую мы упоминали ранее. Файл образа бота также находится в полном репозитории Python ChatBot GitHub.
Далее мы добавим несколько стилей для этой веб-страницы. Сохраните этот файл CSS в папке public. На него уже ссылается HTML-файле в .
html, body {
margin: 0px;
width: 100vw;
height: 100vh;
font-family: arial;
overflow: hidden;
}
.chatbotImage {
margin-top: 40px;
width: 35vw;
}
.chatbotOutput {
font-size: 45px;
}
.chatbotInput {
margin-top: 10px;
width: 55vw;
padding: 20px;
font-size: 25px;
}
input,
span,
img {
display: block;
margin: auto;
text-align: center;
}
Теперь у вас должна быть простая веб-страница ChatBot, готовая для ввода пользователем. Вот скриншот:

Веб-страница не совсем готова для пользователей. Требуется JavaScript.
Мы напишем несколько JS, которые обнаружат, что пользователь нажимает клавишу Return и также нажимает кнопку отправки. Когда произойдет любое из этих событий, мы получим текст внутри поля ввода пользователя и включим его в качестве тела POST для нашего сервера Python.
Мы сделаем POST запрос к API сервера, используя метод fetch. Fetch API теперь включен по умолчанию в современных веб-браузерах.
Вот наш простой JavaScript, который взаимодействует с нашими 3 HTML-элементами. Сохраните этот код как app.js в общей папке.
const submitButton = document.getElementById('submitButton');
const chatbotInput = document.getElementById('chatbotInput');
const chatbotOutput = document.getElementById('chatbotOutput');
submitButton.onclick = userSubmitEventHandler;
chatbotInput.onkeyup = userSubmitEventHandler;
function userSubmitEventHandler(event) {
if (
(event.keyCode && event.keyCode === 13) ||
event.type === 'click'
) {
chatbotOutput.innerText = 'thinking...';
askChatBot(chatbotInput.value);
}
}
function askChatBot(userInput) {
const myRequest = new Request('/', {
method: 'POST',
body: userInput
});
fetch(myRequest).then(function(response) {
if (!response.ok) {
throw new Error('HTTP error, status = ' + response.status);
} else {
return response.text();
}
}).then(function(text) {
chatbotInput.value = '';
chatbotOutput.innerText = text;
}).catch((err) => {
console.error(err);
});
}
Мы почти готовы запустить наш ChatBot.
Запуск нашего простого Python ChatBot, созданного с нуля
Теперь, когда мы написали весь код, у нас есть еще один шаг, прежде чем мы сможем запустить ChatBot. Если вы этого еще не сделали, создайте файл requirements.txt в родительском каталоге проекта вместе с двумя файлами Python. Этот файл представляет собой парадигму Python для простой установки зависимостей проекта.
requests==2.22.0 lxml==4.4.1 google==2.0.2 beautifulsoup4==4.8.0
Перейдите в родительский каталог проекта ChatBot с помощью командной строки. запустите команду установки библиотеки Python.
pip install -r requirements.txt
Теперь на вашем компьютере есть все необходимые библиотеки для запуска ChatBot! Давайте запустим приложение с полным стеком.
python server.py
Затем откройте веб-браузер и перейдите по адресу http://localhost:8080/. Если вы видите изображение ChatBot, оно работает.
Попробуйте некоторые входы!
кто играл железного человека
сколько лет Сэмюэлю Л Джексону
какая погода на марсе
Как видите, наши ответы на ChatBot не идеальны, но довольно хороши для нескольких минут работы.

Форум программистов Vingrad
| Модераторы: feodorv |
Поиск: |
  
|
|
Опции темы |

| Гвоздь |
|
||
|
Новичок Профиль Репутация: нет
|
Вот задумался над тем, как написать своего собственного поискового бота на C++. То бишь, с чего начать, какую литературу можно почитать на тему и т.д? Может кто знает? Может кто поможет? Заранее спасибо! |
||
|
|||
 Дата 4.11.2005, 17:19 (ссылка)
Дата 4.11.2005, 17:19 (ссылка)









| Coocky |
|
||

GUI гуру Профиль
Репутация: нет
|
В чем искать(что?) ——————— Верю в смерть после жизни, в любовь после секса ,в крем после бритья |
||
|
|||


| Гвоздь |
|
||
|
Новичок Профиль Репутация: нет
|
ну как в чём(что?) по сайтам, чтобы сам передвигался, ну то бишь по ссылкам и если ссылок нету, то искал из базы данных ссылки зарегиных ресурсов и шёл туда, а искал информацию, ну как поисковые боты. =) |
||
|
|||
| Coocky |
|
||
|
GUI гуру Профиль
Репутация: нет
|
А, ну это ерунда.. ——————— Верю в смерть после жизни, в любовь после секса ,в крем после бритья |
||
|
|||
| Гвоздь |
|
||
|
Новичок Профиль Репутация: нет
|
Мда… помог Спасибо! А в инете есть вообще литература про это? ну то есть про то, как написать бота? В поисковике не нашёл! |
||
|
|||

| _hunter |
|
||

Эксперт Профиль
Репутация: нет
|
лучше, конечно. литература есть. ——————— Tempora mutantur, et nos mutamur in illis… |
||
|
|||
| Coocky |
|
||||||
|
GUI гуру Профиль
Репутация: нет
|
Долго..
Посмотри у нас есть раздел компьютерная литература. Найдеш и по С и по сетям, я думаю…
Литературы нет, это точно ——————— Верю в смерть после жизни, в любовь после секса ,в крем после бритья |
||||||
|
|||||||

| DeadSoul |
|
||
|
Эксперт Профиль
Репутация: нет
|
Гвоздь, эту задачу нужно решать на perlе, а не на Си++ ——————— Если Вы получили ответ на Ваш вопрос, то нажмите на «Вопрос решен». Бьем спамеров их же оружием. Пусть весь спам сыпется им |
||
|
|||
| dwr_budr |
|
||

Шустрый Профиль Репутация: нет
|
На Перле примитивный бот пишется довольно легко. 1. С помощью lynx’а или еще чего-нить получаешь содержимое страницы. Непримитивный вариант конечно будет посложнее. Но как по мне большее количество времени уйдет не на сетевые апи и парсинг строк, а на саму систему поиска для которой этот бот будет трудиться, т.е. на вопросы связаные с эффективной организацией базы которая будет это все дело хранить и позволять с ним эффективно и осмысленно работать. Но это уже в другой форум |
||
|
|||

| Гвоздь |
|
||
|
Новичок Профиль Репутация: нет
|
А как насчёт PHP, вообще возможно на ПХП такое написать? А то я более в ПХП разбераюсь, а не в Перл. |
||
|
|||
| DeadSoul |
|
||
|
Эксперт Профиль
Репутация: нет
|
Не знаю. php не щупал. На перле весь код программы займет экрана два ——————— Если Вы получили ответ на Ваш вопрос, то нажмите на «Вопрос решен». Бьем спамеров их же оружием. Пусть весь спам сыпется им |
||
|
|||



















|
|
| 0 Пользователей читают эту тему (0 Гостей и 0 Скрытых Пользователей) |
| 0 Пользователей: |
| « Предыдущая тема | C/C++: Сети | Следующая тема » |
Всем привет!
Давно хотел сделать своего собственного Jarvis. Недавно удалась свободная минутка и я его сделал. Он умеет переписываться с Вами, а также искать ответы на Ваши вопросы в Wikipedia. Для его реализации я использовал язык Python.
Для начала установим все необходимые библиотеки. Их три: pyTelegramBotAPI, scikit-learn, а также Wikipedia. Устанавливаются они просто:
pip install pyTelegramBotAPIpip install Wikipediapip install scikit-learnПосле установки всех библиотек приступаем к разработке. Для начала импортируем все библиотеки, установим язык для Википедии и подключим телеграмм бота
import telebot, wikipedia, re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
wikipedia.set_lang("ru")
bot = telebot.TeleBot('Ваш ключ, полученный от BotFather')Теперь напишем код, для очистки всех ненужных нам знаков, которые вводит пользователь:
def clean_str(r):
r = r.lower()
r = [c for c in r if c in alphabet]
return ''.join(r)
alphabet = ' 1234567890-йцукенгшщзхъфывапролджэячсмитьбюёqwertyuiopasdfghjklzxcvbnm?%.,()!:;'Также Вам необходимо создать в папке, где находится Ваш код файл dialogues.txt, в нем мы будем создавать реплики на которые должен отвечать бот. Вот пример данного файла:
приветздравствуйте!
как делахорошо.
кто тыя Джарвис.Строка до знака означает вопрос пользователя, а после ответ нашего бота. После чего напишем такой код в наш файл с ботом:
def update():
with open('dialogues.txt', encoding='utf-8') as f:
content = f.read()
blocks = content.split('n')
dataset = []
for block in blocks:
replicas = block.split('\')[:2]
if len(replicas) == 2:
pair = [clean_str(replicas[0]), clean_str(replicas[1])]
if pair[0] and pair[1]:
dataset.append(pair)
X_text = []
y = []
for question, answer in dataset[:10000]:
X_text.append(question)
y += [answer]
global vectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X_text)
global clf
clf = LogisticRegression()
clf.fit(X, y)
update()Этот кусок кода читает файл dialogues.txt, потом превращает реплики в так называемые вектора, с помощью которых наш бот будет искать наиболее подходящий ответ к заданному нами вопросу. Например, если Вы написали в файле dialogues.txt вопрос «Ты знаешь Аню», а ответ на него «Да, конечно», то бот будет отвечать также и на похожие вопросы, например «Ты знаешь Васю».
Теперь напишем кусок кода, который будет генерировать ответы на основе векторов:
def get_generative_replica(text):
text_vector = vectorizer.transform([text]).toarray()[0]
question = clf.predict([text_vector])[0]
return questionЭтот кусок кода принимает вопрос от пользователя и возвращает ответ от бота.
Теперь напишем функцию для поиска информации в Википедии:
def getwiki(s):
try:
ny = wikipedia.page(s)
wikitext=ny.content[:1000]
wikimas=wikitext.split('.')
wikimas = wikimas[:-1]
wikitext2 = ''
for x in wikimas:
if not('==' in x):
if(len((x.strip()))>3):
wikitext2=wikitext2+x+'.'
else:
break
wikitext2=re.sub('([^()]*)', '', wikitext2)
wikitext2=re.sub('([^()]*)', '', wikitext2)
wikitext2=re.sub('{[^{}]*}', '', wikitext2)
return wikitext2
except Exception as e:
return 'В Википедии нет информации об этом'Этот кусок кода получает вопрос пользователя, потом ищет ответ на него в Википедии и если ответ найден, то отдает его пользователю, а если ответ не найден, то пишет, что «В Википедии нет информации об этом».
Теперь пишем последний кусок кода:
@bot.message_handler(commands=['start'])
def start_message(message):
bot.send_message(message.chat.id,"Здравствуйте, Сэр.")
question = ""
@bot.message_handler(content_types=['text'])
def get_text_messages(message):
command = message.text.lower()
if command =="не так":
bot.send_message(message.from_user.id, "а как?")
bot.register_next_step_handler(message, wrong)
else:
global question
question = command
reply = get_generative_replica(command)
if reply=="вики ":
bot.send_message(message.from_user.id, getwiki(command))
else:
bot.send_message(message.from_user.id, reply)
def wrong(message):
a = f"{question}{message.text.lower()} n"
with open('dialogues.txt', "a", encoding='utf-8') as f:
f.write(a)
bot.send_message(message.from_user.id, "Готово")
update()В этом куске кода телеграмм бот при получении сообщения от пользователя отвечает на него и если ответ не верный, то пользователь пишет «не так». Если бот получает сообщение «не так», то он берет последний вопрос пользователя и спрашивает «а как?», после чего пользователь должен отправить ему правильный ответ. После этого бот обновляет свою базу данных вопросов и ответов и при следующих вопросах пользователя отвечает на них правильно. И если ответ на вопрос бот должен был взять из Википедии, то пользователь в ответ на вопрос «а как?», должен написать «wiki». Осталось в конце приписать строчку:
bot.polling(none_stop=True)И можно запускать и тестировать бота.
Весь код файла с ботом прилагаю ниже:
import telebot, wikipedia, re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
bot = telebot.TeleBot('Ваш ключ от BotFather')
wikipedia.set_lang("ru")
def clean_str(r):
r = r.lower()
r = [c for c in r if c in alphabet]
return ''.join(r)
alphabet = ' 1234567890-йцукенгшщзхъфывапролджэячсмитьбюёqwertyuiopasdfghjklzxcvbnm?%.,()!:;'
def update():
with open('dialogues.txt', encoding='utf-8') as f:
content = f.read()
blocks = content.split('n')
dataset = []
for block in blocks:
replicas = block.split('\')[:2]
if len(replicas) == 2:
pair = [clean_str(replicas[0]), clean_str(replicas[1])]
if pair[0] and pair[1]:
dataset.append(pair)
X_text = []
y = []
for question, answer in dataset[:10000]:
X_text.append(question)
y += [answer]
global vectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X_text)
global clf
clf = LogisticRegression()
clf.fit(X, y)
update()
def get_generative_replica(text):
text_vector = vectorizer.transform([text]).toarray()[0]
question = clf.predict([text_vector])[0]
return question
def getwiki(s):
try:
ny = wikipedia.page(s)
wikitext=ny.content[:1000]
wikimas=wikitext.split('.')
wikimas = wikimas[:-1]
wikitext2 = ''
for x in wikimas:
if not('==' in x):
if(len((x.strip()))>3):
wikitext2=wikitext2+x+'.'
else:
break
wikitext2=re.sub('([^()]*)', '', wikitext2)
wikitext2=re.sub('([^()]*)', '', wikitext2)
wikitext2=re.sub('{[^{}]*}', '', wikitext2)
return wikitext2
except Exception as e:
return 'В энциклопедии нет информации об этом'
@bot.message_handler(commands=['start'])
def start_message(message):
bot.send_message(message.chat.id,"Здравствуйте, Сэр.")
question = ""
@bot.message_handler(content_types=['text'])
def get_text_messages(message):
command = message.text.lower()
if command =="не так":
bot.send_message(message.from_user.id, "а как?")
bot.register_next_step_handler(message, wrong)
else:
global question
question = command
reply = get_generative_replica(command)
if reply=="вики ":
bot.send_message(message.from_user.id, getwiki(command))
else:
bot.send_message(message.from_user.id, reply)
def wrong(message):
a = f"{question}{message.text.lower()} n"
with open('dialogues.txt', "a", encoding='utf-8') as f:
f.write(a)
bot.send_message(message.from_user.id, "Готово")
update()
bot.polling(none_stop=True)Надеюсь, статья Вам понравилась 